前言
中国有句老话叫”事不过三”,指一个人犯了同样的错误,一次两次还可以原谅,再多就不可原谅了。写代码也是如此,同一个代码“坑”,踩第一次叫”长了经验”,踩第二次叫”加深印象”,踩第三次叫”不长记性”,踩三次以上就叫”不可救药”。在本文中,笔者总结了一些 java 坑,描述了问题现象,进行了问题分析,给出了避坑方法。希望大家在日常工作中,遇到了这类 Java 坑,能够提前避让开来。
1 对象比较方法
JDK 1.7 提供的 Objects.equals 方法,非常方便地实现了对象的比较,有效地避免了繁琐的空指针检查。
问题现象
在 JDK1.7 之前,在判断一个短整型、整型、长整型包装数据类型与常量是否相等时,我们一般这样写:
short shortValue = (short)12345;
System.out.println(shortValue ==); // true Integer
intValue =;
System.out.println(intValue ==); // trueLong
longValue =L;
System.out.println(longValue ==); // true
从 JDK1.7 之后,提供了 Object s.equals 方法,并推荐使用函数式编程,更改代码如下:
Short shortValue = (short);
System.out.println(Objects.equals(shortValue,)); // false
Integer intValue =;
System.out.println(Objects.equals(intValue,)); // true
Long longValue =L;
System.out.println(Objects.equals(longValue,)); // false
为什么直接把 == 替换为 Objects.equals 方法就会导致输出结果不一样?
问题分析
通过反编译第一段代码,我们得到语句 System.out.println(shortValue == 12345); 的 字节码 指令如下:
getstatic java.lang.System.out : java.io.PrintStream []
aload_ [shortValue]
invokevirtual java.lang.Short.shortValue() : short []
sipush
if_icmpne
iconst_
goto
iconst_
invokevirtual java.io.PrintStream.println( boolean ) : void [32]
原来,编译器会判断包装数据类型对应的基本数据类型,并采用这个基本数据类型的指令进行比较(比如上面字节码指令中的 sipush 和 if_icmpne 等),相当于编译器自动对常量进行了数据类型的强制转化。
为什么采用 Objects.equals 方法后,编译器不自动对常量进行数据类型的强制转化?通过反编译第二段代码,我们得到语句 System.out.println(Objects.equals(shortValue, 12345)); 的字节码指令如下:
getstatic java.lang.System.out : java.io.PrintStream []
aload_ [shortValue]
sipush
invokestatic java.lang.Integer.valueOf(int) : java.lang.Integer []
invokestatic java.util.Objects.equals(java.lang.Object, java.lang.Object) : boolean []
invokevirtual java.io.PrintStream.println(boolean) : void []
原来,编译器根据字面意思,认为常量 12345 默认基本数据类型是 int,所以会自动转化为包装数据类型 Integer。
在 Java 语言中,整数的默认数据类型是 int,小数的默认数据类型是 double 。
通过分析 Objects.equals 方法的源代码可知:语句 System.out.println(Objects.equals(shortValue, 12345)) ,因为 Objects.equals 的两个参数对象类型不一致,一个是包装数据类型 Short,另一个是包装数据类型 Integer,所以最终的比较结果必然是false;而语句 System.out.println(Objects.equals(intValue, 12345)) ,因为 Objects.equals 的两个参数对象类型一致,都是包装数据类型 Integer 且取值相同,所以最终的比较结果必然是 true。
避坑方法
1)保持良好的 编码 习惯,避免数据类型的自动转化
为了避免数据类型自动转化,更科学的写法是直接声明常量为对应的基本数据类型。
第一段代码可以这样写:
Short shortValue = (short);
System.out.println(shortValue == (short)); // true
Integer intValue =;
System.out.println(intValue ==); // true
