目录
- 背景
- 特别说明
- 前置知识
- 总览
- 编解码
- BulkOperation
- BulkOperationPacked
- 成员变量
- 构造器
- 编码
- 解码
- BulkOperationPacked*
- 应用
- PackedWriter
- 分段处理
- AbstractBlockPackedWriter
- BlockPackedWriter
- MonotonicBlockPackedWriter
- DirectWriter
- DirectMonotonicWriter
- 总结
背景
在Lucene中,涉及到索引文件生成的时候,会看到比较多的PackedInts.Encoder,PackedWriter,DirectWriter,DirectMonotonicWriter等等对多个long进行压缩编码解码的使用,但是它们之间有什么区别和联系呢?本文就是详细介绍说明Lucene中对正整数(int或者long)数组的压缩编码解码方式。
虽然限制了只对正整数有用,但是其他数值可以通过一些转化,先转成正整数,然后再使用本文介绍的压缩编码。比如,负整数可以通过zigzag先做一次编码,float或者double可以通过把二进制按int或者long来解析进行预处理。
特别说明
本文中说到的压缩,压缩编码器,编码器指的都是同一个东西。另外,本文相关的源码主要都是在进行一些位运算,我会有注释,但是如果实在看不太懂的话,可以自己举例子走一遍源码就清楚了。
本文的重点还是压缩编码的思想,以及几个工具类的不同使用场景的理解。
前置知识
在单值压缩中,我们已经说过了,压缩其实就是去除无用的信息,而对于数值来说,高位的连续0其实就是无用的信息。
假设有long数组中的值为:
long[] values = {, 4, 9, 16, 132};
它们的十进制和二进制分别是:
十进制 | 二进制 |
10 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00001010 |
4 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000100 |
9 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00001001 |
16 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00010000 |
580 | 00000000 00000000 00000000 00000000 00000000 00000000 00000010 01000100 |
如果按照正常的二进制编码存储,一个long需要64bits,则values数组需要5*64=320bits。但是我们观察所有value的二进制,发现最大的580也只有最后10bits是有效的,因此,我们可以用10bits表示每一个value,这样一共只需要50bits就能完成对values数组的存储,如下表所示:
十进制 | 压缩编码 |
10 | 00 00001010 |
4 | 00 00000100 |
9 | 00 00001001 |
16 | 00 00010000 |
580 | 10 10000100 |
所以,所谓的压缩编码其实就是只保留value的有效位。接下来先介绍两个很重要的概念:
- bitsPerValue:要压缩编码的整数数组中,最大的值的二进制有效位数,如上面例子中的就是10。
- block:把用来存储压缩编码后的value的空间分成一个个block,block大小一般是long或者byte。
Lucene中根据一个value编码压缩之后的存储是否跨越多个block,分为两类压缩编解码。下面我们以上面的例子来介绍这两种编解码的区别。
假设我们block的大小是int,也就是一个block是32位。在上面的例子中,每个value需要10bits存储空间,所以一个int中能完整存储3个value之后,还剩下2bits,两个编码的区别就是是否要使用这2bits,具体结果如下图所示:
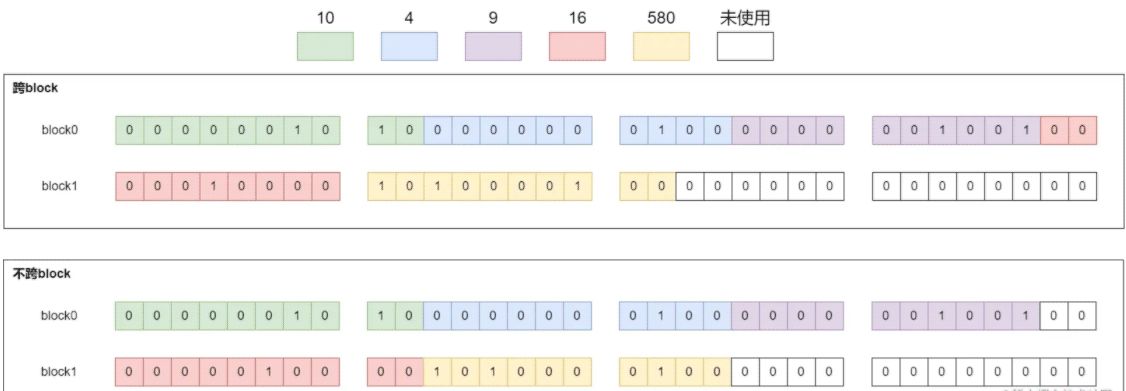
从上面的例子中,我们总结下两种编码的特点:
单个value跨block(BulkOperationPacked和BulkOperationPacked*,*是从1-24。)
- 除了最后一个block,没有浪费存储空间
- 增加解码的复杂度
实现类:
bitsPerValue>24bitsPerValue>24bitsPerValue>24时,使用BulkOperationPacked
bitsPerValue∈[1,24]bitsPerValue\in[1,24]bitsPerValue∈[1,24]时,使用BulkOperationPacked*,*是从1到24。
单个value不跨block
- 存在空间浪费,浪费程度和bitsPerValue有关
- 解码比较简单
- 实现类:BulkOperationPackedSingleBlock
这两种不同的编码方式在Lucene中用两个枚举类来区分,PACKED和PACKED_SINGLE_BLOCK。
| public enum Format { | |
| // 所有的值都是连续存储在一起的,允许一个value编码结果跨越多个block | |
| PACKED() { | |
| // 忽略不相关的代码 | |
| }, | |
| // 一个value一个block | |
| PACKED_SINGLE_BLOCK() { | |
| // 忽略不相关的代码 | |
| }; | |
| // 忽略不相关的代码 | |
| } |
特别需要注意的是,在9.0.0版本之前,Lucene中是严格实现了这两种策略,但是从9.0.0开始,Lucene废弃了PACKED_SINGLE_BLOCK,因此在本文中,我们重点介绍PACKED。
总览
Lucene中对批量的正整数压缩编码设置了几种可选的压缩模式,有不同的内存浪费和不同的编解码速度,实际上就是用空间换时间程度的差异:
- FASTEST:这种编码速度允许浪费7倍的内存,是编码速度最快的一种模式,在实现上基本就是一个block一个value。
- FAST:这种编码速度允许浪费50%的内存,会选择一种比较合适的bitsPerValue来获取速度较快的编码器。
- DEFAULT:这种编码速度允许浪费25%的内存,编码速度中规中矩。
- COMPACT:这种编码不允许浪费任何内存,编码速度是最慢的。
在PackedInts中有个工具方法fastestFormatAndBits,接受要编码的数据量,bitsPerValue,以及预期可浪费的最大内存来调整bitsPerValue,从而获得当前条件下最快的编码器。
| // acceptableOverheadRatio:允许编码结果浪费的内存比率 | |
| public static FormatAndBits fastestFormatAndBits( | |
| int valueCount, int bitsPerValue, float acceptableOverheadRatio) { | |
| if (valueCount == -) { // 如果不清楚要编码的数据量,就把valueCount设为-1,会按最大的数量来估计 | |
| valueCount = Integer.MAX_VALUE; | |
| } | |
| // acceptableOverheadRatio不能小于COMPACT | |
| acceptableOverheadRatio = Math.max(COMPACT, acceptableOverheadRatio); | |
| // acceptableOverheadRatio不能超过FASTEST | |
| acceptableOverheadRatio = Math.min(FASTEST, acceptableOverheadRatio); | |
| // 每个value可以允许浪费的比例 | |
| float acceptableOverheadPerValue = acceptableOverheadRatio * bitsPerValue; | |
| // 每个value最大可能使用的bit数 | |
| int maxBitsPerValue = bitsPerValue + (int) acceptableOverheadPerValue; | |
| int actualBitsPerValue = -; | |
| // block一般是int或者是long,所以,16,32,64的编码速度是比较快的 | |
| if (bitsPerValue <= && maxBitsPerValue >= 8) { | |
| actualBitsPerValue =; | |
| } else if (bitsPerValue <= && maxBitsPerValue >= 16) { | |
| actualBitsPerValue =; | |
| } else if (bitsPerValue <= && maxBitsPerValue >= 32) { | |
| actualBitsPerValue =; | |
| } else if (bitsPerValue <= && maxBitsPerValue >= 64) { | |
| actualBitsPerValue =; | |
| } else { | |
| actualBitsPerValue = bitsPerValue; | |
| } | |
| // 强制使用Format.PACKED,已经不使用PACKED_SINGLE_BLOCK了 | |
| return new FormatAndBits(Format.PACKED, actualBitsPerValue); | |
| } |
有了format和bitsPerValue之后,BulkOperation中使用策略模式实现了获取相应编码器的逻辑:
| public static Encoder getEncoder(Format format, int version, int bitsPerValue) { | |
