简单的super类使用
| class A(object): | |
| def __init__(self): | |
| print(self.__class__, 'A init') | |
| class B1(A): | |
| def __init__(self): | |
| # 效果等同于 super(B1, self).__init__() | |
| # 参考 class B2 | |
| super().__init__() | |
| print(self.__class__, 'B1 init') | |
| if __name__ == '__main__': | |
| print(B1.mro()) | |
| B1() |
代码运行的效果:

此时对 B1 来说,它的 mro 调用链是:B1 --> A --> object
而 super().__init__()的效果其实等同于:super(B1, self).__init__()
super 调用的等同效果
| class A(object): | |
| def __init__(self): | |
| print(self.__class__, 'A init') | |
| class B1(A): | |
| def __init__(self): | |
| # 效果等同于 super(B1, self).__init__() | |
| # 参考 class B2 | |
| super().__init__() | |
| print(self.__class__, 'B1 init') | |
| class B2(A): | |
| def __init__(self): | |
| # 等同于 super().__init__() | |
| super(B2, self).__init__() | |
| print(self.__class__, 'B2 init') | |
| class B3(A): | |
| def __init__(self): | |
| # 等同于 super().__init__() | |
| # 等同于 super(B3, self).__init__() | |
| # 这里不直接写基类 A,是因为未来继承的基类可能会变化 | |
| # super会根据 mro 自动追踪基类 | |
| A.__init__(self) | |
| print(self.__class__, 'B3 init') | |
| if __name__ == '__main__': | |
| print(B1.mro()) | |
| B1() | |
| print('-' * 16) | |
| print(B2.mro()) | |
| B2() | |
| print('-' * 16) | |
| print(B3.mro()) | |
| B3() |
B1、B2、B3三个类都继承自 A,在使用 super 时,三种写法:
super().__init__()
super(B2, self).__init__()
A.__init__(self)
效果其实是等同的:
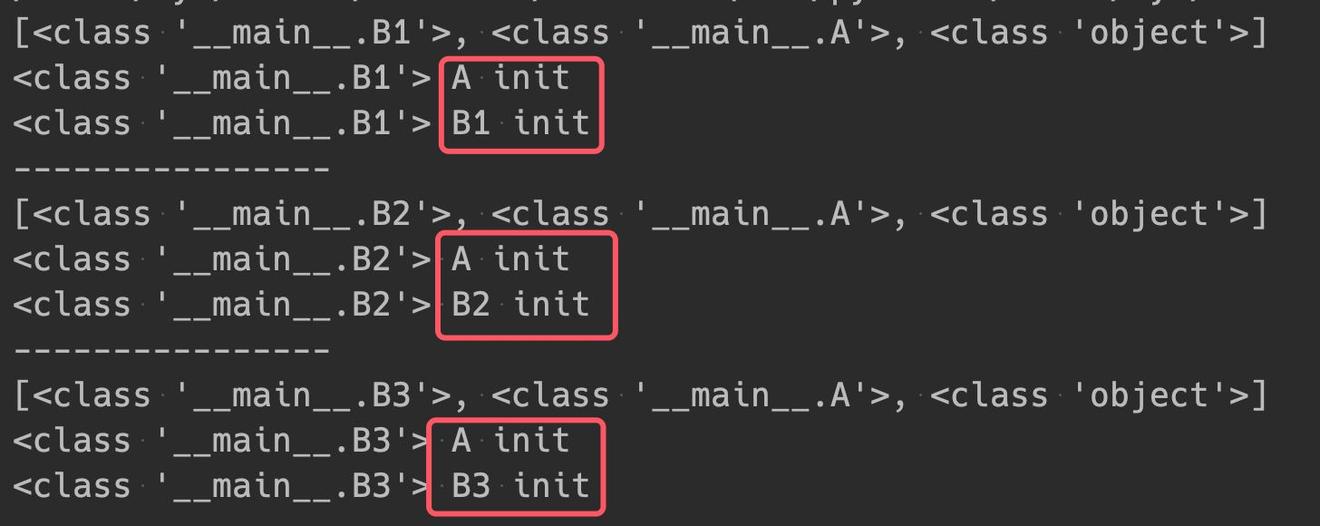
super 类中的 type 参数对 mro 链与 super 对基类的调用顺序的影响
官方说明
在官方文档https://docs.python.org/zh-cn/3/library/functions.html#super中对 super 类做了一个说明:
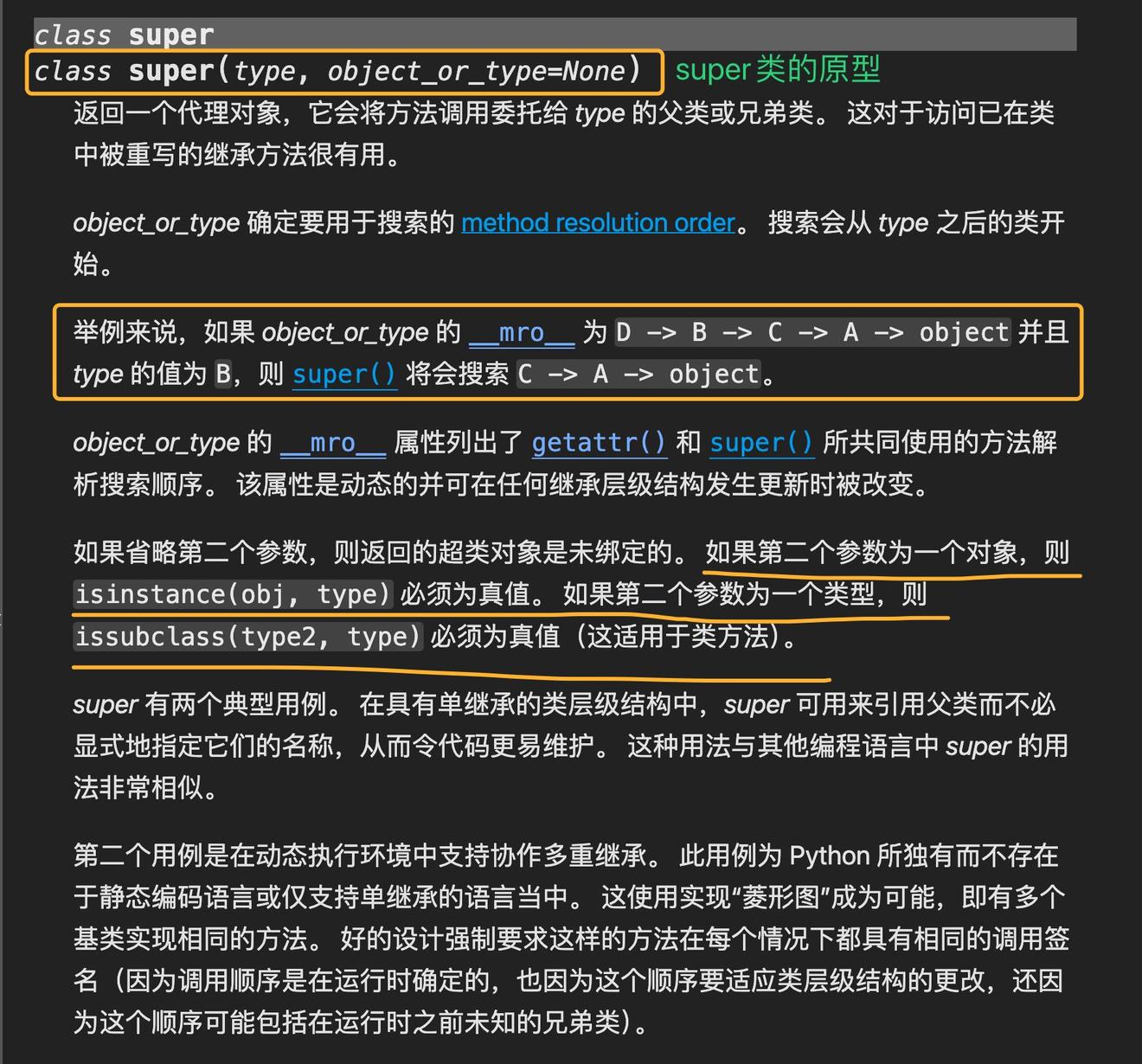
从官方文档中可以看出来,super 其实是一个类,其原型为:
class super(type, object_or_type=None)
继承链下的 mro 与 super 调用顺序
| class A(object): | |
| def __init__(self): | |
| print(self.__class__, 'A init') | |
| class B(A): | |
| def __init__(self): | |
| super().__init__() | |
| print(self.__class__, 'B init') | |
| class C1(B): | |
| def __init__(self): | |
| # super的 mro 决定了__init__()的链式调用顺序 | |
| super(C1, self).__init__() | |
| print(self.__class__, 'C1 init') | |
| class C2(B): | |
| def __init__(self): | |
| # 如果第一个参数传入的是父类型 B,那么 mro 将会首先从父类 A 开始执行 | |
| super(B, self).__init__() | |
| print(self.__class__, 'C2 init') | |
| if __name__ == '__main__': | |
| print(C1.mro()) | |
| C1() | |
| print('-' * 16) | |
| print(C2.mro()) | |
| C2() |
这段代码中:
B继承自AC1和C2均继承自B- 在
C1的__init__()中显式指定了super(C1, self).__init__(),首先执行的是B.__init__(self) - 在
C2的__init__()中显式指定了super(B, self).__init__(),首先执行的是A.__init__(self)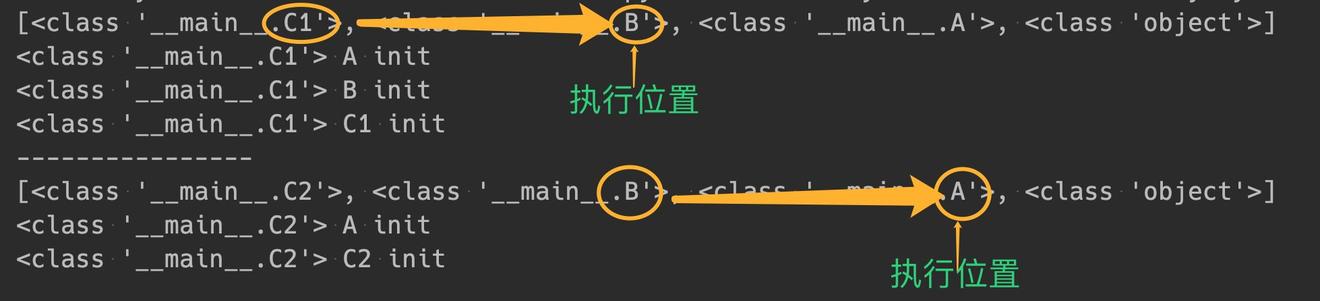
对于成员函数也遵守这一套调用顺序规则
| class A(object): | |
| def hello(self): | |
| print(self.__class__, 'A hello') | |
| class B(A): | |
| pass | |
| class C(B): | |
| def hello(self): | |
| print(self.__class__, 'C hello') | |
| class D(C): | |
| def hello1(self): | |
| super().hello() | |
| def hello2(self): | |
| super(D, self).hello() | |
| def hello3(self): | |
| super(C, self).hello() | |
| def hello4(self): | |
| super(B, self).hello() | |
| if __name__ == '__main__': | |
| print(D.mro()) | |
| print('-' * 16) | |
| d = D() | |