Long longValue =L;
System.out.println(longValue ==L); // true
第二段代码可以这样写:
Short shortValue = (short);
System.out.println(Objects.equals(shortValue, (short))); // true
Integer intValue =;
System.out.println(Objects.equals(intValue,)); // true
Long longValue =L;
System.out.println(Objects.equals(longValue,L)); // true
2)借助开发工具或插件,及早地发现数据类型不匹配问题
在 Eclipse 的问题窗口中,我们会看到这样的提示:
Unlikely argument type for equals(): int seems to be unrelated to Short
Unlikely argument type for equals(): int seems to be unrelated to Long
3)进行常规性单元测试,尽量把问题发现在研发阶段
“勿以善小而不为”,不要因为改动很小就不需要进行单元测试了,往往 Bug 都出现在自己过度自信的代码中。像这种问题,只要进行一次单元测试,是完全可以发现问题的。
注意:进行必要单元测试,适用于以下所有案例,所以下文不再累述。
2 三元表达式拆包
三元表达式是 Java 编码中的一个固定语法格式:
条件表达式?表达式:表达式2
三元表达式的逻辑为:如果条件表达式成立,则执行表达式 1,否则执行表达式 2。
问题现象
boolean condition = false;
Double value = 1.0D;
Double value = 2.0D;
Double value = null;
Double result = condition ? value * value2 : value3; // 抛出空指针异常
当条件表达式 condition 等于 false 时,直接把 Double 对象 value3 赋值给 Double 对象 result,按道理没有任何问题,为什么会抛出空指针异常?
问题分析
通过反编译代码,我们得到语句:
Double result = condition ? value * value2 : value3;
的字节码指令如下:
iload_ [condition] ifeq aload_ [value1] invokevirtual java.lang.Double.doubleValue() : double [] aload_ [value2] invokevirtual java.lang.Double.doubleValue() : double [] dmul goto aload [value3] invokevirtual java.lang.Double.doubleValue() : double [] invokestatic java.lang.Double.valueOf(double) : java.lang.Double [] astore [result]
在第 9 行,加载 Double 对象 value 3 到操作数栈中;在第 10 行,调用 Double 对象 value 3 的 doubleValue 方法。这个时候,由于 value 3 是空对象 null,调用 doubleValue 方法必然抛出抛出空指针异常。但是,为什么要把空对象 value 3 转化为基础数据类型 double 呢?
查阅相关资料,得到三元表达式的类型转化规则:
- 若两个表达式类型相同,返回值类型为该类型;
- 若两个表达式类型不同,但类型不可转换,返回值类型为 Object 类型;
- 若两个表达式类型不同,但类型可以转化,先把包装数据类型转化为基本数据类型,然后按照基本数据类型的转换规则 (byte < short(char)< int < long < float < double) 来转化,返回值类型为优先级最高的基本数据类型。
根据规则分析,表达式 1(value1 * value2)的类型为基础数据类型 double,表达式 2(value 3)的类型为包装数据类型 Double,根据三元表达式的类型转化规则判断,最终的表达式类型为基础数据类型 double。所以,当条件表达式 condition 为 false 时,需要把空 Double 对象 value 3 转化为基础数据类型 double,于是就调用了 value 3 的 doubleValue 方法进行拆包,当然会抛出空指针异常。
避坑方法
1)尽量避免使用三元表达式,可以采用 if-else 语句代替
如果三元表达式中有包装数据类型的算术计算,可以考虑利用 if-else 语句代替。改写代码如下:
if (condition) {
result = value * value2;
} else {
result = value;}
2)尽量使用基本数据类型,避免包装数据类型的拆装包
如果在三元表达式中有算 术 计算,尽量使用基本数据类型,避免包装数据类型的拆装包。改写代码如下:
boolean condition = false;
double value = 1.0D;
