简介
2023 年 12 月 31 日,vue2 已经停止维护了。你还不会 Vue3 的源码么?
手把手带你实现一个 vue3 响应式系统,你将获得:
- Vue3 的响应式的数据结构是什么样?为什么是这样?如何形成的?
- Proxy 为什么要配合 Reflect 使用?如果不配合会有什么问题?
- Map 与 WeakMap的区别
- 响应式数据以及副作用函数
- 响应式系统基本实现
- 依赖收集
- 派发更新
- 依赖清理
- 支持嵌套
- 实现执行调度
- 实现 computed
- 实现 watch
- TDD 测试驱动开发
- 重构
- vitest 的使用
- 如何使用 ChatGPT 编写单元测试
- excalidraw 画图工具
代码地址: https://github.com/SuYxh/share-vue3
代码并没有按照源码的方式去进行组织,目的是学习、实现 vue3 响应式系统的核心,用最少的代码去实现最核心的能力,减少我们的学习负担,并且所有的流程都会有配套的图片,图文 + 代码,让我们学习更加轻松、快乐。
每一个功能都会提交一个 commit ,大家可以切换查看,也顺便练习练习 git 的使用。
如果想看和 vue 源码结构类似的请看: https://github.com/SuYxh/mini-vue3
环境搭建
1、使用 vite 创建一个空模板,
pnpm init vite
2、然后安装 vitest
pnpm add -D vitest
为什么要安装 vitest?
❝测试驱动开发(TDD) 是一种渐进的开发方法,它结合了测试优先的开发,即在编写足够的产品代码以完成测试和重构之前编写测试。目标是编写有效的干净代码
配置测试命令:
| "scripts": { | |
| "test": "vitest" | |
| }, |
3、安装 vscode 插件 Vitest Runner

4、编写测试代码
新建一个main.js ,然后编写:
| export function add(a: number, b: number) { | |
| return a + b; | |
| } |
创建 /src/__tests__/main.spec.ts测试文件,写入:
❝测试文件的文件名最好包含 spec
| import { describe, it, expect } from 'vitest'; | |
| import { add } from '../main'; | |
| describe('add function', () => { | |
| it('adds two numbers', () => { | |
| expect(add(1, 2)).toBe(3); | |
| }); | |
| }); |
点击运行单测:
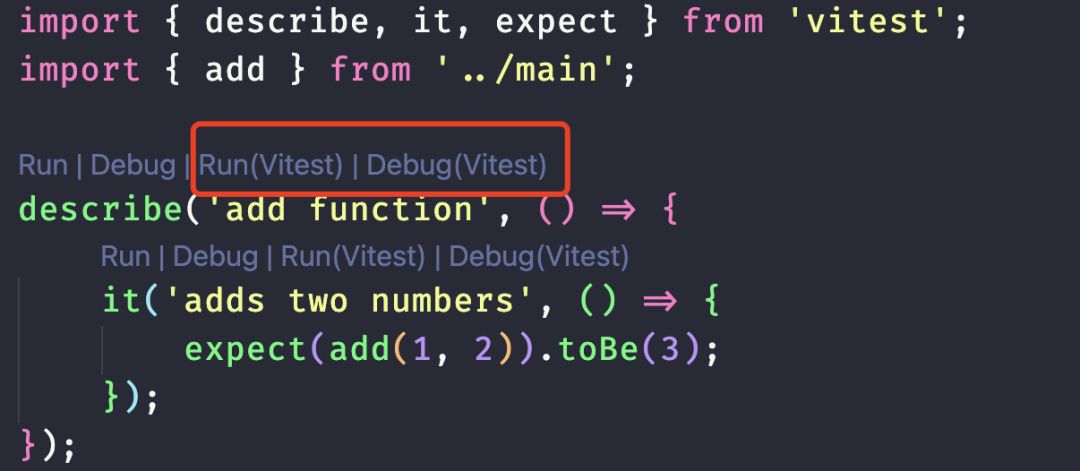
注意: 我这边因为还安装了 jest runner, 所有此处会有 2 对
运行结果:
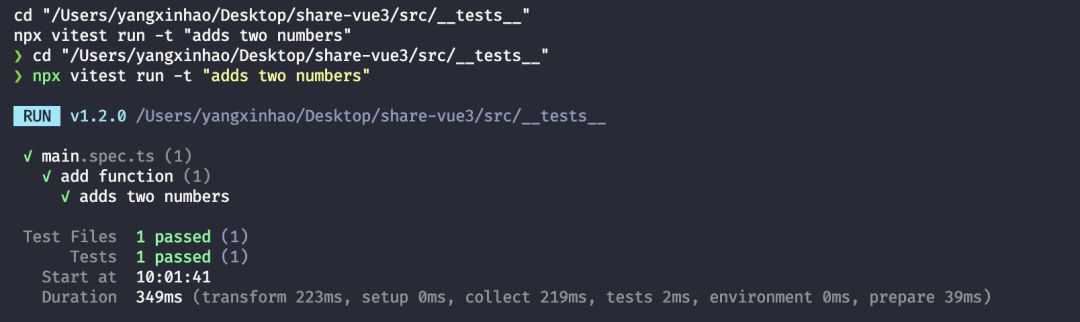
到此,环境搭建结束!