| d.hello() | |
| print('-' * 16) | |
| d.hello1() | |
| print('-' * 16) | |
| d.hello2() | |
| print(D.mro()) | |
| print('-' * 16) | |
| print(C.mro()) | |
| d.hello3() | |
| print('-' * 16) | |
| print(B.mro()) | |
| d.hello4() |
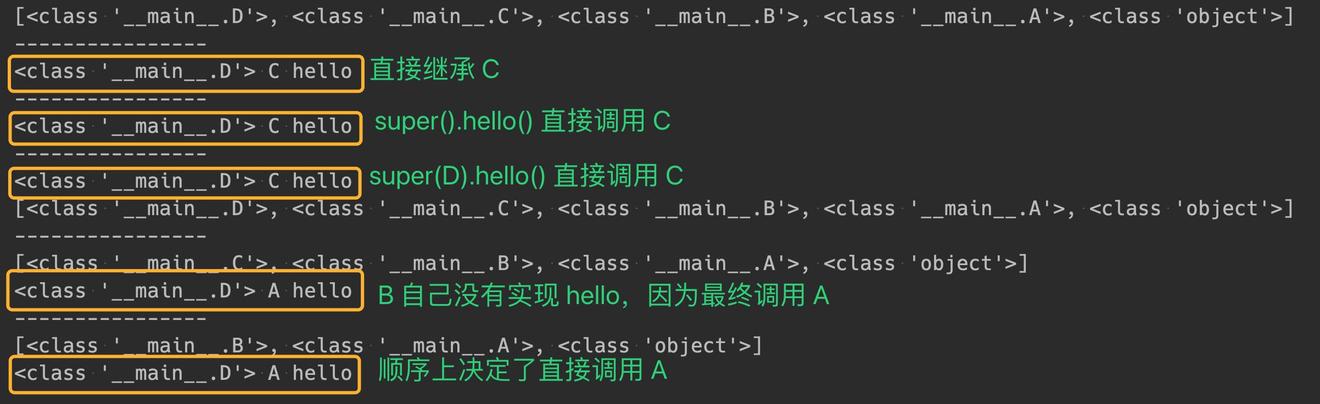
super类中的第二个参数对函数调用的影响
第二个参数作为对象传入时
| class A(object): | |
| def __init__(self, name: str): | |
| print(self.__class__, 'A hello: {}'.format(name)) | |
| class B(A): | |
| def __init__(self, name: str, greetings: str): | |
| super(B, self).__init__(name) | |
| print(self.__class__, 'B hello:{} {}'.format(name, greetings)) | |
| class C1(B): | |
| def __init__(self, name: str, greetings: str): | |
| super(B, self).__init__(name, greetings) | |
| print(self.__class__, 'C1 hello:{} {}'.format(name, greetings)) | |
| if __name__ == '__main__': | |
| print(C1.mro()) | |
| C1('C1', 'morning') |

- 上面的代码中
C1继承自B,而B继承自A A的初始化函数为:def __init__(self, name: str)C1和B的初始化函数为:def __init__(self, name: str, greetings: str),在入参上有明显区别- 在
C1的初始化函数中,显式的指定了super(B, self).__init__(name, greetings), 其中的 self 指向的是C1的实例化对象,但是在调用链上,mro 需要去寻找的基类确是A,因为此时的 mro 调用链为:[<class '__main__.C1'>, <class '__main__.B'>, <class '__main__.A'>, <class 'object'>]基类的起始位置在A - 而
A的初始化函数为:def __init__(self, name: str),只接受一个入参,因此在执行时,程序会抛出异常:TypeError: A.__init__() takes 2 positional arguments but 3 were given
指定第二个参数为第一个参数的子类对象
| class A(object): | |
| def __init__(self, name: str): | |
| print(self.__class__, 'A hello: {}'.format(name)) | |
| class B(A): | |
