目前业界有各种各样的网络输出传输时的序列化和反序列化方案,它们在技术上的实现的初衷和背景有较大的区别,因此在设计的架构也会有很大的区别,最终在落地后的:解析速度、对系统的影响、传输数据的大小、可维护性及可阅读性等方面有着较大的区别,本文分享一些我在一些常见序列化技术的分析和理解:
文章分成3个部分:
1、列举常见的序列化和反序列化方案(ObjectXXStream、XML、JSON)
2、MySQL JDBC结果集的处理方案
3、Google Protocol Buffer处理方案
【一、常见的在API及消息通信调的用中Serialize方案】:
方案1、基于Java原生的ObjectOutputStream.write()和ObjectInputStream.read()来进行对象序列化和反序列化。
方案2、基于JSON进行序列化和反序列化。
方案3、基于XML进行序列化和反序列化。
【方案1浅析,ObjectXXXStream】:
优点:
(1)、由Java自带API序列化,简单、方便、无第三方依赖。
(2)、不用担心其中的数据解析会丢失精度、丢失字段、Object的反序列化类型不确定等问题。
缺点:
(1)、双方调试麻烦,发送方和接收方最好是同版本的对象描述,否则会有奇怪的问题,调试周期相对长,跨团队合作升级问题很多。
(2)、传递的对象中包含了元数据信息,占用空间较大。
【方案2浅析,JSON序列化】:
优点:
(1)、简单、方便,无需关注要序列化的对象格式。
(2)、开源界有较多的组件可以支持,例如FastJSON性能非常好。
(3)、在现在很多RPC的框架中,基本都支持这样的方案。
缺点:
(1)、对象属性中如果包含Object类型,在反序列化的时候如果业务也本身也不明确数据类型,处理起来会很麻烦。
(2)、由于文本类型,所以一定会占用较大的数据空间,例如下图。
(3)、比较比较依赖于JSON的解析包的兼容性和性能,在JSON的一些细节处理上(例如一些非标的JSON),各自处理方式可能不一样。
(4)、序列化无论任何数据类型先要转换为String,转成byte[],会增加内存拷贝的次数。
(5)、反序列化的时候,必须将整个JSON反序列化成对象后才能进行读取,大家应该知道,Java对象尤其是层次嵌套较多的对象,占用的内存空间将会远远大于数据本身的空间。
数据放大的极端案例1:
传递数据描述信息为:
class PP {
long userId = 102333320132133L;
int passportNumber = 123456;
}
此时传递JSON的格式为:
{
"userId":102333320132133,
"passportNumber":123456
}
我们要传递的数据是1个long、1个int,也就是12个字节的数据,这个JSON的字符串长度将是实际的字节数(不包含回车、空格,这里只是为了可读性,同时注意,这里的long在JSON里面是字符串了),这个字符串有:51个字节,也就是数据放到了4.25倍左右。
数据放大极端案例2:
当你的对象内部有数据是byte[]类型,JSON是文本格式的数据,是无法存储byte[]的,那么要序列化这样的数据,只有一个办法就是把byte转成字符,通常的做法有两种:
(1)使用BASE64编码,目前JSON中比较常用的做法。
(2)按照字节进行16进制字符编码,例如字符串:“FF”代表的是0xFF这个字节。