相关代码在 commit: (3af5e60)环境搭建 ,git checkout 3af5e60 即可查看。
响应式数据以及副作用函数
副作用函数指的是会产生副作用的函数,如下:
| // 全局变量 | |
| let val = 1 | |
| function effect() { | |
| // 修改全局变量,产生副作用 | |
| val = 2 | |
| } |
当 effect 函数执行时,它会修改 val 的值,但除了 effect 函数之外的任何函数都可以修改 val 的值。也就是说,effect函数的执行会直接或间接影响其他函数的执行,这时我们说 effect 函数产生了副作用。
假设在一个副作用函数中读取了某个对象的属性:
| const obj = { age: 18 } | |
| function effect() { | |
| console.log(obj.age) | |
| } |
当 obj.age 的值发生变化时,我们希望副作用函数 effect 会重新执行,如果能实现这个目标,那么对象 obj 就是响应式数据。但很明显,以上面的代码来看,我们还做不到这一点,因为 obj是一个普通对象,当我们修改它的值时,除了值本身发生变化之外,不会有任何其他反应。
响应式系统基本实现
如何将 obj 变成一个响应式对象呢?大家肯定都想到了 Object.defineProperty 和 Proxy 。
- 当副作用函数
effect执行时,会触发字段obj.age的读取操作; - 当修改
obj.age的值时,会触发字段obj.age的设置操作。
我们可以把副作用函数 effect 存储到一个“桶”里,如下图所示。
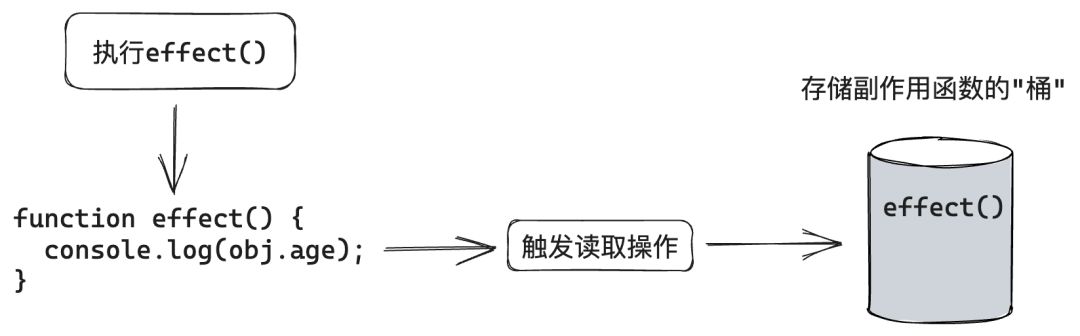
接着,当设置 obj.age 时,再把副作用函数 effect 从“桶”里取出并执行即可。
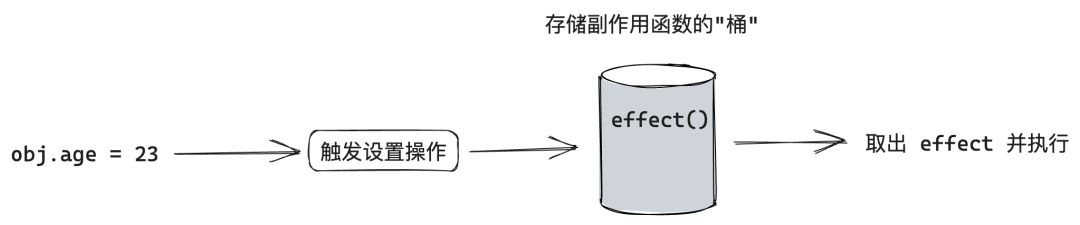
代码实现
| // 存储副作用函数的桶 | |
| const bucket = new Set(); | |
| // 原始数据 | |
| const data = { name: 'dahuang', age: 18 }; | |
| // 对原始数据的代理 | |
| const obj = new Proxy(data, { | |
| // 拦截读取操作 | |
| get(target, key) { | |
| // 将副作用函数 effect 添加到存储副作用函数的桶中 | |
| bucket.add(effect); | |
| // 返回属性值 | |
| return target[key]; | |
| }, | |
| // 拦截设置操作 | |
| set(target, key, newVal) { | |
| target[key] = newVal; | |
| bucket.forEach(fn => fn()); | |
| return true; | |
| } | |
| }); | |
| // 以下为测试代码 | |
| // 副作用函数 | |
| function effect() { | |
