目录
- 背景
- kfifo实现
- 无锁
- 快速取余
- 数据结构
- Push()
- Pop()
- 性能测试
- 无界环形缓冲器
- Push()
- grow()
- 线程安全性
- 代码地址
背景
环形缓冲器(ringr buffer)是一种用于表示一个固定尺寸、头尾相连的缓冲区的数据结构,适合缓存数据流。
在使用上,它就是一个固定长度的FIFO队列:

在逻辑上,我们可以把它当成是一个环,上面有两个指针代表当前写索引和读索引:
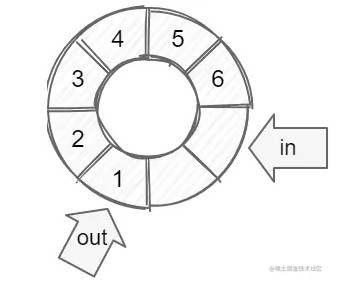
在实现上,我们一般是使用一个数组去实现这个环,当索引到达数组尾部的时候,则重新设置为头部:

kfifo实现
kfifo是Linux内核的队列实现,它具有以下特性:
- 固定长度:长度是固定的,而且是向上取最小的2的平方,主要是为了实现快速取余。
- 无锁:在单生产者和单消费者的情况下,是不需要加锁的。主要是因为索引in和out是不回退的,一直往前。
- 快速取余:我们都直到到达队列末尾的时候,索引需要回退到开头。最简单的实现方式就是对索引取余,比如索引in现在是8,队列长度是8,
in%len(q)即可回退到开头,但是取余操作%还是比较耗时的,因此kfifo使用in&mask实现快速取余,其中mask=len(q)-1。
无锁
上面我们说到,这个无锁是有条件的,也就是必须在单生产者单消费者情况下。这种情况下,同一时刻最多只可能会有一个写操作和一个读操作。但是在某一个读操作(或写操作)的期间,可能会有多个写操作(或读操作)发生。
因为索引in和out是不回退的,因此in一直会在out前面(或者重合)。而且in只被写操作修改,out只被读操作修改,因此不会冲突。
这里可能有人会担心索引溢出的问题,比如in到达math.MaxUint64,再+1则回到0。但是其实并不影响in和out之间的距离:
package main
import (
"fmt"
"math"
)
func main() {
var in uint = math.MaxUint64
var out uint = math.MaxUint64 - 1
fmt.Println(in - out) // 1
in++
fmt.Println(in - out) // 2
out++
fmt.Println(in - out) // 1
}
当然如果连续两次溢出,就会出现问题。但是由于数组长度是int类型,因此也没办法超过math.MaxUint64,也就是in和out之间的距离最多也就是2^62,因为math.MaxInt64是2^63-1,没办法向上取2的平方了。因此也不会出现溢出两倍math.MaxUint64的情况,早在溢出之前就队列满了。
快速取余
前面提到取余是通过in&mask实现的,这有一个前提条件,也就是长度必须是2的次方,因此在创建数组的时候,长度会向上取最小的2的平方。例如一个长度为8的kfifo,在二进制表示下:
len = 0000 1000 // 十进制8,队列长度
mask = 0000 0111 // 十进制7,掩码
in = 0000 0000 // 十进制0,写索引
in & mask => 0000 0000 // 十进制0,使用 & mask
in % len => 0000 0000 // 十进制0,使用 % len
in = 0000 0001 // 十进制1,写索引
in & mask => 0000 0001 // 十进制1,使用 & mask
in % len => 0000 0001 // 十进制1,使用 % len
in = 0000 0001 // 十进制1,写索引
in & mask => 0000 0001 // 十进制1,使用 & mask
in % len => 0000 0001 // 十进制1,使用 % len
in = 0000 1000 // 十进制8,写索引
in & mask => 0000 0000 // 十进制0,使用 & mask
in % len => 0000 0000 // 十进制0,使用 % len
in = 0001 0001 // 十进制17,写索引
in & mask => 0000 0001 // 十进制1,使用 & mask
in % len => 0000 0001 // 十进制1,使用 % len
可以看到,使用& mask的效果是和% len一样的。
然后我们做一个简单的性能测试:
package main
import "testing"
var (
Len = 8
Mask = Len - 1
In = 8 - 5
)
// % len
func BenchmarkModLen(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = In % Len
}
}
// & Mask
func BenchmarkAndMask(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = In & Mask
}
}
测试结果:
BenchmarkModLen-8 1000000000 0.3434 ns/op
BenchmarkAndMask-8 1000000000 0.2520 ns/op
可以看到& mask性能确实比% len好很多,这也就是为什么要用& Mask来实现取余的原因了。
数据结构
数据结构和上面介绍的一样,in、out标识当前读写的位置;mask是size-1,用于取索引,比%size更加高效;
type Ring[T any] struct {
in uint64 // 写索引
out uint64 // 读索引
mask uint64 // 掩码,用于取索引,代替%size
size uint64 // 长度
data []T // 数据
}
Push()
Push()操作很简单,首先r.in & r.mask得到写索引,让写索引前进一格,然后存入数据。
// 插入元素到队尾
func (r *Ring[T]) Push(e T) {
if r.Full() {
panic("ring full")
}
in := r.in & r.mask
r.in++
r.data[in] = e
}
Pop()
Pop()操作同理,根据r.out & r.mask得到读索引,让读索引前进一格,然后读取数据。
// 弹出队头元素
func (r *Ring[T]) Pop() T {
if r.Empty() {
panic("ring emtpy")
}
out := r.out & r.mask
r.out++
return r.data[out]
}
性能测试
Round实现是使用& mask,同时长度会向上取2的平方;Fix实现是使用% size保持参数的长度。
测试代码是不断的Push()然后Pop():
func BenchmarkRoundPushPop(b *testing.B) {
for i := 0; i < b.N; i++ {
r := New[int](RoundFixSize)
for j := 0; j < RoundFixSize; j++ {
r.Push(j)
}
for j := 0; j < RoundFixSize; j++ {
r.Pop()
}
}
}
测试结果:& mask的性能明显好于% size。
BenchmarkRoundPushPop-8 2544 405621 ns/op // & mask
BenchmarkFixPushPop-8 678 1740489 ns/op // % size
无界环形缓冲器
我们可以在写数据的时候判断是否空间已满,如果已满我们可以进行动态扩容,从而实现一个无界环形缓冲器。
Push()
在Push()时检查到空间满时,调用grow()扩展空间即可:
// 插入元素到队尾
func (r *Ring[T]) Push(e T) {
if r.Full() {
// 扩展空间
r.Grow(r.Cap() + 1)
}
in := r.in % r.size
r.in++
r.data[in] = e
}
grow()
扩容一般是扩展为当前容量的两倍,然后把原来数据copy()到新的数组,更新字段即可:
// 扩容
func (r *Ring[T]) Grow(minSize uint64) {
size := mmath.Max(r.size*2, minSize)
if size > MaxSize {
panic("size is too large")
}
if size < 2 {
size = 2
}
// 还没容量,直接申请,因为不需要迁移元素
if r.size == 0 {
r.data = make([]T, size)
r.size = size
return
}
data := make([]T, size)
out := r.out % r.size
len := r.Len()
copied := copy(data[:len], r.data[out:])
copy(data[copied:len], r.data)
r.out = 0
r.in = len
r.size = size
r.data = data
}
线程安全性
由于可能会动态扩容,需要修改out、in指针,因此需要加锁保证安全。
代码地址
https://github.com/jiaxwu/gommon/tree/main/container/ringbuffer