| checkVersion(version); | |
| return BulkOperation.of(format, bitsPerValue); | |
| } |
可以看到策略模式中就是获取bitsPerValue对应的提前创建好的编解码器:
| public static BulkOperation of(PackedInts.Format format, int bitsPerValue) { | |
| switch (format) { | |
| case PACKED: | |
| assert packedBulkOps[bitsPerValue -] != null; | |
| return packedBulkOps[bitsPerValue -]; | |
| case PACKED_SINGLE_BLOCK: // 弃用,不用看了 | |
| assert packedSingleBlockBulkOps[bitsPerValue -] != null; | |
| return packedSingleBlockBulkOps[bitsPerValue -]; | |
| default: | |
| throw new AssertionError(); | |
| } | |
| } |
对于bitsPerValue的每个可能值,都有一个对应的编码器:
| private static final BulkOperation[] packedBulkOps = | |
| new BulkOperation[] { | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| new BulkOperationPacked(), | |
| }; |
前面我们已经说过了,PACKED_SINGLE_BLOCK被弃用了,因此我们下面重点介绍PACKED的情况。
编解码
上面的BulkOperation中预置的编解码器看着很复杂,其实是比较简单的。从名字中带BulkOperation就知道,这是对数据的批量操作,也就是对数据的批量编解码,下面我们来详细介绍相关的类的逻辑。
BulkOperation
在BulkOperation中除了预置所有bitsPerValue对应的编解码器和根据bitsPerValue获取对应的编解码器之外,还有一个比较重要的方法,涉及到一个概念:iteration。
在理解iteration之前,我们先想想,如果要编码的数据量特别大,我们一次性全加载进内存,岂不是会占用很大的内存空间,甚至可能出现OOM。因此,需要控制编码过程中内存的使用情况,这就涉及到了iteration。
各个编码器在自己内部会限定每个iteration最多能够处理的value个数,通过下面的方法可以算出在一定的内存限制条件下最多可以使用多少个iteration,这样就可以间接知道一次编码可以处理多少个value了。
| // ramBudget限制在编码过程中使用的内存上限,单位是字节 | |
| public final int computeIterations(int valueCount, int ramBudget) { | |
| // byteBlockCount():一个iteration需要几个byte存储编码后的结果 | |
| // byteValueCount(): 一个iteration需要几个byte存储待编码的value个数,value是都按long类型处理 | |
| // 这里先算出来ramBudget可以支撑的最大的iteration,并没有考虑实际的valueCount,后面再调整 | |
| final int iterations = ramBudget / (byteBlockCount() + * byteValueCount()); | |
| if (iterations ==) { // 至少是1 | |
| return; | |
| } else if ((iterations -) * byteValueCount() >= valueCount) { // 如果不需要那么多的迭代次数 | |
| // 根据真实的valueCount计算合适的iteration | |
| return (int) Math.ceil((double) valueCount / byteValueCount()); | |
| } else { | |
| return iterations; | |
| } | |
| } |
BulkOperationPacked
BulkOperationPacked是一个通用的编解码器实现,它支持所有的bitsPerValue。
成员变量
需要重点理解下longBlockCount,longValueCount,byteBlockCount,byteValueCount四个变量的意思,具体这四个变量是得来的,逻辑在构造器中。
| private final int bitsPerValue; | |
| // 当block是long的时候,一个iteration最少会使用几个block | |
| private final int longBlockCount; | |
| // 一个iteration中,使用longBlockCount个block可以编码的value数量 | |
| private final int longValueCount; | |
| // 当block是byte的时候,一个iteration最少会使用几个block | |
| private final int byteBlockCount; | |
| // 一个iteration中,使用byteBlockCount个block可以编码的value数量 | |
| private final int byteValueCount; | |
| // 用来获取value中有效位的掩码 | |
| private final long mask; | |
| // mask的int格式 | |
| private final int intMask; |
构造器
在构造器中,根据固定的规则计算longBlockCount,longValueCount,byteBlockCount,byteValueCount。
这里我不知道为什么使用这样的规则,如果有朋友知道其中奥秘的可以评论分享。
| public BulkOperationPacked(int bitsPerValue) { | |
| this.bitsPerValue = bitsPerValue; | |
| assert bitsPerValue > && bitsPerValue <= 64; | |
| int blocks = bitsPerValue; | |
| while ((blocks &) == 0) { // 如果是2的倍数则除以2,直到不是2的倍数 | |
| blocks >>>=; | |
| } | |
| // 一次迭代用几个long | |
| this.longBlockCount = blocks; | |
| // 一次迭代可以处理几个value | |
| this.longValueCount = * longBlockCount / bitsPerValue; | |
| // 一次迭代用几个byte | |
| int byteBlockCount = * longBlockCount; | |
| // 一次迭代用处理几个value | |
| int byteValueCount = longValueCount; | |
| while ((byteBlockCount &) == 0 && (byteValueCount & 1) == 0) { // 缩小成直到不是2的倍数 | |
| byteBlockCount >>>=; | |
| byteValueCount >>>=; | |
| } | |
| this.byteBlockCount = byteBlockCount; | |
| this.byteValueCount = byteValueCount; | |
| // 算掩码 | |
| if (bitsPerValue ==) { | |
| this.mask = ~L; | |
| } else { | |
| this.mask = (L << bitsPerValue) - 1; | |
| } | |
| this.intMask = (int) mask; | |
| assert longValueCount * bitsPerValue == * longBlockCount; | |
| } |
编码
根据block大小和要处理的value的类型的不同,一共有四个编码方法:
以long为block的单位,编码long数组
| public void encode( | |
| long[] values, int valuesOffset, long[] blocks, int blocksOffset, int iterations) { | |
| // 初始化下一个block的值 | |
| long nextBlock =; | |
| // 当前block中还剩下多少位可以用来编码 | |
| int bitsLeft =; | |
| // longValueCount * iterations:总共可以处理的数据 | |
| for (int i =; i < longValueCount * iterations; ++i) { | |
| // 当前block使用bitsPerValue来进行编码 | |
| bitsLeft -= bitsPerValue; | |
| if (bitsLeft >) { // 当前block放下当前value后还有空间 | |
| // 把当前value放到当前block中 | |
| nextBlock |= values[valuesOffset++] << bitsLeft; | |
| } else if (bitsLeft ==) { // 刚好可以存放最后一个数据的编码结果 | |