| console.log(obj.age); | |
| } | |
| // 执行副作用函数,触发读取 | |
| effect(); | |
| // 1 秒后修改响应式数据 | |
| setTimeout(() => { | |
| obj.age = 23; | |
| }, 1000); |
在浏览器中直接运行,我们可以得到期望的效果。
但目前的实现还存在一些问题:
- 直接通过名字
effect来获取副作用函数,如果名称变了怎么办? - 当我们在修改
name的时候,副作用函数依然会执行
后续会逐步解决这些问题,这里大家只需要理解响应式数据的基本实现和工作原理即可。
相关代码在 commit: (5fc5489)响应式系统基本实现 ,git checkout 5fc5489 即可查看。
完善的响应系统
解决硬编码副作用函数名字问题
为了实现这一点,我们需要提供一个用来注册副作用函数的机制,如以下代码所示:
| // 当前激活的副作用函数 | |
| let activeEffect = null; | |
| // 定义副作用函数 | |
| export function effect(fn) { | |
| // 设置当前激活的副作用函数 | |
| activeEffect = fn; | |
| // 执行副作用函数 | |
| fn(); | |
| // 重置当前激活的副作用函数 | |
| activeEffect = null; | |
| } |
首先,定义了一个全局变量 activeEffect,初始值是 null,它的作用是存储被注册的副作用函数。接着重新定义了 effect 函数,它变成了一个用来注册副作用函数的函数,effect 函数接收一个参数 fn,即要注册的副作用函数。我们可以按照如下所示的方式使用effect 函数:
| effect(() => { | |
| console.log(obj.age); | |
| }) |
如上面的代码所示,由于副作用函数已经存储到了activeEffect中,所以在get拦截函数内应该把 activeEffect收集到“桶”中,这样响应系统就不依赖副作用函数的名字了。
| get(target, key) { | |
| // 将 activeEffect 添加到存储副作用函数的桶中 | |
| if (activeEffect) { | |
| bucket.add(activeEffect); | |
| } | |
| // 返回属性值 | |
| return target[key]; | |
| }, |
相关代码在 commit: (80c9898)解决硬编码副作用函数名字问题 ,git checkout 80c9898 即可查看。
解决副作用函数会执行多次的问题
| effect(() => { | |
| console.log(obj.age); | |
| }) | |
| setTimeout(() => { | |
| obj.name = 'zhuanzhuan' | |
| }, 2000); |