double value = 2.0D;
double value = 3.0D;
double result = condition ? value * value2 : value3;
3 泛型对象赋值
Java 泛型是 JDK 1.5 中引入的一个新特性,其本质是参数化类型,即把数据类型 做为 一个参数使用。
问题现象
在做用户数据分页查询时,因为笔误编写了如下代码:
1)PageDataVO.java
/** 分页数据VO类 */@Getter
@Setter
@ToString
@NoArgsConstructor
@AllArgsConstructor
public class PageDataVO<T> {
/** 总共数量 */
private Long totalCount;
/** 数据列表 */
private List<T> dataList;
}
2)UserDAO.java
/** 用户DAO接口 */@Mapper
public interface UserDAO {
/** 统计用户数量 */
public Long countUser(@Param("query") UserQueryVO query);
/** 查询用户信息 */
public List<UserDO> queryUser(@Param("query") UserQueryVO query);}
3)UserService.java
/** 用户服务类 */@Service
public class UserService {
/** 用户DAO */ @Autowired
private UserDAO userDAO;
/** 查询用户信息 */
public PageDataVO<UserVO> queryUser(UserQueryVO query) { List<UserDO> dataList = null;
Long totalCount = userDAO.countUser(query);
if (Objects.nonNull(totalCount) && totalCount.compareTo(L) > 0) {
dataList = userDAO.queryUser(query);
}
return new PageDataVO(totalCount, dataList);
}
}
以上代码没有任何编译问题,但是却把 UserDO 中一些涉密字段返回给前端。细心的读者可能已经发现了,在 UserService 类的 queryUser 方法的语句 return new PageDataVO(totalCount, dataList); 中,我们把 List<UserDO> 对象 dataList 赋值给了 PageDataVO<UserVO> 的 List<UserVO> 字段 dataList。
问题是:为什么开发工具不报编译错误啦?
问题分析
由于历史原因,参数化类型和原始类型需要兼容。我们以 ArrayList 举例子,来看看如何兼容的。
以前的写法:
ArrayList list = new ArrayList();
现在的写法:
ArrayList<String> list = new ArrayList<String>();
考虑到与以前的代码兼容,各种对象引用之间传值,必然会出现以下的情况:
// 第一种情况
ArrayList list = new ArrayList<String>();
// 第二种情况
ArrayList<String> list = new ArrayList();
所以,Java 编译器对以上两种类型进行了兼容,不会出现编译错误,但会出现编译告警。但是,我的开发工具在编译时真没出现过告警。
再来分析我们遇到的问题,实际上同时命中了两种情况:
- 把 List<UserDO> 对象赋值给 List,命中了第一种情况.
- 把 PageDataVO 对象赋值给 PageDataVO<UserVO>,命中了第二种情况。
- 最终的效果就是:我们神奇地把 List<UserDO> 对象赋值给了 List<UserVO>。
- 问题的根源就是:我们在初始化 PageDataVO 对象时,没有要求强制进行类型检查。
避坑方法
1)在初始化泛型对象时,推荐使用 diamond 语法
在《 Java 开发手册》中,有这么一条推荐规则:
正例:
// <> diamond 方式
HashMap<String, String> userCache = new HashMap<>();
// 全省略方式ArrayList<User> users = new ArrayList();
其实,初始化泛型对象时,全省略是不推荐的。这样会避免类型检查,从而造成上面的问题。
在初始化泛型对象时,推荐使用 diamond 语法,代码如下:
return new PageDataVO<>(totalCount, dataList);
现在,在 Eclipse 的问题窗口中,我们会看到这样的错误:
Cannot infer type arguments for PageDataVO<>
于是,我们就知道忘记把 List<UserDO> 对象转化为 List<UserVO> 对象了。
4 泛型属性拷贝
Spring 的 BeanUtils.copyProperties 方法,是一个很好用的属性拷贝工具方法。
问题现象
