Class类文件结构
字节码解析
java 的 Class 文件是以8字节为基础的二进制流存储,数据项之间没有分割符,当遇到超过8字节的数据项时,按高位在前的顺序切分成多个8字节进行存储,每个位置代表的含义都有明确的规定,8字节对齐市为了提高内存寻址效率
从《虚拟机规范》中规定class文件中使用无符号数和表两种数据类型存储数据, jvm 解析字节码都是以这两种类型为基础,类的文件格式严格按照class文件格式存储,如果把字节码文件比作一篇文章,那么class文件格式规范就是一本新华字典,只要按照新华字典进行查找,就能知道文章中每一个字的含义,详情见描述符表
无符号数包含u1、u2、u4、u8,分别代表1、2、4、8个字节,表包含无符号数和表
名词解析,全限定名,如类的全限定名,包名+类名;简单名称,如int()方法的简单名称就是int;描述符,如方法和字段的描述符,描述字段的数据类型、方法参数列表(数量、类型、数量)、返回值

命令xxd .class文件输出十六进制

1 魔数 (magic)
长度占1个u4,魔数是 虚拟机 用来确认是否接收该Class文件的唯一标识
2次版本(minor_version)
长度占1个u2,代表java的次版本号, Jdk 1.2 – jdk12不再使用,全用0000表示,
jdk12以后加入的新特性但并未加入到公测版本,则用65535标识
3主版本(major_version)
长度占一个u2,代表java的主版本号,java的版本号从45开始,每增加一个大版本+1,这里需要将16进制转换为十进制才是对应的java版本,34的10进制表现形式为52,52代表的是可以被jdk8及以上的版本执行,因为 jdk 执行class文件是向下兼容的,class文件版本号与jdk版本对应关系可自行查看
4常量池容量(constant_poor_count)
长度占一个u2,常量池索引从1开始,0代表数据不指向常量池中任何一个项目
5常量池(constant_pool)
长度占constant_poor_count-1,常量池每一项数据都是一个表,根据常量池类型表以及每个类型对应的表逐级查询即可翻译出每个字节码的含义,详情见常量池类型表+常量池类型结构表,常量池存放到内容主要有两种,字面量和符号引用
1. 字面量,包含文本字符串,final修饰的常量值等
2. 符号引用,包含package、类和接口等全限定名、字段的名称和描述符、方法的名称和描述符、方法句柄和方法类型、动态调用点和动态常量
6访问标志(access_flag)
长度占一个u2,识别类或接口的层次访问信息,详情见访问标志表
7类索引(this_class)、8父类索引(super_class)
类索引和父类索引长度都是占一个u2,接口索引结合占一组u2集合,类索引确定类的全限定名,父类索引确定父类的全限定名,各自指向常量池表中的标志位1(字符串)
9接口索引集合数量(interfaces_count)、10接口索引集合(interfaces)
接口索引集合数量长度占一个u2,代表继承接口的数量,如果数量为0,接口索引集合不占字节
接口索引集合长度占interfaces_count,描述类实现了哪些接口,除了java.lang.Object之外,其他所有类的父类索引都不为0
11字段表个数(fields_count)12字段表集合(fields)
字段个数长度占一个u2,接口或者类中声明的变量的数量,不包含方法级别的局部变量
字段表集合长度占fields_count,代表接口或者类中声明的变量表集合,详情见字段表
13方法表个数(methods_count)14方法表集合(methods)
方法个数长度占一个u2,接口或者类中声明的方法的数量
方法表集合长度占methods _count,代表接口或者类中声明的方法,详情见方法表
方法里的代码经过jvm编译后会翻译成字节码指令,存放在方法属性表的code属性里
15属性表个数(methods_count)16属性表集合(methods)
class文件、字段表、方法表中包含属性表
属性表个数长度占1个u2,属性表个数
属性表集合每一个属性长度占一个u4
字节码指令
Java方法体的代码编译后,最终会编译成字节码指令存储在class文件中的attribute_info的code属性中,code属性出现在方法表的属性集合中,所有的计算,赋值,方法调用都是基于操作数栈的,接口或抽象类的方法不存在code属性,可以理解为code属性描述的是代码,其他描述的是class的元数据
编译期确定了操作数栈的深度(max_stack),根据jvm编译后的code属性中的指令,统计入栈数,以最大的入栈数为准
编译期确定了 局部变量 表的存储空间(max_locals),局部变量表以slot为单位,slot可复用,jvm根据同时生存的最大局部变量个数确定局部变量表空间大小,因为不同局部变量的作用域,slort可以复用,减少内存使用空间
Slort是虚拟机为局部变量分配内存的最小单位,每个slort占4个字节,byte、char、 short 、int、 float 、boolean、returnAddress这几个类型的局部变量占一个slort,long和double占2个slort
opencode指令模版中指令类型为T,如果指令模版与数据类型共同确定为空,则虚拟机指令不支持此数据类型,类似byte、short、char、boolean,大多数指令都不支持,为什么可以虚拟机可以操作这两种类型数据呢?因为jvm在编译期,将byte和short类型数据扩展为int类型数据,后面操作都是使用的int类型指令
代码实战
定义一个类ClassFileByte.java,通过IDEAL编译这个类,通过xxd ClassFileByte.class以16进制的形式查看此文件,对照class文件结构规范表对这个类进行解析,得出字节码代表的每个数据项的表现形式,最后通过javap – verbose ClassFileByte反编译字节码与我们解析的结果进行比对,如果一致则解析成功
解析前请准备好class文件格式表以及常量池类型表、常量池每个类型表、进制转换工具、ASCII码对照表(解析字符串)