在匿名副作用函数内并没有读取 obj.name 属性的值,所以理论上,字段 obj.name 并没有与副作用建立响应联系,因此, 修改 obj.name 属性的值不应该触发匿名副作用函数重新执行。但如果我们执行上述这段代码就会发现,定时器到时后,匿名副作用函数却重新执行了,这是不正确的。为了解决这个问题,我们需要重新设计“桶”的数据结构。
原因
没有在副作用函数与被操作的目标字段之间建立明确的联系。之前我们使用一个 Set 数据结构作为存储副作用函数的“桶”。无论读取的是哪一个属性,都会把副作用函数收集到“桶”里;当设置属性时,无论设置的是哪一个属性,也都会把“桶”里的副作用函数取出并执行。
解决
重新设计“桶”的数据结构,在副作用函数与被操作的字段之间建立联系
“桶”结构设计
我们需要先仔细观察下面的代码:
| effect(function effectFn() { | |
| console.log(obj.age); | |
| }) |
在这段代码中存在三个角色:
- 被操作(读取)的代理对象 obj
- 被操作(读取)的字段名 age
- 使用 effect 函数注册的副作用函数 effectFn
如果用 target 来表示一个代理对象所代理的原始对象,用 key 来表示被操作的字段名,用effectFn 来表示被注册的副作用函数,那么可以为这三个角色建立如下关系:
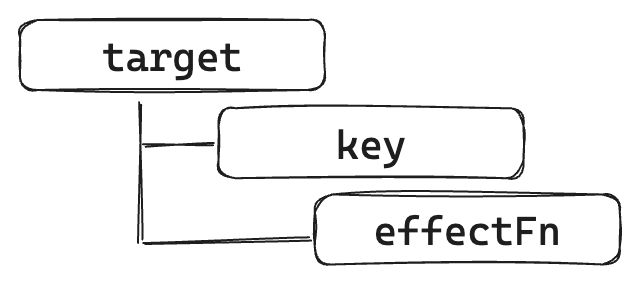
这是一种树型结构,下面举几个例子来对其进行补充说明。
如果有两个副作用函数同时读取同一个对象的属性值:
| effect(function effectFn1() { | |
| console.log(obj.age); | |
| }) | |
| effect(function effectFn2() { | |
| console.log(obj.age); | |
| }) |
那么关系如下:
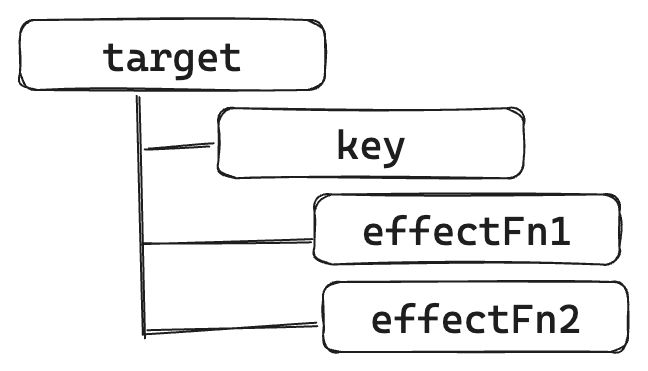
如果一个副作用函数中读取了同一个对象的两个不同属性
| effect(function effectFn1() { | |
| console.log(obj.age); | |
| console.log(obj.name); | |
| }) |
那么关系如下:
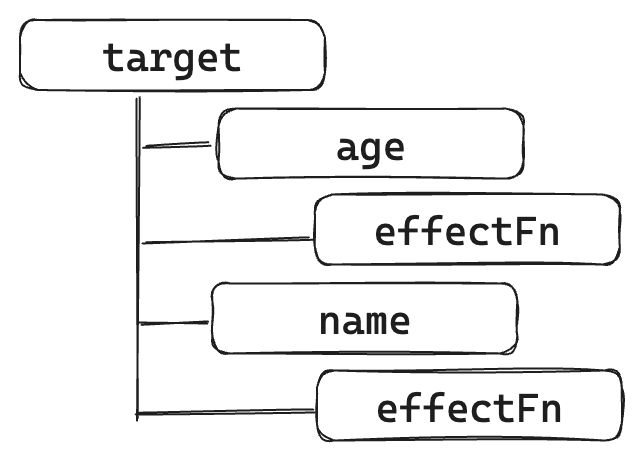
如果在不同的副作用函数中读取了两个不同对象的不同属性:
| effect(function effectFn1() { | |
| console.log(obj1.age1); | |
| }) | |
| effect(function effectFn2() { | |
| console.log(obj2.age2); | |
| }) |
那么关系如下:
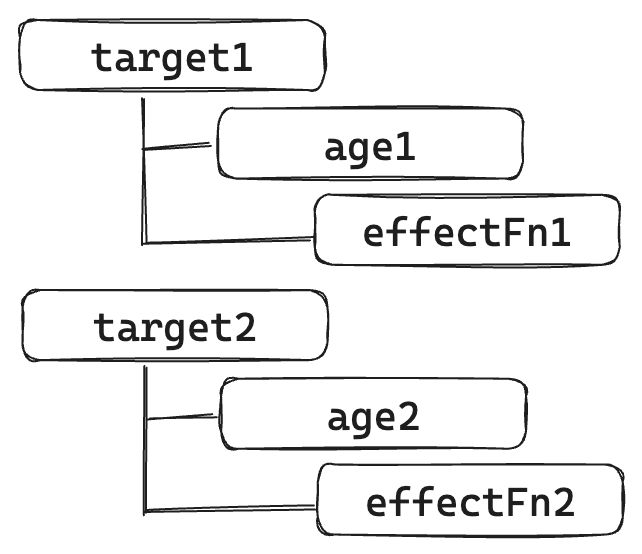
其实就是一个树型数据结构。这个联系建立起来之后,如果我们设置了obj2.text2的值,就只会导致 effectFn2函数重新执行,并不会导致 effectFn1 函数重新执行,之前的问题就解决了。
代码实现
| const bucket = new WeakMap(); | |