| nextBlock |= values[valuesOffset++]; // 最后一个数据的编码结果放在nextBlock中 | |
| blocks[blocksOffset++] = nextBlock; // 存储block | |
| nextBlock =; // 重置block | |
| bitsLeft =; // 重置bitsLeft | |
| } else { // 需要跨block处理 | |
| nextBlock |= values[valuesOffset] >>> -bitsLeft; // 当前block剩下的空间存储部分value | |
| blocks[blocksOffset++] = nextBlock; | |
| // (L << -bitsLeft) - 1):取出value剩余数据的掩码 | |
| // (values[valuesOffset++] & ((L << -bitsLeft) - 1)): 取出剩余数据 | |
| // << ( + bitsLeft):放到最前面 | |
| nextBlock = (values[valuesOffset++] & ((L << -bitsLeft) - 1)) << (64 + bitsLeft); | |
| // 更新block可用空间 | |
| bitsLeft +=; | |
| } | |
| } | |
| } |
以long为block的单位,编码int数组
和上面的方法逻辑其实一模一样,只是在处理value的时候,先和0xFFFFFFFFL做按位与运算转成long。
| public void encode( | |
| int[] values, int valuesOffset, long[] blocks, int blocksOffset, int iterations) { | |
| long nextBlock =; | |
| int bitsLeft =; | |
| for (int i =; i < longValueCount * iterations; ++i) { | |
| bitsLeft -= bitsPerValue; | |
| if (bitsLeft >) { | |
| nextBlock |= (values[valuesOffset++] &xFFFFFFFFL) << bitsLeft; | |
| } else if (bitsLeft ==) { | |
| nextBlock |= (values[valuesOffset++] &xFFFFFFFFL); | |
| blocks[blocksOffset++] = nextBlock; | |
| nextBlock =; | |
| bitsLeft =; | |
| } else { // bitsLeft < | |
| nextBlock |= (values[valuesOffset] &xFFFFFFFFL) >>> -bitsLeft; | |
| blocks[blocksOffset++] = nextBlock; | |
| nextBlock = (values[valuesOffset++] & ((L << -bitsLeft) - 1)) << (64 + bitsLeft); | |
| bitsLeft +=; | |
| } | |
| } | |
| } |
以byte为block的单位,编码long数组
| public void encode( | |
| long[] values, int valuesOffset, byte[] blocks, int blocksOffset, int iterations) { | |
| int nextBlock =; | |
| int bitsLeft =; | |
| for (int i =; i < byteValueCount * iterations; ++i) { | |
| final long v = values[valuesOffset++]; | |
| assert PackedInts.unsignedBitsRequired(v) <= bitsPerValue; | |
| if (bitsPerValue < bitsLeft) { // 如果当前block还可以容纳value的编码 | |
| nextBlock |= v << (bitsLeft - bitsPerValue); | |
| bitsLeft -= bitsPerValue; | |
| } else { | |
| // 除了当前block可以容纳之外,还剩下多少bits | |
| int bits = bitsPerValue - bitsLeft; | |
| // 当前block剩下的空间把value的高位部分先存 | |
| blocks[blocksOffset++] = (byte) (nextBlock | (v >>> bits)); | |
| while (bits >=) { // 如果还需要处理的bits超过一个byte | |
| bits -=; | |
| blocks[blocksOffset++] = (byte) (v >>> bits); | |
| } | |
| // 剩下的bits不足一个byte | |
| bitsLeft = - bits; | |
| // (v & ((L << bits) - 1):取出当前value的高bits位 | |
| // 存放在nextBlock的高bits位 | |
| nextBlock = (int) ((v & ((L << bits) - 1)) << bitsLeft); | |
| } | |
| } | |
| assert bitsLeft ==; | |
| } |
以byte为block的单位,编码int数组
和上面的方法逻辑一模一样
| public void encode( | |
| int[] values, int valuesOffset, byte[] blocks, int blocksOffset, int iterations) { | |
| int nextBlock =; | |
| int bitsLeft =; | |
| for (int i =; i < byteValueCount * iterations; ++i) { | |
| final int v = values[valuesOffset++]; | |
| assert PackedInts.bitsRequired(v &xFFFFFFFFL) <= bitsPerValue; | |
| if (bitsPerValue < bitsLeft) { | |
| nextBlock |= v << (bitsLeft - bitsPerValue); | |
| bitsLeft -= bitsPerValue; | |
| } else { | |
| int bits = bitsPerValue - bitsLeft; | |
| blocks[blocksOffset++] = (byte) (nextBlock | (v >>> bits)); | |
| while (bits >=) { | |
| bits -=; | |
| blocks[blocksOffset++] = (byte) (v >>> bits); | |
| } | |
| bitsLeft = - bits; | |
| nextBlock = (v & (( << bits) - 1)) << bitsLeft; | |
| } | |
| } | |
| assert bitsLeft ==; | |
| } |
解码
同样地,和编码一一对应,也有四个解码方法:
以long为block的单位,解码成long数组
| public void decode( | |
| long[] blocks, int blocksOffset, long[] values, int valuesOffset, int iterations) { | |
| // 当前block中还剩多少位未解码 | |
| int bitsLeft =; | |
| for (int i =; i < longValueCount * iterations; ++i) { | |
| bitsLeft -= bitsPerValue; | |
| if (bitsLeft <) { // 跨block的解码 | |
| values[valuesOffset++] = | |
| ((blocks[blocksOffset++] & ((L << (bitsPerValue + bitsLeft)) - 1)) << -bitsLeft) | |
| | (blocks[blocksOffset] >>> ( + bitsLeft)); | |
| bitsLeft +=; | |
| } else { | |
| values[valuesOffset++] = (blocks[blocksOffset] >>> bitsLeft) & mask; | |
| } | |
| } | |
| } |
以long为block的单位,解码成int数组
逻辑和上面的方法一样。
| public void decode( | |
| long[] blocks, int blocksOffset, int[] values, int valuesOffset, int iterations) { | |
| if (bitsPerValue >) { | |
| throw new UnsupportedOperationException( | |
| "Cannot decode " + bitsPerValue + "-bits values into an int[]"); | |
| } | |
| int bitsLeft =; | |
| for (int i =; i < longValueCount * iterations; ++i) { | |
| bitsLeft -= bitsPerValue; | |