| def __init__(self, name: str, greetings: str): | |
| super(B, self).__init__(name) | |
| print(self.__class__, 'B hello:{} {}'.format(name, greetings)) | |
| class C1(B): | |
| def __init__(self, name: str, greetings: str): | |
| # super | |
| super(B, self).__init__(name, greetings) | |
| print(self.__class__, 'C1 hello:{} {}'.format(name, greetings)) | |
| class C2(B): | |
| def __init__(self, name: str, greetings: str): | |
| super(C2, self).__init__(name, greetings) | |
| print(self.__class__, 'C2 hello:{} {}'.format(name, greetings)) | |
| if __name__ == '__main__': | |
| print('-' * 8) | |
| print(C2.mro()) | |
| # super 也可以在函数中使用 | |
| # C2实例为 B 的子类对象 | |
| # super 第一个参数决定了从 mro 链的哪个位置开始查找 | |
| # 第二个参数决定了使用哪个对象去调用自身或基类的成员函数 | |
| # 第二个参数必须为第一个参数的类型或者子类 | |
| super(B, C2(name = 'tmp_c2', greetings = 'greet_c2')).__init__(name = 'test_A') |

指定第二个参数为第一个参数的子类类型
| class ParentA: | |
| def foo(cls): | |
| print("ParentA.foo called") | |
| class ParentB(ParentA): | |
| def foo(cls): | |
| print("ParentB.foo called") | |
| class Child(ParentB): | |
| def foo(cls): | |
| # Child 类最终调用ParentA的foo方法 | |
| super(ParentB, Child).foo() | |
| print("Child.foo called") | |
| if __name__ == '__main__': | |
| print(Child.mro()) | |
| # 调用Child的foo方法 | |
| Child.foo() |

总结
super 类的使用有以下几种常见方式:
super()不带任何参数,这种方式等同于super(type, self)super(type)只带一个类型参数,第二个参数默认为 self 所指的实例对象super(type, obj)既指定类型,又指定对象super(type, type2)第二个参数指定为类型
总的来说,Python 3 中推荐使用不传任何参数的 super() 调用方式,因为它更简洁,而且可以避免一些错误。
在多重继承的情况下,super() 函数可以确保所有父类的方法都被正确调用,遵循方法解析顺序(MRO)。