根据数据库开发规范,数据库表格必须包含 id,gmt_create,gmt_modified 三个字段。其中,id 这个字段,可能根据数据量不同,采用 int 或 long 类型。
首先,定义了一个 BaseDO 基类:
/** 基础DO类 */@Getter
@Setter
@ToString
public class BaseDO<T> {
private T id;
private Date gmtCreate;
private Date gmtModified;}
针对 user 表,定义了一个 UserDO 类:
/** 用户DO */@Getter
@Setter
@ToString
public static class UserDO extends BaseDO<Long> {
private String name;
private String description;
}
对于查询接口,定义了一个 UserVO 类:
/** 用户VO类 */@Getter
@Setter
@ToString
public static class UserVO {
private Long id;
private String name; private String description;
}
实现查询用户服务接口,实现代码如下:
/** 用户服务类 */@Service
public class UserService {
/** 用户DAO */
@Autowired
private UserDAO userDAO;
/** 查询用户 */
public List<UserVO> queryUser(UserQueryVO query) {
// 查询用户信息
List<UserDO> userDOList = userDAO.queryUser(query);
if (CollectionUtils.isEmpty()) {
return Collections.emptyList();
}
// 转化用户列表
List<UserVO> userVOList = new ArrayList<>(userDOList.size());
for (UserDO userDO : userDOList) {
UserVO userVO = new UserVO();
BeanUtils.copyProperties(userDO, userVO);
userVOList.add(userVO);
}
// 返回用户列表
return userVOList;
}
}
通过测试,我们会发现一个问题——调用查询用户服务接口,用户 ID 的值并没有返回。
[{"description":"This is a tester.","name":"tester"},...]
问题分析
通过 Debug 模式运行,进入到 BeanUtils.copyProperties 工具方法内部,得到以下内容:
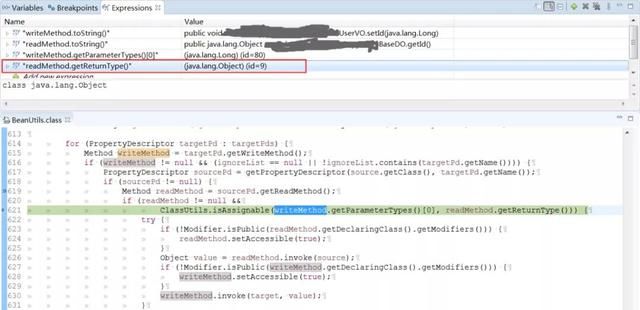
原来,UserDO 类的 getId 方法返回类型不是 Long 类型,而是被泛型还原成了 Object 类型。而下面的 ClassUtils.isAssignable 工具方法,判断是否能够把 Object 类型赋值给 Long 类型,当然会返回false导致不能进行属性拷贝。
为什么作者不考虑”先获取属性值,再判断能否赋值”?建议代码如下:
Object value = readMethod.invoke(source);
if (Objects.nonNull(value) &&
ClassUtils.isAssignable(writeMethod.getParameterTypes()[], value.getClass())) {
... // 赋值相关代码}
避坑方法
1)不要盲目地相信第三方工具包,任何工具包都有可能存在问题
在 Java 中,存在很多第三方工具包,比如:Apache 的 commons-lang3、commons-collections,Google 的 guava……都是很好用的第三方工具包。但是,不要盲目地相信第三方工具包,任何工具包都有可能存在问题。
2)如果需要拷贝的属性较少,可以手动编码进行属性拷贝
用 BeanUtils.copyProperties 反射拷贝属性,主要优点是节省了代码量,主要缺点是导致程序性能下降。所以,如果需要拷贝的属性较少,可以手动编码进行属性拷贝。
5 Set 对象排重
在 Java 语言中,Set 数据结构可以用于对象排重,常见的 Set 类有 HashSet、LinkedHashSet 等。
问题现象
编写了一个城市辅助类,从 CSV 文件中读取城市数据:
/** 城市辅助类 */@Slfjpublic class CityHelper {
/** 读取城市 */
public static Collection<City> readCities(String fileName) {
try (FileInputStream stream = new FileInputStream(fileName);
InputStreamReader reader = new InputStreamReader(stream, "GBK");
CSVParser parser = new CSVParser(reader, CSVFormat.DEFAULT.withHeader())) {