| if (bitsLeft <) { | |
| values[valuesOffset++] = | |
| (int) | |
| (((blocks[blocksOffset++] & ((L << (bitsPerValue + bitsLeft)) - 1)) << -bitsLeft) | |
| | (blocks[blocksOffset] >>> ( + bitsLeft))); | |
| bitsLeft +=; | |
| } else { | |
| values[valuesOffset++] = (int) ((blocks[blocksOffset] >>> bitsLeft) & mask); | |
| } | |
| } | |
| } |
以byte为block的单位,解码成long数组
| public void decode( | |
| byte[] blocks, int blocksOffset, long[] values, int valuesOffset, int iterations) { | |
| long nextValue =L; | |
| int bitsLeft = bitsPerValue; | |
| for (int i =; i < iterations * byteBlockCount; ++i) { | |
| final long bytes = blocks[blocksOffset++] &xFFL; | |
| if (bitsLeft >) { | |
| bitsLeft -=; | |
| nextValue |= bytes << bitsLeft; | |
| } else { | |
| int bits = - bitsLeft; | |
| values[valuesOffset++] = nextValue | (bytes >>> bits); | |
| while (bits >= bitsPerValue) { | |
| bits -= bitsPerValue; | |
| values[valuesOffset++] = (bytes >>> bits) & mask; | |
| } | |
| bitsLeft = bitsPerValue - bits; | |
| nextValue = (bytes & ((L << bits) - 1)) << bitsLeft; | |
| } | |
| } | |
| assert bitsLeft == bitsPerValue; | |
| } |
以byte为block的单位,解码成int数组
| public void decode( | |
| byte[] blocks, int blocksOffset, int[] values, int valuesOffset, int iterations) { | |
| int nextValue =; | |
| int bitsLeft = bitsPerValue; | |
| for (int i =; i < iterations * byteBlockCount; ++i) { | |
| final int bytes = blocks[blocksOffset++] &xFF; | |
| if (bitsLeft >) { | |
| bitsLeft -=; | |
| nextValue |= bytes << bitsLeft; | |
| } else { | |
| int bits = - bitsLeft; | |
| values[valuesOffset++] = nextValue | (bytes >>> bits); | |
| while (bits >= bitsPerValue) { | |
| bits -= bitsPerValue; | |
| values[valuesOffset++] = (bytes >>> bits) & intMask; | |
| } | |
| bitsLeft = bitsPerValue - bits; | |
| nextValue = (bytes & (( << bits) - 1)) << bitsLeft; | |
| } | |
| } | |
| assert bitsLeft == bitsPerValue; | |
| } |
BulkOperationPacked*
BulkOperationPacked中的实现支持所有bitsPerValue的值,BulkOperationPacked*继承了BulkOperationPacked,对于解码的实现针对特定的bitsPerValue有了特定的实现,性能比通用实现更高效(猜测是特殊实现没有分支,避免了分支预测错误的性能损耗),那为什么只对解码做针对实现,编码怎么不一起实现?编码也是可以做针对实现的,但是编码只在构建索引的时候使用一次,而解码是会多次使用的,因此只对解码做了特殊实现。那为什么只对bitsPerValue是25以下的做特殊实现,这个不清楚,25以上不常见?
虽然Lucene中实现了24个BulkOperationPacked*,但是所有BulkOperationPacked*的主要逻辑都相同:一个iteration可以处理几个value产生几个block是已知的(在BulkOperationPacked的构造器中计算得到),然后直接从这些block解码得到所有的value,下面我们看一个例子就好:
当bitsPerValue=2的时候,我们可以知道:
longBlockCount=1
longValueCount=32
byteBlockCount=1
byteValueCount=4
所以当以long为block的单位时,一个iteration可以从1个block中解析出32个value,当以byte为block的单位是,可以从1个block中解析出4个value。
| final class BulkOperationPacked extends BulkOperationPacked { | |
| public BulkOperationPacked() { | |
| super(); | |
| } | |
| public void decode( | |
| long[] blocks, int blocksOffset, int[] values, int valuesOffset, int iterations) { | |
| for (int i =; i < iterations; ++i) { | |
| // 只会用到一个block | |
| final long block = blocks[blocksOffset++]; | |
| // 需要解析出个value | |
| for (int shift =; shift >= 0; shift -= 2) { | |
| values[valuesOffset++] = (int) ((block >>> shift) &); | |
| } | |
| } | |
| } | |
| public void decode( | |
| byte[] blocks, int blocksOffset, int[] values, int valuesOffset, int iterations) { | |
| for (int j =; j < iterations; ++j) { | |
| // 只会用到一个block | |
| final byte block = blocks[blocksOffset++]; | |
| // 需要解析出个value | |
| values[valuesOffset++] = (block >>>) & 3; | |
| values[valuesOffset++] = (block >>>) & 3; | |
| values[valuesOffset++] = (block >>>) & 3; | |
| values[valuesOffset++] = block &; | |
| } | |
| } | |
| public void decode( | |
| long[] blocks, int blocksOffset, long[] values, int valuesOffset, int iterations) { | |
| for (int i =; i < iterations; ++i) { | |
| // 只会用到一个block | |
| final long block = blocks[blocksOffset++]; | |
| // 需要解析出个value | |
| for (int shift =; shift >= 0; shift -= 2) { | |
| values[valuesOffset++] = (block >>> shift) &; | |
| } | |
| } | |
| } | |
| public void decode( | |
| byte[] blocks, int blocksOffset, long[] values, int valuesOffset, int iterations) { | |
| for (int j =; j < iterations; ++j) { | |
| // 只会用到一个block | |
| final byte block = blocks[blocksOffset++]; | |
| // 需要解析出个value | |
| values[valuesOffset++] = (block >>>) & 3; | |
| values[valuesOffset++] = (block >>>) & 3; | |
| values[valuesOffset++] = (block >>>) & 3; | |
| values[valuesOffset++] = block &; | |
| } | |
| } | |
| } |
应用
有了上面批量编解码的基础逻辑,我们再看看基于编解码器有哪些应用,而这些应用之间有什么区别,各自又是针对什么场景的?