不论上面两种做法的那一种,1个字节都会变成2个字符来传递,也就是byte[]数据会被放大2倍以上。为什么不用ISO-8859-1的字符来编码呢?因为这样编码后,在最终序列化成网络byte[]数据后,对应的byte[]虽然没变大,但是在反序列化成文本的时候,接收方并不知道是ISO-8859-1,还会用例如GBK、UTF-8这样比较常见的字符集解析成String,才能进一步解析JSON对象,这样这个byte[]可能在编码的过程中被改变了,要处理这个问题会非常麻烦。
【方案2浅析,XML序列化】:
优点:
(1)、使用简单、方便,无需关注要序列化的对象格式
(2)、可读性较好,XML在业界比较通用,大家也习惯性在配置文件中看到XML的样子
(3)、大量RPC框架都支持,通过XML可以直接形成文档进行传阅
缺点:
(1)、在序列化和反序列化的性能上一直不是太好。
(2)、也有与JSON同样的数据类型问题,和数据放大的问题,同时数据放大的问题更为严重,同时内存拷贝次数也和JSON类型,不可避免。
XML数据放大说明:
XML的数据放大通常比JSON更为严重,以上面的JSON案例来讲,XML传递这份数据通常会这样传:
<Msg>
<userId>102333320132133</userId>
<passportNumber>123456<passportNumber>
<Msg>
这个消息就有80+以上的字节了,如果XML里面再搞一些Property属性,对象再嵌套嵌套,那么这个放大的比例有可能会达到10倍都是有可能的,因此它的放大比JSON更为严重,这也是为什么现在越来越多的API更加喜欢用JSON,而不是XML的原因。
【放大的问题是什么】:
(1)、花费更多的时间去拼接字符串和拷贝内存,占用更多的Java内存,产生更多的碎片。
(2)、产生的JSON对象要转为byte[]需要先转成String文本再进行byte[]编码,因为这本身是文本协议,那么自然再多一次内存全量的拷贝。
(3)、传输过程由于数据被放大,占用更大的网络流量。
(4)、由于网络的package变多了,所以TCP的ACK也会变多,自然系统也会更大,同等丢包率的情况下丢包数量会增加,整体传输时间会更长,如果这个数据传送的网络延迟很大且丢包率很高,我们要尽量降低大小;压缩是一条途径,但是压缩会带来巨大的CPU负载提高,在压缩前尽量降低数据的放大是我们所期望的,然后传送数据时根据RT和数据大小再判定是否压缩,有必要的时候,压缩前如果数据过大还可以进行部分采样数据压缩测试压缩率。
(5)、接收方要处理数据也会花费更多的时间来处理。
(6)、由于是文本协议,在处理过程中会增加开销,例如数字转字符串,字符串转数字;byte[]转字符串,字符串转byte[]都会增加额外的内存和计算开销。
不过由于在平时大量的应用程序中,这个开销相对业务逻辑来讲简直微不足道,所以优化方面,这并不是我们关注的重点,但面临一些特定的数据处理较多的场景,即核心业务在数据序列化和反序列化的时候,就要考虑这个问题了,那么下面我继续讨论问题。
此时提出点问题:
(1)、网络传递是不是有更好的方案,如果有,为什么现在没有大面积采用?
(2)、相对底层的数据通信,例如JDBC是如何做的,如果它像上面3种方案传递结果集,会怎么样?
【二、MySQL JDBC数据传递方案】:
在前文中提到数据在序列化过程被放大数倍的问题,我们是否想看看一些相对底层的通信是否也是如此呢?那么我们以MySQL JDBC为例子来看看它与JDBC之间进行通信是否也是如此。
JDBC驱动程序根据数据库不同有很多实现,每一种数据库实现细节上都有巨大的区别,本文以MySQL JDBC的数据解析为例(MySQL 8.0以前),给大家说明它是如何传递数据的,而传递数据的过程中,相信大家最为关注的就是ResultSet的数据是如何传递的。