| const obj = new Proxy(data, { | |
| // 拦截读取操作 | |
| get(target, key) { | |
| // 没有 activeEffect,直接返回 | |
| if (!activeEffect) return | |
| // 根据 target 从“桶”中取得 depsMap,它也是一个 Map 类型:key --> effects | |
| let depsMap = bucket.get(target); | |
| // 如果不存在 depsMap,那么新建一个 Map 并与 target 关联 | |
| if (!depsMap) { | |
| bucket.set(target, (depsMap = new Map())); | |
| } | |
| // 再根据 key 从 depsMap 中取得 deps,它是一个 Set 类型, | |
| // 里面存储着所有与当前 key 相关联的副作用函数:effects | |
| let deps = depsMap.get(key); | |
| // 如果 deps 不存在,同样新建一个 Set 并与 key 关联 | |
| if (!deps) { | |
| depsMap.set(key, (deps = new Set())); | |
| } | |
| // 最后将当前激活的副作用函数添加到“桶”里 | |
| deps.add(activeEffect); | |
| // 返回属性值 | |
| return target[key]; | |
| }, | |
| // 拦截设置操作 | |
| set(target, key, newVal) { | |
| // 设置属性值 | |
| target[key] = newVal; | |
| // 根据 target 从桶中取得 depsMap,它是 key --> effects | |
| const depsMap = bucket.get(target); | |
| if (!depsMap) return; | |
| // 根据 key 取得所有副作用函数 effects | |
| const effects = depsMap.get(key); | |
| // 执行副作用函数 | |
| effects && effects.forEach(fn => fn()); | |
| return true | |
| } | |
| }); |
从这段代码可以看出构建数据结构的方式,我们分别使用了 WeakMap、Map和 Set:
WeakMap 由 target --> Map 构成;
Map 由 key --> Set 构成。
其中 WeakMap 的键是原始对象 target,WeakMap的值是一个 Map 实例,而 Map 的键是原始对象 target 的 key ,Map的值是一个由副作用函数组成的 Set 。它们的关系下图所示:
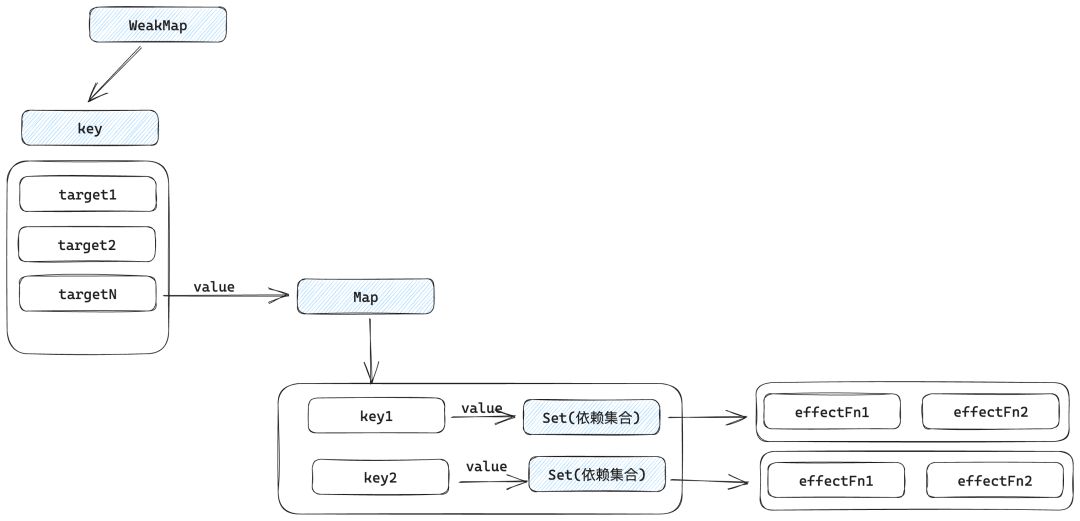
我们把上图中的 Set数据结构所存储的副作用函数集合称为 key的依赖集合。
单元测试
为什么这里才开始写单元测试?