PackedWriter
PackedWriter是已知所要处理的数据的bitsPerValue,根据这个bitsPerValue获取对应的编码器,因此所有的数据都使用一样的编码器。
PackedWriter适用于所有数据量大小差不多的情况,如果数据中存在少量值比较大的,则会影响压缩效果,因为所有value是按最大的值来计算bitsPerValue的。
| final class PackedWriter extends PackedInts.Writer { | |
| // 是否构建结束 | |
| boolean finished; | |
| //.0.0之后的版本都是Packed | |
| final PackedInts.Format format; | |
| // 根据format和bitsPerValue决定encoder | |
| final BulkOperation encoder; | |
| // 编码结果的buffer | |
| final byte[] nextBlocks; | |
| // 待编码的value的buffer | |
| final long[] nextValues; | |
| // 通过编码器计算得到的iterations | |
| final int iterations; | |
| // nextValues可以写入的位置 | |
| int off; | |
| // 已处理的value的个数 | |
| int written; | |
| PackedWriter( | |
| PackedInts.Format format, DataOutput out, int valueCount, int bitsPerValue, int mem) { | |
| super(out, valueCount, bitsPerValue); | |
| this.format = format; | |
| encoder = BulkOperation.of(format, bitsPerValue); | |
| iterations = encoder.computeIterations(valueCount, mem); | |
| // 创建合适的大小 | |
| nextBlocks = new byte[iterations * encoder.byteBlockCount()]; | |
| nextValues = new long[iterations * encoder.byteValueCount()]; | |
| off =; | |
| written =; | |
| finished = false; | |
| } | |
| protected PackedInts.Format getFormat() { | |
| return format; | |
| } | |
| public void add(long v) throws IOException { | |
| if (valueCount != - && written >= valueCount) { | |
| throw new EOFException("Writing past end of stream"); | |
| } | |
| // 把value临时存储到nextValues中,等到编码 | |
| nextValues[off++] = v; | |
| if (off == nextValues.length) { // 如果nextValues满了,则进行编码 | |
| flush(); | |
| } | |
| ++written; | |
| } | |
| public void finish() throws IOException { | |
| if (valueCount != -) { // 如果数据没有达到预期的数量,则补0 | |
| while (written < valueCount) { | |
| add(L); | |
| } | |
| } | |
| flush(); | |
| finished = true; | |
| } | |
| private void flush() throws IOException { | |
| // 编码 | |
| encoder.encode(nextValues,, nextBlocks, 0, iterations); | |
| // 以byte作为block的单位,一共几个byte | |
| final int blockCount = (int) format.byteCount(PackedInts.VERSION_CURRENT, off, bitsPerValue); | |
| // 编码的结果持久化 | |
| out.writeBytes(nextBlocks, blockCount); | |
| // 清空nextValues | |
| Arrays.fill(nextValues,L); | |
| off =; | |
| } | |
| public int ord() { | |
| return written -; | |
| } | |
| } |
分段处理
需要说明下按照类名原本应该是分block的,但是在我们底层编解码中涉及到block的概念,如果这里再来一个block,则可能会混淆,所以在这里我们可以理解是把要处理的数据流分成多段处理。PackedWriter其实也 可以理解是分段的(设定内存阈值下可以处理的数据量),但是它每段都是使用一样的编码器,而这个小节要介绍的,每一段是可以使用不一样的编码器。
AbstractBlockPackedWriter
前面我们介绍PackedWriter的时候说,如果大批量数据中存在少量的数值较大的value会影响压缩效果。针对这种情况的处理,Lucene按分段处理,每段包含部分value,如果存在少量的数值较大,则只会影响其所在的段中,不会影响所有的数据的编码。具体我们看下源码,注意下面的源码中忽略一些无关紧要的代码:
| abstract class AbstractBlockPackedWriter { | |
| // 用来持久化编码结果的 | |
| protected DataOutput out; | |
| // 暂存待编码的value | |
| protected final long[] values; | |
| // 存储编码后的block | |
| protected byte[] blocks; | |
| protected int off; | |
| // 处理的第几个value | |
| protected long ord; | |
| protected boolean finished; | |
| // blockSize:段大小 | |
| protected AbstractBlockPackedWriter(DataOutput out, int blockSize) { | |
| checkBlockSize(blockSize, MIN_BLOCK_SIZE, MAX_BLOCK_SIZE); | |
| reset(out); | |
| values = new long[blockSize]; | |
| } | |
| public void add(long l) throws IOException { | |
| checkNotFinished(); | |
| if (off == values.length) { // 如果values满了,也就是已经收集到了一段数据了,则进行编码 | |
| flush(); | |
| } | |
| values[off++] = l; | |
| ++ord; | |
| } | |
| public void finish() throws IOException { | |
| checkNotFinished(); | |
| if (off >) { // 如果有数据则flush | |
| flush(); | |
| } | |
| finished = true; | |
| } | |
| // flush中计算的就是当前段的bitsPerValue,由子类实现 | |
| protected abstract void flush() throws IOException; | |
| // 执行编码,在flush中被调用,bitsRequired是flush中计算得到的 | |
| protected final void writeValues(int bitsRequired) throws IOException { | |
| // 每一段都有自己的编码器 | |
| final PackedInts.Encoder encoder = | |
| PackedInts.getEncoder(PackedInts.Format.PACKED, PackedInts.VERSION_CURRENT, bitsRequired); | |
| final int iterations = values.length / encoder.byteValueCount(); | |
| final int blockSize = encoder.byteBlockCount() * iterations; | |
| if (blocks == null || blocks.length < blockSize) { | |
| blocks = new byte[blockSize]; | |
| } | |
| if (off < values.length) { | |
| Arrays.fill(values, off, values.length,L); | |
| } | |
| encoder.encode(values,, blocks, 0, iterations); | |
| final int blockCount = | |
| (int) PackedInts.Format.PACKED.byteCount(PackedInts.VERSION_CURRENT, off, bitsRequired); | |
| // 持久化编码后的数据 | |
| out.writeBytes(blocks, blockCount); | |
| } | |
| } |
AbstractBlockPackedWriter有两个实现类,分别是通用实现和处理单调递增数据的,其实就是针对不同的场景计算bitsPerValue的逻辑不一样。