抛开结果集中的MetaData等基本信息,单看数据本身:
(1)JDBC会读取数据行的时候,首先会从缓冲区读取一个row packege,row package就是从网络package中拿到的,根据协议中传递过来的package的头部判定package大小,然后从网络缓冲中读取对应大小的内容,下图想表达网络传递的package和业务数据中的package之间可能并不是完全对应的。另外,网络中的package如果都到了本地缓冲区,逻辑上讲它们是连续的(图中故意分开是让大家了解到网络中传递是分不同的package传递到本地的),JDBC从本地buffer读取row package这个过程就是内核package到JVM的package拷贝过程,对于我们Java来讲,我们主要关注row package(JDBC中可能存在一些特殊情况读取过来的package并不是行级别的,这种特殊情况请有兴趣的同学自行查阅源码)。

(2)、单行数据除头部外,就是body了,body部分包含各种各样不同的数据类型,此时在body上放数据类型显然是占空间的,所以数据类型是从metadata中提取的,body中数据列的顺序将会和metdata中的列的顺序保持一致。
(3)、MySQL详细解析数据类型:
3.1、如果Metadata对应数据发现是int、longint、tinyint、year、float、double等数据类型会按照定长字节数读取,例如int自然按照4字节读取,long会按照8字节读取。
3.2、如果发现是其它的类型,例如varchar、binary、text等等会按照变长读取。
3.3、变长字符串首先读取1个字节标志位。
3.4、如果这个标志位的值小于等于250,则直接代表后续字节的长度(注意字符串在这里是算转换为字节的长度),这样确保大部分业务中存放的变长字符串,在网络传递过程中只需要1个字节的放大。
3.5、如果这个标志位是:251,代表这个字段为NULL
3.6、如果标志位是:252,代表需要2个字节代表字段的长度,此时加上标志位就是3个字节,在65536以内的长度的数据(64KB),注意,这里会在转成long的时候高位补0,所以2个字节可以填满到65536,只需要放大3个字节来表示这个数据。
3.7、如果标志位是:253,代表需要4个自己大表字段的长度,可以表示4GB(同上高位补0),这样的数据几乎不会出现在数据库里面,即使出现,只会出现5个字节的放大。
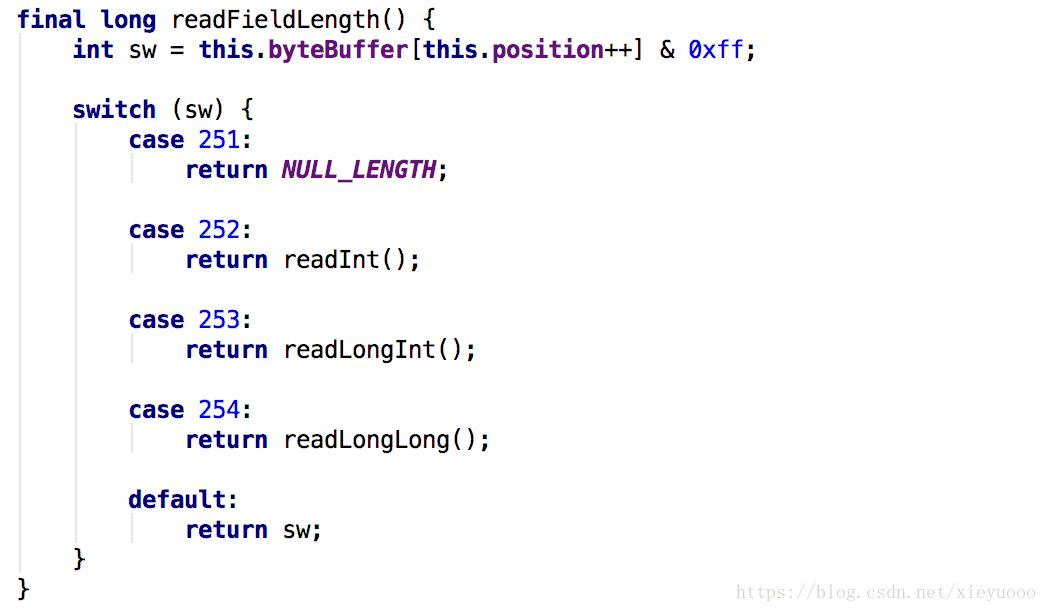
3.8、如果标志位是:254,8个字节代表长度,此时没有高位补0,最多可以读取Long.MAX_VALUE的长度,但是这个空间目前不可能有内存放得下,所以无需担心使用问题,此时9个字节的放大,源码如下图:
(4)、我们先按照这个理解,MySQL在传递数据的过程中,对数据的放大是很小很小的,是不是真的这样呢?请下面第5点说明。
补充说明:
a、在MySQL JDBC中对于ResultSetRow数据的解析(除对MySQL 8.0以上JDBC版本)有2个实现类:BufferRow、ByteArrayRow,这两种方式在读取单行数据在解析这个阶段是一样的逻辑,只不过解析存放数据的方式有所不同,BufferRow一个会解析成数据行的byte[],ByteArrayRow会解析成byte[][]二维数组,第二维就是每1个列的信息,这都是客户端行为,与网络传递数据的格式无关。(两者在不同场景下使用,例如其中一种场景是:ByteArrayRow在游标开启UPDATE模式的时候会启用,但这不是本文的重点,这里提到主要告知大家,无论哪一种方式,读取数据的方式是一致的)