Set<City> citySet = new HashSet<>();
Iterator<CSVRecord> iterator = parser.iterator();
while (iterator.hasNext()) {
citySet.add(parseCity(iterator.next()));
}
return citySet;
} catch (IOException e) {
log.warn("读取所有城市异常", e);
}
return Collections.emptyList();
}
/** 解析城市 */ private static City parseCity(CSVRecord record) {
City city = new City();
city.setCode(record.get());
city.setName(record.get());
return city;
}
/** 城市类 */
@Getter
@Setter
@ToString
private static class City {
/** 城市编码 */
private String code;
/** 城市名称 */
private String name;
}
}
代码中使用 HashSet 数据结构,目的是为了避免城市数据重复,对读取的城市数据进行强制排重。
当输入文件内容如下时:
编码,名称,北京 ,广州 ,北京
解析后的 JSON 结果如下:
[{"code":"","name":"北京"},{"code":"020","name":"广州"},{"code":"010","name":"北京"}]
但是,并没有对城市“北京”进行排重。
问题分析
当向集合 Set 中增加对象时,首先集合计算要增加对象的 hashCode,根据该值来得到一个位置用来存放当前对象。如在该位置没有一个对象存在的话,那么集合 Set 认为该对象在集合中不存在,直接增加进去。如果在该位置有一个对象存在的话,接着将准备增加到集合中的对象与该位置上的对象进行 equals 方法比较:如果该 equals 方法返回 false,那么集合认为集合中不存在该对象,就把该对象放在这个对象之后;如果 equals 方法返回 true,那么就认为集合中已经存在该对象了,就不会再将该对象增加到集合中了。所以,在哈希表中判断两个元素是否重复要使用到 hashCode 方法和 equals 方法。hashCode 方法决定数据在表中的存储位置,而 equals 方法判断表中是否存在相同的数据。
分析上面的问题,由于没有重写 City 类的 hashCode 方法和 equals 方法,就会采用 Object 类的 hashCode 方法和 equals 方法。其实现如下:
public native int hashCode();
public boolean equals(Object obj) {
return (this == obj);
}
可以看出:Object 类的 hashCode 方法是一个本地方法,返回的是对象地址;Object 类的 equals 方法只比较对象是否相等。所以,对于两条完全一样的北京数据,由于在解析时初始化了不同的 City 对象,导致 hashCode 方法和 equals 方法值都不一样,必然被 Set 认为是不同的对象,所以没有进行排重。
那么,我们就重写把 City 类的 hashCode 方法和 equals 方法,代码如下:
/** 城市类 */@Getter
@Setter
@ToStringprivate static class City {
/** 城市编码 */
private String code;
/** 城市名称 */ private String name;
/** 判断相等 */
@Override public boolean equals(Object obj) {
if (obj == this) {
return true;
}
if (Objects.isNull(obj)) {
return false;
}
if (obj.getClass() != this.getClass()) {
return false;
}
return Objects.equals(this.code, ((City)obj).code);
}
/** 哈希编码 */
@Override
public int hashCode() {
return Objects.hashCode(this.code);
}
}
重新支持测试程序,解析后的 JSON 结果如下:
[{"code":"","name":"北京"},{"code":"020","name":"广州"}]
结果正确,已经对城市“北京”进行排重。
避坑方法
1)当确定数据唯一时,可以使用 List 代替 Set
当确定解析的城市数据唯一时,就没有必要进行排重操作,可以直接使用 List 来存储。
List<City> citySet = new ArrayList<>();
Iterator<CSVRecord> iterator = parser.iterator();
while (iterator.hasNext()) {
citySet.add(parseCity(iterator.next()));