BlockPackedWriter
BlockPackedWriter是通用的分段实现,它先找出最小值,所有待编码的value都减去最小值,这样就可以缩小bitsPerValue,达到更优的编码效果。
| public final class BlockPackedWriter extends AbstractBlockPackedWriter { | |
| public BlockPackedWriter(DataOutput out, int blockSize) { | |
| super(out, blockSize); | |
| } | |
| protected void flush() throws IOException { | |
| long min = Long.MAX_VALUE, max = Long.MIN_VALUE; | |
| for (int i =; i < off; ++i) { // 寻找最大值和最小值 | |
| min = Math.min(values[i], min); | |
| max = Math.max(values[i], max); | |
| } | |
| // 最大值和最小值的差值 | |
| final long delta = max - min; | |
| // 差值的bitsRequired,下面会把所有的value更新为value和min的差值,所以bitsRequired就是更新后的bitsPerValue | |
| int bitsRequired = delta == ? 0 : PackedInts.unsignedBitsRequired(delta); | |
| if (bitsRequired ==) { // 如果最大和最小的差值都需要64bits来存储,那就不用去更新value了 | |
| min =L; | |
| } else if (min >L) { | |
| // 让min尽量小,因为min会用VLong编码,这样尽可能使用更少的字节 | |
| min = Math.max(L, max - PackedInts.maxValue(bitsRequired)); | |
| } | |
| // bitsRequired左移一位,最后一位是标记位,标记min是否是 | |
| final int token = (bitsRequired << BPV_SHIFT) | (min == ? MIN_VALUE_EQUALS_0 : 0); | |
| out.writeByte((byte) token); | |
| if (min !=) { // VLong编码min | |
| writeVLong(out, zigZagEncode(min) -); | |
| } | |
| if (bitsRequired >) { | |
| if (min !=) { | |
| for (int i =; i < off; ++i) { // 所有的value更新为与最小值的差值 | |
| values[i] -= min; | |
| } | |
| } | |
| // 编码并持久化 | |
| writeValues(bitsRequired); | |
| } | |
| off =; | |
| } | |
| } |
MonotonicBlockPackedWriter
MonotonicBlockPackedWriter处理的是数据是递增的情况,MonotonicBlockPackedWriter先算每两个value之间的平均步长,通过这个平均步长就可以计算每个位置的期望expectValue,然后把value都更新为真实value和期望expectValue的差值,这样可能会有负数的value,所以需要一步是找出理论上的最小值min,保证所有的value和expectValue差值都是正数。
| public final class MonotonicBlockPackedWriter extends AbstractBlockPackedWriter { | |
| public MonotonicBlockPackedWriter(DataOutput out, int blockSize) { | |
| super(out, blockSize); | |
| } | |
| protected void flush() throws IOException { | |
| // 计算平均步长 | |
| final float avg = off == ? 0f : (float) (values[off - 1] - values[0]) / (off - 1); | |
| long min = values[]; | |
| for (int i =; i < off; ++i) { // 计算出期望的最小值,保证根据平均步长计算每个位置的期望值都是正数 | |
| final long actual = values[i]; | |
| // 相同位置的期望value | |
| final long expected = expected(min, avg, i); | |
| if (expected > actual) { // 如果期望值大于实际值 | |
| // 调小期望的最小值 | |
| min -= (expected - actual); | |
| } | |
| } | |
| // 最大差值,用来计算bitsPerValue的 | |
| long maxDelta =; | |
| for (int i =; i < off; ++i) { // 所有的值都更新为和期望值的差值 | |
| values[i] = values[i] - expected(min, avg, i); | |
| maxDelta = Math.max(maxDelta, values[i]); | |
| } | |
| out.writeZLong(min); | |
| out.writeInt(Float.floatToIntBits(avg)); | |
| if (maxDelta ==) { // 所有的值都一样 | |
| out.writeVInt(); | |
| } else { | |
| final int bitsRequired = PackedInts.bitsRequired(maxDelta); | |
| out.writeVInt(bitsRequired); | |
| // 编码并持久化 | |
| writeValues(bitsRequired); | |
| } | |
| off =; | |
| } | |
| } |
DirectWriter
DirectWriter比较特殊,它没有使用BulkOperationPacked系列的编码器。DirectWriter综合考虑空间浪费和编码解码的速度,并没有支持全部的bitsPerValue,它支持的bitsPerValue的列表是:1, 2, 4, 8, 12, 16, 20, 24, 28, 32, 40, 48, 56, 64。
在存储的时候,按照bitsPerValue不同的值分为3种处理逻辑,每种处理逻辑的block都是不一样的:
bitsPerValue是8的倍数时: 8, 16, 24, 32, 40, 48, 56, 64
- 40,48,56,64的时候,用long来存储一个value,此时block就是long,并且一个block中只有一个value。
- 24,32的时候,用int来存储一个value,此时block就是int,并且一个block中只有一个value。
- 16的时候,用short来存储一个value,此时block就是short,并且一个block中只有一个value。
- 8的时候,用byte来存储一个value,此时block就是byte,并且一个block中只有一个value。
bitsPerValue是1,2,4
用long来存储多个value,此时block就是long,一个block中有64/bitsPerValue个value。
bitsPerValue是12,20,28
- 12:用int存储两个value,此时block就是int,一个block中有两个value。
- 20,28:用long存储两个value,此时block就是long,一个block中有两个value。
那如果是其他bitsPerValue的值,DirectWriter会找上述支持的列表中大于bitsPerValue的第一个来进行处理,无非是压缩率低一些。比如当前的bitsPerValue=17,则DirectWriter会使用20的方案来处理。
| public final class DirectWriter { | |
| // 每个value使用几个bit存储 | |
| final int bitsPerValue; | |
| // 有几个需要存储的value | |
| final long numValues; | |
| // 数据存储的目的地 | |
| final DataOutput output; | |
| // 统计已经处理了几个数据 | |
| long count; | |
| // 是否已经处理完成了 | |
| boolean finished; | |
| // nextValues的下一个写入的位置 | |
| int off; | |
| // 存储block | |
| final byte[] nextBlocks; | |
| // 临时存储数据,待构建成block | |
| final long[] nextValues; | |
| // DirectWriter支持的bitsPerValue参数列表 | |
| static final int[] SUPPORTED_BITS_PER_VALUE = | |
| new int[] {, 2, 4, 8, 12, 16, 20, 24, 28, 32, 40, 48, 56, 64}; | |
| DirectWriter(DataOutput output, long numValues, int bitsPerValue) { | |
| this.output = output; | |
| this.numValues = numValues; | |
| this.bitsPerValue = bitsPerValue; | |
| // 可用的内存限制,是nextBlocks和nextValues两个数组合起来的大小限制 | |