b、在MySQL JDBC中的RowData是ResultSet里面数据处理的入口,其实现类有3个:RowStatStatic、RowDataCursor、RowDataDynamic,这虽然有3个实现类,但是同样不会影响数据的格式,它们只是从缓冲区读取数据的方式有所不同:RowStatStatic、RowDataCursor会每次将缓冲区的数据全部读取到JDBC当中形成数组,RowDataCursor在处理上有一个区别在于数据库每次返回的是FetchSize大小的数据内容(实现的细节在上一篇文章中有提到);RowDataDynamic是需要行的时候再从pakcege中去读,package读取完成后就尝试读取下一个package。这些都不会影响数据本身在网络上的传递格式,所以文本提到的解析是目前MySQL JDBC比较通用的解析,与它内部的执行路径无关。
(5)、以BufferRow为例,当你发起getString('xxx')、getDate(int)的时候,首先它需要在内部找到是第几个列(传数字省略该动作),然后其内部会有一个lastRequestedIndex、lastRequestedPos分别记录最后读取的第几个字段和所在字节的位置,如果你传入的index比这个index大,则从当前位置开始,向后扫描,扫描规则和上面的数据库宽度一致,找到对应位置,拷贝出对应的byte[]数组,转换你要的对象类型。
PS:lastRequestedIndex、lastRequestedPos这种其实就是JDBC认为你绝大部分情况是从前向后读取的,因此这样读取对JDBC程序也是最友好的方案,否则指针向前移动,需要从0开始,理由很简单(数据的长度不是在尾部,而是在头部),因此指针来回来回移动的时候,这样会产生很多开销,同时会产生更多的内存拷贝出来的碎片。ByteArrayRow虽然可以解决这个问题,但是其本身会占用相对较大的空间另外,其内部的二维数组返回的byte[]字节是可以被外部所修改的(因为没有拷贝)。
另外,按照这种读取数据的方式,如果单行数据过大(例如有大字段100MB+),读取到Java内存里面来,即使使用CursorFetch和Stream读取,读取几十条数据,就能把JVM内存干挂掉。到目前为止,我还没看到MySQL里面可以“设置限制单行数据长度”的参数,后续估计官方支持这类特殊需求的可能性很小,大多也只能自己改源码来实现。
【回到话题本身:MySQL和JDBC之间的通信似乎放大很小?】
其实不然,MySQL传递数据给JDBC默认是走文本协议的,而不是Binary协议,虽然说它的byte[]数组不会像JSON那样放大,并不算真正意义上的文本协议,但是它很多种数据类型默认情况下,都是文本传输,例如一个上面提到的账号:102333320132133在数据库中是8个自己,但是网络传递的时候如果有文本格式传递将会是:15个字节,如果是DateTime数据在数据库中可以用8个字节存放,但是网络传递如果按照YYYY-MM-DD HH:MI:SS传递,可以达到19个字节,而当他们用String在网络传递的时候,按照我们前面提到的,MySQL会将其当成变长字符,因此会在数据头部加上最少1个自己的标志位。另外,这里增加不仅仅是几个字节,而是你要取到真正的数据,接收方还需要进一步计算处理才能得到,例如102333320132133用文本传送后,接收方是需要将这个字符串转换为long类型才能可以得到long的,大家试想一下你处理500万数据,每一行数据有20个列,有大量的类似的处理不是开销增加了特别多呢?