}
return citySet;
2)当确定数据不唯一时,可以使用 Map 代替 Set
当确定解析的城市数据不唯一时,需要安装城市名称进行排重操作,可以直接使用 Map 进行存储。为什么不建议实现 City 类的 hashCode 方法,再采用 HashSet 来实现排重呢?首先,不希望把业务逻辑放在模型 DO 类中;其次,把排重字段放在代码中,便于代码的阅读、理解和维护。
Map<String, City> cityMap = new HashMap<>();
Iterator<CSVRecord> iterator = parser.iterator();
while (iterator.hasNext()) {
City city = parseCity(iterator.next());
cityMap.put(city.getCode(), city);
}
return cityMap.values();
3)遵循 Java 语言规范,重写 hashCode 方法和 equals 方法
不重写 hashCode 方法和 equals 方法的自定义类不应该在 Set 中使用。
6 公有方法代理
SpringCGLIB 代理生成的代理类是一个继承被代理类,通过重写被代理类中的非 final 的方法实现代理。所以,SpringCGLIB 代理的类不能是 final 类,代理的方法也不能是 final 方法,这是由继承机制限制的。
问题现象
这里举例一个简单的例子,只有超级用户才有删除公司的权限,并且所有服务函数被 AOP 拦截处理异常。例子代码如下:
1)UserService.java
/** 用户服务类 */@Servicepublic class UserService {
/** 超级用户 */
private User superUser;
/** 设置超级用户 */
public void setSuperUser(User superUser) {
this.superUser = superUser;
}
/** 获取超级用户 */
public final User getSuperUser() {
return this.superUser;
}
}
2)CompanyService.java
/** 公司服务类 */@Servicepublic
class CompanyService {
/** 公司DAO */
@Autowired
private CompanyDAO companyDAO;
/** 用户服务 */ @Autowired
private UserService userService;
/** 删除公司 */
public void deleteCompany(Long companyId, Long operatorId) {
// 设置超级用户
userService.setSuperUser(new User(L, "admin", "超级用户"));
// 验证超级用户
if (!Objects.equals(operatorId, userService.getSuperUser().getId())) {
throw new ExampleException("只有超级用户才能删除公司");
}
// 删除公司信息
companyDAO.delete(companyId, operatorId);
}
}
当我们调用 CompanyService 的 deleteCompany 方法时,居然也抛出空指针异常 (NullPointerException),因为调用 UserService 类的 getSuperUser 方法获取的超级用户为 null。但是,我们在 CompanyService 类的 deleteCompany 方法中,每次都通过 UserService 类的 setSuperUser 方法强制指定了超级用户,按道理通过 UserService 类的 getSuperUser 方法获取到的超级用户不应该为 null。其实,这个问题也是由 AOP 代理导致的。
问题分析
使用 SpringCGLIB 代理类时,Spring 会创建一个名为 UserService$$EnhancerBySpringCGLIB$$???????? 的代理类。反编译这个代理类,得到以下主要代码:
public class UserService$$EnhancerBySpringCGLIB$$ac3b345 extends UserService implements SpringProxy, Advised, Factory {
......
public final void setSuperUser(User var) {
MethodInterceptor var = this.CGLIB$CALLBACK_0;
if (var == null) {
CGLIB$BIND_CALLBACKS(this);
var = this.CGLIB$CALLBACK_0;
}
if (var != null) {
var.intercept(this, CGLIB$setSuperUser$0$Method, new Object[]{var1}, CGLIB$setSuperUser$0$Proxy);
} else {
super.setSuperUser(var);
}
}
......