| final int memoryBudgetInBits = Math.multiplyExact(Byte.SIZE, PackedInts.DEFAULT_BUFFER_SIZE); | |
| // nextValues的大小 | |
| int bufferSize = memoryBudgetInBits / (Long.SIZE + bitsPerValue); | |
| // 把bufferSize调整成下一个的倍数的值 | |
| bufferSize = Math.toIntExact(bufferSize +) & 0xFFFFFFC0; | |
| nextValues = new long[bufferSize]; | |
| // add bytes in the end so that any value could be written as a long | |
| nextBlocks = new byte[bufferSize * bitsPerValue / Byte.SIZE + Long.BYTES -]; | |
| } | |
| // 新增一个value | |
| public void add(long l) throws IOException { | |
| // 校验是否超出了一开始设定的value总数 | |
| if (count >= numValues) { | |
| throw new EOFException("Writing past end of stream"); | |
| } | |
| // 把数据暂存在nextValues中 | |
| nextValues[off++] = l; | |
| // 如果nextValues满了,则进行flush编码 | |
| if (off == nextValues.length) { | |
| flush(); | |
| } | |
| // 处理的value数+ | |
| count++; | |
| } | |
| // 构建一个block | |
| private void flush() throws IOException { | |
| if (off ==) { | |
| return; | |
| } | |
| // 把off之后的所有位置设为 | |
| Arrays.fill(nextValues, off, nextValues.length,L); | |
| // 将nextValues中的数据编码存储到nextBlocks中 | |
| encode(nextValues, off, nextBlocks, bitsPerValue); | |
| // 一共需要几个byte存储所有编码好的数据 | |
| final int blockCount = | |
| (int) PackedInts.Format.PACKED.byteCount(PackedInts.VERSION_CURRENT, off, bitsPerValue); | |
| // 存储编码后的数据 | |
| output.writeBytes(nextBlocks, blockCount); | |
| off =; | |
| } | |
| private static void encode(long[] nextValues, int upTo, byte[] nextBlocks, int bitsPerValue) { | |
| if ((bitsPerValue &) == 0) {// bitsPerValue的值是8的倍数: 8, 16, 24, 32, 40, 48, 56, 64 | |
| // 一个value需要几个byte | |
| final int bytesPerValue = bitsPerValue / Byte.SIZE; | |
| // i是nextValues中的下标 | |
| // o是在nextBlocks中下一个写入的下标 | |
| for (int i =, o = 0; i < upTo; ++i, o += bytesPerValue) { | |
| final long l = nextValues[i]; | |
| if (bitsPerValue > Integer.SIZE) { // 大于位的都用long存 | |
| BitUtil.VH_LE_LONG.set(nextBlocks, o, l); | |
| } else if (bitsPerValue > Short.SIZE) { //,32都用int存 | |
| BitUtil.VH_LE_INT.set(nextBlocks, o, (int) l); | |
| } else if (bitsPerValue > Byte.SIZE) { //用short存 | |
| BitUtil.VH_LE_SHORT.set(nextBlocks, o, (short) l); | |
| } else { //用byte存 | |
| nextBlocks[o] = (byte) l; | |
| } | |
| } | |
| } else if (bitsPerValue <) {// bitsPerValue的值是 1, 2, 4 | |
| // 一个long可以存几个value | |
| final int valuesPerLong = Long.SIZE / bitsPerValue; | |
| // o是在nextBlocks中的下一个可以写入的位置 | |
| for (int i =, o = 0; i < upTo; i += valuesPerLong, o += Long.BYTES) { | |
| long v =; | |
| // 构建一个block,一个block就是一个long | |
| for (int j =; j < valuesPerLong; ++j) { | |
| v |= nextValues[i + j] << (bitsPerValue * j); | |
| } | |
| BitUtil.VH_LE_LONG.set(nextBlocks, o, v); | |
| } | |
| } else {// bitsPerValue的值是, 20, 28,此时不是一个字节的整数倍,所以是2个2个处理 | |
| //个value需要几个字节 | |
| final int numBytesForValues = bitsPerValue * 2 / Byte.SIZE; | |
| // o是在nextBlocks中下一个可以写入的位置 | |
| for (int i =, o = 0; i < upTo; i += 2, o += numBytesFor2Values) { | |
| final long l = nextValues[i]; | |
| final long l = nextValues[i + 1]; | |
| //个合成一个 | |
| final long merged = l | (l2 << bitsPerValue); | |
| if (bitsPerValue <= Integer.SIZE /) { // 如果bitsPerValue=12,则以int的方式存两个value | |
| BitUtil.VH_LE_INT.set(nextBlocks, o, (int) merged); | |
| } else { // bitsPerValue=或者28,则以long的方式存两个value | |
| BitUtil.VH_LE_LONG.set(nextBlocks, o, merged); | |
| } | |
| } | |
| } | |
| } | |
| public void finish() throws IOException { | |
| if (count != numValues) { | |
| throw new IllegalStateException( | |
| "Wrong number of values added, expected: " + numValues + ", got: " + count); | |
| } | |
| // 为nextValues中剩下的value编码 | |
| flush(); | |
| // DirectWriter的编码方案存在填充字节 | |
| int paddingBitsNeeded; | |
| if (bitsPerValue > Integer.SIZE) { | |
| paddingBitsNeeded = Long.SIZE - bitsPerValue; | |
| } else if (bitsPerValue > Short.SIZE) { | |
| paddingBitsNeeded = Integer.SIZE - bitsPerValue; | |
| } else if (bitsPerValue > Byte.SIZE) { | |
| paddingBitsNeeded = Short.SIZE - bitsPerValue; | |
| } else { | |
| paddingBitsNeeded =; | |
| } | |
| final int paddingBytesNeeded = (paddingBitsNeeded + Byte.SIZE -) / Byte.SIZE; | |
| for (int i =; i < paddingBytesNeeded; i++) { | |
| output.writeByte((byte)); | |
| } | |
| finished = true; | |
| } | |
| // 获取一个DirectWriter的实例 | |
| public static DirectWriter getInstance(DataOutput output, long numValues, int bitsPerValue) { | |
| if (Arrays.binarySearch(SUPPORTED_BITS_PER_VALUE, bitsPerValue) <) { | |
| throw new IllegalArgumentException( | |
| "Unsupported bitsPerValue " + bitsPerValue + ". Did you use bitsRequired?"); | |
| } | |
| return new DirectWriter(output, numValues, bitsPerValue); | |