JDBC和MySQL之间可以通过binary协议来进行通信的,也就是按照实际数字占用的空间大小来进行通信,但是比较坑的时,MySQL目前开启Binary协议的方案是:“开启服务端prepareStatemet”,这个一旦开启,会有一大堆的坑出来,尤其是在互联网的编程中,我会在后续的文章中逐步阐述。
抛开“开启binary协议的坑”,我们认为MySQL JDBC在通信的过程中对数据的编码还是很不错的,非常紧凑的编码(当然,如果你开启了SSL访问,那么数据又会被放大,而且加密后的数据基本很难压缩)。
对比传统的数据序列化优劣势汇总:
优势:
(1)、数据全部按照byte[]编码后,由于紧凑编码,所以对数据本身的放大很小。
(2)、由于编码和解码都没有解析的过程,都是向ByteBuffer的尾部顺序地写,也就是说不用找位置,读取的时候根据设计也可以减少找位置,即使找位置也是移动偏移量,非常高效。
(3)、如果传递多行数据,反序列化的过程不用像XML或JSON那样一次要将整个传递过来的数据全部解析后再处理,试想一下,如果5000行、20列的结果集,会产生多少Java对象,每一个Java对象对数据本身的放大又是多少,采用字节传递后可以按需转变为Java对象,使用完的Java对象可以释放,这样就不用同时占用那样大的JVM内存,而byte[]数组也只是数据本身的大小,也可以按需释放。
(4)、相对前面提到的3种方式,例如JSON,它不需要在序列化和反序列化的时候要经历一次String的转换,这样会减少一次内存拷贝。
(5)、自己写代码用类似的通信方案,可以在网络优化上做到极致。
劣势:
(1)、编码是MySQL和MySQL JDBC之间自定义的,别人没法用(我们可以参考别人的思路)
(2)、byte编码和解码过程程序员自己写,对程序员水平和严谨性要求都很高,前期需要大量的测试,后期在网络问题上考虑稍有偏差就可能出现不可预期的Bug。(所以在公司内部需要把这些内容进行封装,大部分程序员无需关注这个内容)。
(3)、从内存拷贝上来讲,从rowBuffer到应用中的数据,这一层内存拷贝是无法避免的,如果你写自定义程序,在必要的条件下,这个地方可以进一步减少内存拷贝,但无法杜绝;同上文中提到,这点开销,对于整个应用程序的业务处理来讲,简直微不足道。
为什么传统通信协议不选择这样做:
(1)、参考劣势中的3点。
(2)、传统API通信,我们更讲究快速、通用,也就是会经常和不同团队乃至不同公司调试代码,要设计binary协议,开发成本和调试成本非常高。
(3)、可读性,对于业务代码来讲,byte[]的可读性较差,尤其是对象嵌套的时候,byte[]表达的方式是很复杂的。
MySQL JDBC如果用binary协议后,数据的紧凑性是不是达到极致了呢?
按照一般的理解,就是达到极致了,所有数据都不会进一步放大,int就只用4个字节传递,long就只用8个字节传递,那么还能继续变小,难道压缩来做?