先来看看我们写单元测试的目的:
- 验证代码功能:确保每个组件或模块按预期工作。单元测试通常针对特定功能或代码路径,验证它们在各种输入和条件下的表现。
- 提早发现错误:通过单元测试可以在代码集成到更大的系统之前发现问题,这有助于减少未来的调试和维护工作量。
- 文档和示例:良好的单元测试不仅验证功能,还可以作为代码的使用示例,帮助其他开发人员理解代码的预期行为。
- 促进重构:具有良好单元测试覆盖率的代码库使得重构变得更加安全和容易,因为可以迅速验证重构后的代码是否仍按预期工作。
- 确保代码质量:定期运行单元测试有助于确保代码质量随时间的变化保持稳定,尤其是在多人协作的项目中。
- 持续集成和部署:单元测试是持续集成(CI)和持续部署(CD)流程的重要组成部分,有助于自动化这些流程,确保代码改动不会引入新的错误。
- 提高开发效率:单元测试可以减少手动测试的需要,从而加快开发过程,并使开发者更有信心进行代码更改。
之前的代码都比较简单,没有写的必要,也不能为了写而写,现在功能在慢慢增加,后续我们会对代码进行重构,需要单元测试来保证我们的功能没有问题。
编写单测
如果你不会写,或者之前没有写过,可以尝试使用 ChatGPT 帮我们写,以下是一个使用案例:
❝推荐一个 ChatGPT: https://ask.vuejs.news/ ,也是笔者之前为了方便使用而开发。可以免费供小伙伴们使用,有使用问题可以联系笔者
| 我想使用 vitest 进行单元测试,以下是测试代码是我的测试代码,我会从main.ts导出一个 effect 函数 和 一个用于创建响应式对象的 reactive 函数。我们期待effect会被立即执行一次,打印出 18, 当age 改变的时候 effect 函数会被再次执行一次,打印出 23,当改变 address 的时候,effect 不会执行,我的响应式数据为:const data = { name: 'dahuang', age: 18 }。 请你帮我编写一个单元测试: | |
| effect(function effectFn1() { | |
| console.log(obj.age); | |
| }) | |
| setTimeout(() => { | |
| obj.age = 23; | |
| }, 1000); | |
| setTimeout(() => { | |
| obj.address = 'beijing' | |
| }, 2000); |
以下就是生成的单元测试代码:
| import { describe, it, expect, vi } from 'vitest'; | |
| import { effect, reactive } from './main'; // 确保从您的 main.ts 文件中导入 | |
| describe('reactivity system', () => { | |
| it('should run the effect function when reactive properties change', async () => { | |
| const consoleSpy = vi.spyOn(console, 'log'); // 创建一个监视 console.log 调用的 spy | |
| // 创建响应式对象 | |
| const obj = reactive({ name: 'dahuang', age: 18 }); | |
| // 定义 effect 函数 | |
| effect(() => { | |
| console.log(obj.age); | |
| }); | |
| // 检查 effect 是否立即执行 | |
| expect(consoleSpy).toHaveBeenCalledWith(18); | |
| // 更改 age 属性并等待 | |
| setTimeout(() => { | |
| obj.age = 23; | |
| }, 1000); | |
| await new Promise((r) => setTimeout(r, 1100)); // 等待上述 setTimeout 完成 | |
| // 检查 effect 是否在 age 改变时再次执行 | |
| expect(consoleSpy).toHaveBeenCalledWith(23); | |
| // 更改 address 属性并等待 | |
| setTimeout(() => { | |
| obj.address = 'beijing'; | |
| }, 2000); | |
| await new Promise((r) => setTimeout(r, 2100)); | |
| // 验证 effect 没有因 address 改变而执行 | |
| expect(consoleSpy).toHaveBeenCalledTimes(2); | |
| consoleSpy.mockRestore(); // 清除 mock | |
| }); | |
| }); |
解释一下这些内容:
describe: 这是一个用来定义一组相关测试的函数。它通常用于将测试用例组织成逻辑分组,使测试更加结构化和易于管理。每个 describe 块可以包含多个测试用例。
it: 这是一个定义单个测试用例的函数。每个 it 块通常描述了一个具体的行为或功能的期望结果。它是实际执行测试和断言的地方。
expect: 这是一个用于编写测试断言的函数。测试断言是用来验证代码的行为是否符合预期的表达式。expect 函数通常与一系列的匹配器(如 toBe, toEqual 等)结合使用,以检查不同类型的期望值。
vi: vi 是 Vitest 中的一个全局对象,提供了一系列的工具函数,特别是用于监视(spy)、模拟(mock)和突变(stub)函数的行为。它是 Vitest 特有的,用于创建更加复杂和控制的测试场景。
运行单测
那么我们就要从main.js中导出这2 个函数。
相关代码在 commit: (8362dd3)设计一个完善的响应系统 ,git checkout 8362dd3 即可查看。
点击即可运行,如果有问题,请看 第一节 环境搭建。
单测执行结果
一个响应式系统就完成了,接下来我们还会对这个响应式系统进行增强。
下一步我们会对代码进行重构,先来体验一下单测的快乐。同时我们也来思考几个问题:
- 存储副作用函数的桶为什么使用了
WeakMap? - 在
Proxy中的set函数中直接返回了true, 应该怎么写?不返回会有什么问题?