过xxd ClassFileByte.class,使用16进制查看字节码文件


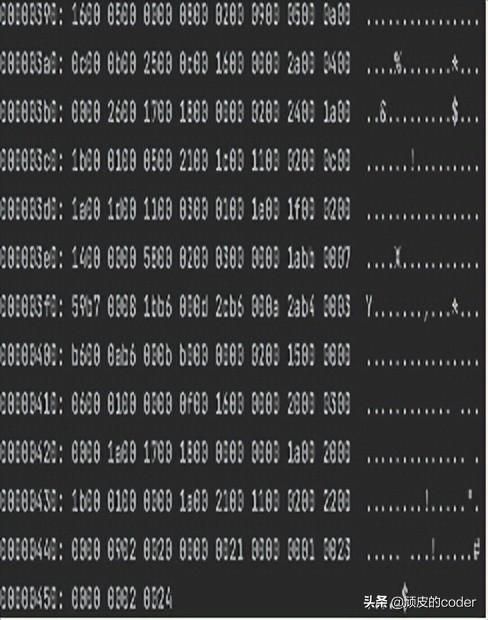
开始解析,所有字节码都是连续的,并严格按照规范的所以按顺序解析,解析时需要转换成10进制去规范表查询,为方便解释解析过程,列出用到的常量池类型及类型表
常量池类型表:tag(u1)+ 表
1 -> utf_8_info,tag(u1)+length(u2)+ bytes(elngth)
7 -> class_info,tag(u1)+name_index(u2)
8 -> string_info = tag(u1)+ index(u2)
9 -> fieldref_info,tag(u1)+index(u2)+ index(u2)
10 -> method_ref_info = tag(u1)+index(u2)+index(u2)
cafe babe:魔数
0000:无次版本号,次版本号
0034:52,jdk主版本号,34转10进制是52,查看class文件版本号表,52对应的是jdk1.8
0040:39,量池中的常量个数,角标从1开始,那么就是39->63个常量
#1:#15.#37; 0a00 0f00 25,0a-> method_ref_info, 0f->#15, 25->#37
#2:#38; 08 0026, 08->string_info, 26->#38
#3:#14.#39; 0900 0e00 27,09->fieldref_info, 0e->#14,27->#39
#4:#40; 08 0028, 08->string_info, 28->#40
#5:#14.#41; 0a00 0e00 29,0a->method_ref_info, 0e->#14,29->#41
#6:#42.#43; 09 002a 002b,09->fieldref_info, 2a->#42,2b->#43
#7:#44; 0700 2c, 07->class_info, 2c->#44
#8:#7.#37; 0a 0007 0025,0a->method_ref_info, 07->#7,25->#37
#9:#45; 0800 2d, 08->string_info, 2d->#45
#10:#7.#46; 0a 0007 002e,0a->method_ref_info, 07->#7,2e->#46
#11:#7.#47; 0a00 0700 2f,0a->method_ref_info, 07->#7,2f->#47
#12:#48.#49; 0a 0030 0031,0a->method_ref_info, 30->#48,31->#49
#13:#7.#50; 0a00 0700 32,0a->method_ref_info, 07->#7,32->#50
#14:#51; 0700 33, 07->class_info, 32->#51
#15:#52; 0700 34, 07->class_info, 32->#52
#16:one; 01 0003 6f6e 65, 01-> utf_8_info, 6f6e65->one( ASCII 码转换)
… … 太多了,后续就不手动计算了,解析方法相同,先通过标志位找到表,再通过表每个位置的字节码代表的含义进行转换即可
通过javap – verbose ClassFileByte反编译,与我们解析的结果进行比对,完全一致

总结
通过理解类文件结构,问自己几个问题,看是否能回答上来,编译一个class文件,是否能通过字节码反编译?
1. 描述一下类文件结构?如何反编译字节码文件?
Jdk中的javac将Java文件编译成class字节码文件,字节码文件中的字节码顺序、个数都是严格按照类文件格式规范,字节码文件有2种类型,无符号数和表,无符号数包含u1、u2、u4、u8,各代别1248个字节,表是由无符号数和表构成
字节码文件格式由魔数、次版本号、主版本号、常量池计数器、常量池、访问标识、
当前类表,父类表计数器(值为1)、父类表、接口表计数器、接口表集合、字段计数器、字段表集合、方法表计数器、方法表集合、属性表计数器、属性表集合
值得一提的是code属性只在方法表中存在,code属性记录了方法体内的代码转换成的字节码指令,这些指令都是基于操作数栈的,操作数栈的深度和局部变量表的大小在编译期就确定了,操作数栈的深度计算方式为最大同时入栈数,局部变量表的大小不是按局部变量的个数定义的,是按照不同作用域最大局部变量个数确定,不同作用域变量槽(slot)可以复用,局部变量表的存储单位为占4个字节的变量槽(slot),变量槽中存储的是基本数据类型数值和符号引用,如byte、short、char、int、float、boolean、return Address,占一个slot,double和long占2个slot
局部变量的计算和赋值都是在操作数栈中完成的,如int a=1,是先将1压入栈顶,再将1出栈赋值给a
2. 描述一下常量池?
常量池保存的是字面量和符号引用, 字面量 指final修饰的变量和字符串,符号引用指的的类、接口的全限定名,字段、方法的简单名称和描述符号
常量池由17种类型,每种类型都对应了一张表,字节码中存储的常量也是严格按照常量池类型和常量池类型表按顺序存储的
3. 描述一下字节码指令?
字节码文件中的指令是在jdk在编译期将方法体中的代码编译为字节码指令,保存在方法表中的code属性,这些指令都是在操作数栈中执行的