非也、非也,在二进制的世界里,如果你探究细节,还有更多比较神奇的东西,下面我们来探讨一下:
例如:
long id = 1L;
此时网络传递的时候会使用8个字节来方,大家可以看下8个字节的排布:

我们先不考虑按照bit有31个bit是0,先按照字节来看有7个0,代表字节没有数据,只有1个字节是有值的,大家可以去看一下自己的数据库中大量的自动增长列,在id小于4194303之前,前面5个字节是浪费掉的,在增长到4个字节(2的32次方-1)之前前面4个自己都是0,浪费掉的。另外,即使8个字节中的第一个字节开始使用,也会有大量的数据,中间字节是为:0的概率极高,就像十进制中进入1亿,那么1亿下面最多会有8个0,越高位的0约难补充上去。
如果真的想去尝试,可以用这个办法:用1个字节来做标志,但会占用一定的计算开销,所以是否为了这个空间去做这个事情,由你决定,本文仅仅是技术性探讨:
方法1:表达目前有几个低位被使用的字节数,由于long只有8个字节,所以用3个bit就够了,另外5个bit是浪费掉的,也无所谓了,反序列化的时候按照高位数量补充0x00即可。
方法2:相对方法1,更彻底,但处理起来更复杂,用1这个字节的8个bit的0、1分别代表long的8个字节是被使用,序列化和反序列化过程根据标志位和数据本身进行字节补0x00操作,补充完整8个字节就是long的值了,最坏情况是9个字节代表long,最佳情况0是1个字节,字节中只占用了2个字节的时候,即使数据变得相当大,也会有大量的数据的字节存在空位的情况,在这些情况下,就通常可以用少于8个字节的情况来表达,要用满7个字节才能够与原数字long的占用空间一样,此时的数据已经是比2的48次方-1更大的数据了。
【三、Google Protocol Buffer技术方案】:
这个对于很多人来讲未必用过,也不知道它是用来干什么的,不过我不得不说,它是目前数据序列化和反序列化的一个神器,这个东西是在谷歌内部为了约定好自己内部的数据通信设计出来的,大家都知道谷歌的全球网络非常牛逼,那么自然在数据传输方面做得那是相当极致,在这里我会讲解下它的原理,就本身其使用请大家查阅其它人的博客,本文篇幅所限没法step by step进行讲解。
看到这个名字,应该知道是协议Buffer,或者是协议编码,其目的和上文中提到的用JSON、XML用来进行RPC调用类似,就是系统之间传递消息或调用API。但是谷歌一方面为了达到类似于XML、JSON的可读性和跨语言的通用性,另一方面又希望达到较高的序列化和反序列化性能,数据放大能够进行控制,所以它又希望有一种比底层编码更容易使用,而又可以使用底层编码的方式,又具备文档的可读性能力。
它首先需要定义一个格式文件,如下:
syntax = "proto2";
package com.xxx.proto.buffer.test;
message TestData2 {
optional int32 id = 2;
optional int64 longId = 1;
optional bool boolValue = 3;
optional string name = 4;
optional bytes bytesValue = 5;
optional int32 id2 = 6;
}
这个文件不是Java文件,也不是C文件,和语言无关,通常把它的后缀命名为proto(文件中1、2、3数字代表序列化的顺序,反序列化也会按照这个顺序来做),然后本地安装了protobuf后(不同OS安装方式不同,在官方有下载和说明),会产生一个protoc运行文件,将其加入环境变量后,运行命令指定一个目标目录:
protoc --java_out=~/temp/ TestData2.proto
此时会在指定的目录下,产生package所描述的目录,在其目录内部有1个Java源文件(其它语言的会产生其它语言),这部分代码是谷歌帮你生成的,你自己写的话太费劲,所以谷歌就帮你干了;本地的Java project里面要引入protobuf包,maven引用(版本自行选择):
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.6.1</version>
</dependency>
此时生成的代码会调用这个谷歌包里面提供的方法库来做序列化动作,我们的代码只需要调用生成的这个类里面的API就可以做序列化和反序列化操作了,将这些生成的文件放在一个模块里面发布到maven仓库别人就可以引用了,关于测试代码本身,大家可以参考目前有很多博客有提供测试代码,还是很好用的。
谷歌编码比较神奇的是,你可以按照对象的方式定义传输数据的格式,可读性极高,甚至于相对XML和JSON更适合程序员阅读,也可以作为交流文档,不同语言都通用,定义的对象还是可以嵌套的,但是它序列化出来的字节比原始数据只大一点点,这尼玛太厉害了吧。
经过测试不同的数据类型,故意制造数据嵌套的层数,进行二进制数组多层嵌套,发现其数据放大的比例非常非常小,几乎可以等价于二进制传输,于是我把序列化后的数据其二进制进行了输出,发现其编码方式非常接近于上面的JDBC,虽然有一些细节上的区别,但是非常接近,除此之外,它在序列化的时候有几大特征:
(1)、如果字段为空,它不会产生任何字节,如果整合对象的属性都为null,产生的字节将是0
(2)、对int32、int64这些数据采用了变长编码,其思路和我们上面描述有一些共通之处,就是一个int64值在比较小的时候用比较少的字节就可以表达了,其内部有一套字节的移位和异或算法来处理这个事情。
(3)、它对字符串、byte[]没有做任何转换,直接放入字节数组,和二进制编码是差不多的道理。
(4)、由于字段为空它都可以不做任何字节,它的做法是有数据的地方会有一个位置编码信息,大家可以尝试通过调整数字顺序看看生成出来的byte是否会发生改变;那么此时它就有了很强兼容性,也就是普通的加字段是没问题的,这个对于普通的二进制编码来讲很难做到。
(5)、序列化过程没有产生metadata信息,也就是它不会把对象的结构写在字节里面,而是反序列化的接收方有同一个对象,就可以反解析出来了。
这与我自己写编码有何区别?