响应式系统代码重构
在重构代码之前,先把思考问题先解决掉,扫清障碍
分析思考问题
存储副作用函数的桶为什么使用了 WeakMap ?
其实涉及 WeakMap和 Map 的区别,我们用一段代码来讲解:
| <html lang="en"> | |
| <head> | |
| <meta charset="UTF-8"> | |
| <meta name="viewport" content="width=device-width, initial-scale=1.0"> | |
| <title>Document</title> | |
| </head> | |
| <body> | |
| <script> | |
| const map = new Map(); | |
| const weakmap = new WeakMap(); | |
| (function () { | |
| const foo = { foo: 1 }; | |
| const bar = { bar: 2 }; | |
| map.set(foo, 1); | |
| weakmap.set(bar, 2); | |
| })(); | |
| console.log(map); | |
| console.log(weakmap); | |
| </script> | |
| </body> | |
| </html> |
当该函数表达式执行完毕后,对于对象 foo 来说,它仍然作为 map的 key 被引用着,因此垃圾回收器(grabage collector)不会把它从内存中移除,我们仍然可以通过 map.keys 打印出对象 foo。然而对于对象 bar来说,由于WeakMap的 key是弱引用,它不影响垃圾回收器的工作,所以一旦表达式执行完毕,垃圾回收器就会把对象 bar从内存中移除,并且我们无法获取 WeakMap的 key值,也就无法通过 WeakMap取得对象 bar。
简单地说,WeakMap对 key是弱引用,不影响垃圾回收器的工作。据这个特性可知,一旦key被垃圾回收器回收,那么对应的键和值就访问不到了。所以 WeakMap经常用于存储那些只有当 key所引用的对象存在时(没有被回收)才有价值的信息,例如上面的场景中,如果 target 对象没有任何引用了,说明用户侧不再需要它了,这时垃圾回收器会完成回收任务。但如果使用 Map来代替 WeakMap,那么即使用户侧的代码对 target没有任何引用,这个 target 也不会被回收,最终可能导致内存溢出。
我们看下打印的结果,会有一个更加直观的感受,可以看到 WeakMap里面已经为空了。

Proxy的使用问题
在 Proxy 中的 set函数中直接返回了 true, 这样写规范吗?会有什么问题?如果不写返回值会有什么问题?
根据 ECMAScript 规范,set 方法需要返回一个布尔值。这个返回值有重要的意义:
- 返回
true: 表示属性设置成功。 - 返回
false: 表示属性设置失败。在严格模式(strict mode)下,这会导致一个TypeError被抛出。
如果在 set 函数中不返回任何值(或返回 undefined),那么默认情况下,它相当于返回 false。这意味着:
- 在非严格模式下,尽管不返回任何值可能不会立即引起错误,但这是不符合规范的行为。它可能导致调用代码错误地认为属性设置失败。
- 在严格模式下,不返回
true会导致抛出TypeError异常。
正确的应该这样写:
| set(target, key, newVal, receiver) { | |
| const res = Reflect.set(target, key, newVal, receiver) | |
| // ... | |
| return res | |
| } |
那么问题又来了,为什么要配合 Reflect 使用呢?
我们添加一个 case 看看:
| it('why use Reflect', () => { | |
| const consoleSpy = vi.spyOn(console, 'log'); // 捕获 console.log | |
| const obj = reactive({ | |
| foo: 1, | |
| get bar() { | |
| return this.foo | |
| } | |
| }) | |
| effect(() => { | |
| console.log(obj.bar); | |
| }) | |
| expect(consoleSpy).toHaveBeenCalledTimes(1); | |
| obj.foo ++ | |
| expect(consoleSpy).toHaveBeenCalledTimes(2); | |
| }) |
当 effect 注册的副作用函数执行时,会读取 obj.bar属性,它发现 obj.bar是一个访问器属性,因此执行 getter函数。由于在 getter 函数中通过 this.foo 读取了 foo属性值,因此我们认为副作用函数与属性 foo之间也会建立联系。当我们修改 p.foo 的值时应该能够触发响应,使得副作用函数重新执行才对,但是实际上 effect 并没有执行。这是为什么呢?