| } | |
| // 如果bitsRequired是不支持的,则需要纠正 | |
| private static int roundBits(int bitsRequired) { | |
| int index = Arrays.binarySearch(SUPPORTED_BITS_PER_VALUE, bitsRequired); | |
| if (index <) { // 如果bitsRequired不是支持的参数,则使用最接近且大于bitsRequired的参数 | |
| return SUPPORTED_BITS_PER_VALUE[-index -]; | |
| } else { | |
| return bitsRequired; // 如果是支持的,则使用它自己 | |
| } | |
| } | |
| // 通过有符号的最大值计算需要的bitsPerValue | |
| public static int bitsRequired(long maxValue) { | |
| return roundBits(PackedInts.bitsRequired(maxValue)); | |
| } | |
| // 通过无符号的最大值计算需要的bitsPerValue | |
| public static int unsignedBitsRequired(long maxValue) { | |
| return roundBits(PackedInts.unsignedBitsRequired(maxValue)); | |
| } | |
| } |
DirectMonotonicWriter
DirectMonotonicWriter对单调递增的数据有预处理,逻辑和MonotonicBlockPackedWriter非常相似,编码使用的是DirectWriter。
| public final class DirectMonotonicWriter { | |
| public static final int MIN_BLOCK_SHIFT =; | |
| public static final int MAX_BLOCK_SHIFT =; | |
| final IndexOutput meta; | |
| final IndexOutput data; | |
| final long numValues; | |
| final long baseDataPointer; | |
| final long[] buffer; | |
| int bufferSize; | |
| long count; | |
| boolean finished; | |
| long previous = Long.MIN_VALUE; | |
| DirectMonotonicWriter(IndexOutput metaOut, IndexOutput dataOut, long numValues, int blockShift) { | |
| if (blockShift < MIN_BLOCK_SHIFT || blockShift > MAX_BLOCK_SHIFT) { | |
| throw new IllegalArgumentException( | |
| "blockShift must be in [" | |
| + MIN_BLOCK_SHIFT | |
| + "-" | |
| + MAX_BLOCK_SHIFT | |
| + "], got " | |
| + blockShift); | |
| } | |
| if (numValues <) { | |
| throw new IllegalArgumentException("numValues can't be negative, got " + numValues); | |
| } | |
| final long numBlocks = numValues == ? 0 : ((numValues - 1) >>> blockShift) + 1; | |
| if (numBlocks > ArrayUtil.MAX_ARRAY_LENGTH) { | |
| throw new IllegalArgumentException( | |
| "blockShift is too low for the provided number of values: blockShift=" | |
| + blockShift | |
| + ", numValues=" | |
| + numValues | |
| + ", MAX_ARRAY_LENGTH=" | |
| + ArrayUtil.MAX_ARRAY_LENGTH); | |
| } | |
| this.meta = metaOut; | |
| this.data = dataOut; | |
| this.numValues = numValues; | |
| final int blockSize = << blockShift; | |
| this.buffer = new long[(int) Math.min(numValues, blockSize)]; | |
| this.bufferSize =; | |
| this.baseDataPointer = dataOut.getFilePointer(); | |
| } | |
| private void flush() throws IOException { | |
| assert bufferSize !=; | |
| // 估计数值递增的平均步长 | |
| final float avgInc = | |
| (float) ((double) (buffer[bufferSize -] - buffer[0]) / Math.max(1, bufferSize - 1)); | |
| for (int i =; i < bufferSize; ++i) { | |
| // 按平均步长算的当前位置的期望值 | |
| final long expected = (long) (avgInc * (long) i); | |
| // 当前真实值和期望值之差,注意此时buffer中可能存在负数 | |
| buffer[i] -= expected; | |
| } | |
| // 寻找最小的值 | |
| long min = buffer[]; | |
| for (int i =; i < bufferSize; ++i) { | |
| min = Math.min(buffer[i], min); | |
| } | |
| long maxDelta =; | |
| for (int i =; i < bufferSize; ++i) { | |
| buffer[i] -= min; // 经过这一步,buffer中所有的都是正数 | |
| maxDelta |= buffer[i]; | |
| } | |
| meta.writeLong(min); | |
| meta.writeInt(Float.floatToIntBits(avgInc)); | |
| meta.writeLong(data.getFilePointer() - baseDataPointer); | |
| if (maxDelta ==) { // 经过预处理之后,所有的值都相等 | |
| meta.writeByte((byte)); | |
| } else { // 使用DirectWriter来进行编码 | |
| final int bitsRequired = DirectWriter.unsignedBitsRequired(maxDelta); | |
| DirectWriter writer = DirectWriter.getInstance(data, bufferSize, bitsRequired); | |
| for (int i =; i < bufferSize; ++i) { | |
| writer.add(buffer[i]); | |
| } | |
| writer.finish(); | |
| meta.writeByte((byte) bitsRequired); | |
| } | |
| bufferSize =; | |
| } | |
| public void add(long v) throws IOException { | |
| if (v < previous) { // 如果不是递增的,则不应该使用DirectMonotonicWriter | |
| throw new IllegalArgumentException("Values do not come in order: " + previous + ", " + v); | |
| } | |
| if (bufferSize == buffer.length) { // buffer满了 | |
| flush(); | |
| } | |
| buffer[bufferSize++] = v; | |
| previous = v; | |
| count++; | |
| } | |
| public void finish() throws IOException { | |
| if (count != numValues) { | |
| throw new IllegalStateException( | |
| "Wrong number of values added, expected: " + numValues + ", got: " + count); | |
| } | |
| if (finished) { | |
| throw new IllegalStateException("#finish has been called already"); | |
| } | |
| if (bufferSize >) { // 如果还有数据,则先编码 | |
| flush(); | |
| } | |
| finished = true; | |
| } | |
| } |
总结
之前在看索引文件构建的源码时,会经常碰到对于正整数的批量压缩应用,而且有好几个不同的类,当时都是把它们当成黑盒忽略,现在花了点时间,总算是把这些不同应用场景都区分了。本文没有罗列Lucene中全部的编码压缩应用,后面如果有再碰到影响我看源码的压缩相关的,我会补充进来。