(1)、自己写编码有很多不确定性,写不好的话,数据可能放得更大,也容易出错。
(2)、google的工程师把内部规范后,谷歌开源的产品也大量使用这样的通信协议,越来越多的业界中间件产品开始使用该方案,就连MySQL数据库最新版本在数据传输方面也会开始兼容protobuf。
(3)、谷歌相当于开始在定义一个业界的新的数据传输方案,即有性能又降低代码研发的难度,也有跨语言访问的能力,所以才会有越来越多的人喜欢使用这个东西。
那么它有什么缺点呢?还真不多,它基本兼顾了很多序列化和反序列化中你需要考虑的所有的事情,达到了一种非常良好的平衡,但是硬要挑缺陷,我们就得找场景才行:
(1)、protobuf需要双方明确数据类型,且定义的文件中每一个对象要明确数据类型,对于Object类型的表达没有方案,你自己必须提前预知这个Object到底是什么类型。
(2)、使用repeated可以表达数组,但是只能表达相同类型的数据,例如上面提到的JDBC一行数据的多个列数据类型不同的时候,要用这个表达,会比较麻烦;另外,默认情况下数组只能表达1维数组,要表达二维数组,需要使用对象嵌套来间接完成。
(3)、它提供的数据类型都是基本数据类型,如果不是普通类型,要自己想办法转换为普通类型进行传输,例如从MongoDB查处一个Docment对象,这个对象序列化是需要自己先通过别的方式转换为byte[]或String放进去的,而相对XML、JSON普通是提供了递归的功能,但是如果protobuf要提供这个功能,必然会面临数据放大的问题,通用和性能永远是矛盾的。
(4)、相对于自定义byte的话,序列化和反序列化是一次性完成,不能逐步完成,这样如果传递数组嵌套,在反序列化的时候会产生大量的Java对象,另外自定义byte的话可以进一步减少内存拷贝,不过谷歌这个相对文本协议来讲内存拷贝已经少很多了。
补充说明:
在第2点中提到repeated表达的数组,每一个元素必须是同类型的,无法直接表达不同类型的元素,因为它没有像Java那样Object[]这样的数组,这样它即使通过本地判定Object的类型传递了,反序列化会很麻烦,因为接收方也不知道数据是什么类型,而protobuf网络传递数据是没有metadata传递的,那么判定唯一的地方就是在客户端自己根据业务需要进行传递。
因此,如果真的有必要的话,可以用List<byte[]>表达一行数据的方案,也就是里面的每1个byte[]元素通过其它地方获得metadata,例如数据库的Metadata得到,然后再自己去转换,但是传递过程全是byte[];就JDBC来讲,我个人更加推荐于一行数据使用一个byte[]来传递,而不是每一项数据用一个byte[],因为在序列化和反序列化过程中,每一个数组元素都会在protobuf会被包装成对象,此时产生的Java对象数量是列的倍数,例如有40个列,会产生40倍的Java对象,很夸张吧。
总之,每一种序列化和反序列化方案目前都有应用场景,它们在设计之初决定了架构,也将决定了最终的性能、稳定性、系统开销、网络传输大小等等。
作者:钟隐