}
可以看出,这个代理类继承了 UserService 类,只代理了 setSuperUser 方法,但是没有代理 getSuperUser 方法。所以,当我们调用 setSuperUser 方法时,设置的是原始对象实例的 superUser 字段值;而当我们调用 getSuperUser 方法时,获取的是代理对象实例的 superUser 字段值。如果把这两个方法的 final 修饰符互换,同样存在获取超级用户为 null 的问题。
避坑方法
1)严格遵循 CGLIB 代理规范,被代理的类和方法不要加 final 修饰符
严格遵循 CGLIB 代理规范,被代理的类和方法不要加 final 修饰符,避免动态代理操作对象实例不同(原始对象实例和代理对象实例),从而导致数据不一致或空指针问题。
2)缩小 CGLIB 代理类的范围,能不用被代理的类就不要被代理
缩小 CGLIB 代理类的范围,能不用被代理的类就不要被代理,即可以节省内存开销,又可以提高函数调用效率。
7 公有字段代理
在 fastjson 强制升级到 1.2.60 时踩过一个坑,作者为了开发快速,在 ParseConfig 中定义了:
public class ParseConfig {
public final SymbolTable symbolTable = new SymbolTable();
......
}
在我们的项目中继承了该类,同时又被 AOP 动态代理了,于是一行代码引起了一场“血案”。
问题现象
仍然使用上章的例子,但是把获取、设置方法删除,定义了一个公有字段。例子代码如下:
1)UserService.java
/** 用户服务类 */@Servicepublic
class UserService {
/** 超级用户 */
public final User superUser = new User(L, "admin", "超级用户");
......
}
2)CompanyService.java
/** 公司服务类 */@Servicepublic
class CompanyService {
/** 公司DAO */
@Autowired
private CompanyDAO companyDAO;
/** 用户服务 */
@Autowired
private UserService userService;
/** 删除公司 */
public void deleteCompany(Long companyId, Long operatorId) {
// 验证超级用户
if (!Objects.equals(operatorId, userService.superUser.getId())) {
throw new ExampleException("只有超级用户才能删除公司");
}
// 删除公司信息
companyDAO.delete(companyId, operatorId);
}
}
当我们调用 CompanyService 的 deleteCompany 方法时,居然抛出空指针异常 (NullPointerException)。经过调试打印,发现是 UserService 的 superUser 变量为 null。如果把代理删除,就不会出现空指针异常,说明这个问题是由 AOP 代理导致的。
问题分析
使用 SpringCGLIB 代理类时,Spring 会创建一个名为 UserService$$EnhancerBySpringCGLIB$$???????? 的代理类。这个代理类继承了 UserService 类,并覆盖了 UserService 类中的所有非 final 的 public 的方法。但是,这个代理类并不调用 super 基类的方法;相反,它会创建的一个成员 userService 并指向原始的 UserService 类对象实例。现在,内存中存在两个对象实例:一个是原始的 UserService 对象实例,另一个指向 UserService 的代理对象实例。这个代理类只是一个虚拟代理,它继承了 UserService 类,并且具有与 UserService 相同的字段,但是它从来不会去初始化和使用它们。所以,一但通过这个代理类对象实例获取公有成员变量时,将返回一个默认值 null。

避坑方法
1)当确定字段不可变时,可以定义为公有静态常量
当确定字段不可变时,可以定义为公有静态常量,并用类名称 + 字段名称访问。类名称 + 字段名称访问公有静态常量,与类实例的动态代理无关。
2)当确定字段不可变时,可以定义为私有成员变量
当确定字段不可变时,可以定义为私有成员变量,提供一个公有 Getter 方法获取该变量值。当该类实例被动态代理时,代理方法会调用被代理的 Getter 方法,从而返回被代理类的成员变量值。
3)遵循 JavaBean 编码规范,不要定义公有成员变量
遵循 JavaBean 编码规范,不要定义公有成员变量。JavaBean 规范如下:
- JavaBean 类必须是一个公共类,并将其访问属性设置为 public,如: public class User{……}
- JavaBean 类必须有一个空的构造函数:类中必须有一个不带参数的公用构造器
- 一个 JavaBean 类不应有公共实例变量,类变量都为 private,如: private Integer id
- 属性应该通过一组 getter / setter 方法来访问
后记
最后,推荐大家阅读一下《Java 开发手册》,这本手册让我受益匪浅。只要学习理解了《Java 开发手册》,就能在日常的 Java 开发工作中,避免踩到很多常识性的 Java 坑。