我们来看一下 bucket 中的收集结果:(你可以把这个 case 的内容直接放在 main.ts 中运行一下,然后在浏览器中查看)

很明显, 没有收集到 foo, 这是为什么呢?
我们是用的 this.foo 获取到的 bar 值,打印一下 this:

this 是这个 obj 对象本身,并不是我们代理后的对象,自然就无法被收集到。那么如何改变这个 this 指向呢?就需要使用到 Reflect.get 函数的第三个参数 receiver,可以把它理解为函数调用过程中的 this。
将代码做如下修改:
| get(target, key) { | |
| consnt res = Reflect.get(target, key, receiver) | |
| // ... 其他不变 | |
| return res | |
| }, | |
| set(target, key, newVal) { | |
| const res = Reflect.set(target, key, newVal, receiver) | |
| // ... 其他不变 | |
| return res | |
| }, |
然后我们再次运行单测,就可以看到通过了
相关代码在 commit: (c90c1ac)增加Reflect的使用 ,git checkout 8362dd3 即可查看。
代码重构
在目前的实现中,当读取属性值时,我们直接在 get 拦截函数里编写把副作用函数收集到“桶”里的这部分逻辑,但更好的做法是将这部分逻辑单独封装到一个 track 函数中,函数的名字叫 track 是为了表达追踪的含义。同样,我们也可以把触发副作用函数重新执行的逻辑封装到 trigger函数中:
| function track(target, key) { | |
| // 没有 activeEffect,直接返回 | |
| if (!activeEffect) return target[key]; | |
| // 根据 target 从“桶”中取得 depsMap,它也是一个 Map 类型:key --> effects | |
| let depsMap = bucket.get(target); | |
| // 如果不存在 depsMap,那么新建一个 Map 并与 target 关联 | |
| if (!depsMap) { | |
| bucket.set(target, (depsMap = new Map())); | |
| } | |
| // 再根据 key 从 depsMap 中取得 deps,它是一个 Set 类型, | |
| // 里面存储着所有与当前 key 相关联的副作用函数:effects | |
| let deps = depsMap.get(key); | |
| // 如果 deps 不存在,同样新建一个 Set 并与 key 关联 | |
| if (!deps) { | |
| depsMap.set(key, (deps = new Set())); | |
| } | |
| // 最后将当前激活的副作用函数添加到“桶”里 | |
| deps.add(activeEffect); | |
| } | |
| function trigger(target, key) { | |
| // 根据 target 从桶中取得 depsMap,它是 key --> effects | |
| const depsMap = bucket.get(target); | |
| if (!depsMap) return; | |
| // 根据 key 取得所有副作用函数 effects | |
| const effects = depsMap.get(key); | |
| // 执行副作用函数 | |
| effects && effects.forEach((fn) => fn()); | |
| } | |
| // 对原始数据的代理 | |
| export function reactive(target) { | |
| return new Proxy(target, { | |
| // 拦截读取操作 | |
| get(target, key, receiver) { | |
| const res = Reflect.get(target, key, receiver); | |
| // 依赖收集 | |
| track(target, key); | |
| return res; | |
| }, | |
| // 拦截设置操作 | |
| set(target, key, newVal, receiver) { | |
| // 设置属性值 | |
| const res = Reflect.set(target, key, newVal, receiver); | |
| // 派发更新 | |
| trigger(target, key); | |
| return res; | |
| }, | |
| }); | |
| } |
分别把逻辑封装到 track 和 trigger 函数内,这能为我们带来极大的灵活性。
我们来运行一下 pnpm test命令:
可以看到,我们的case全部通过。单测,让我们的重构没有压力,这下再也不怕把代码改坏啦!这里我们也可以感受出来,单测的一些好处。
当我们在写单测的时候,最好一个功能写一个 case,一组有关联的逻辑放在一个测试文件中,这样当功能改动的时候,需要改动的case会最少。
相关代码在 commit: (afbaff0)响应式系统代码重构 ,git checkout afbaff0 即可查看。
总结
响应式系统核心逻辑流程图,如下:
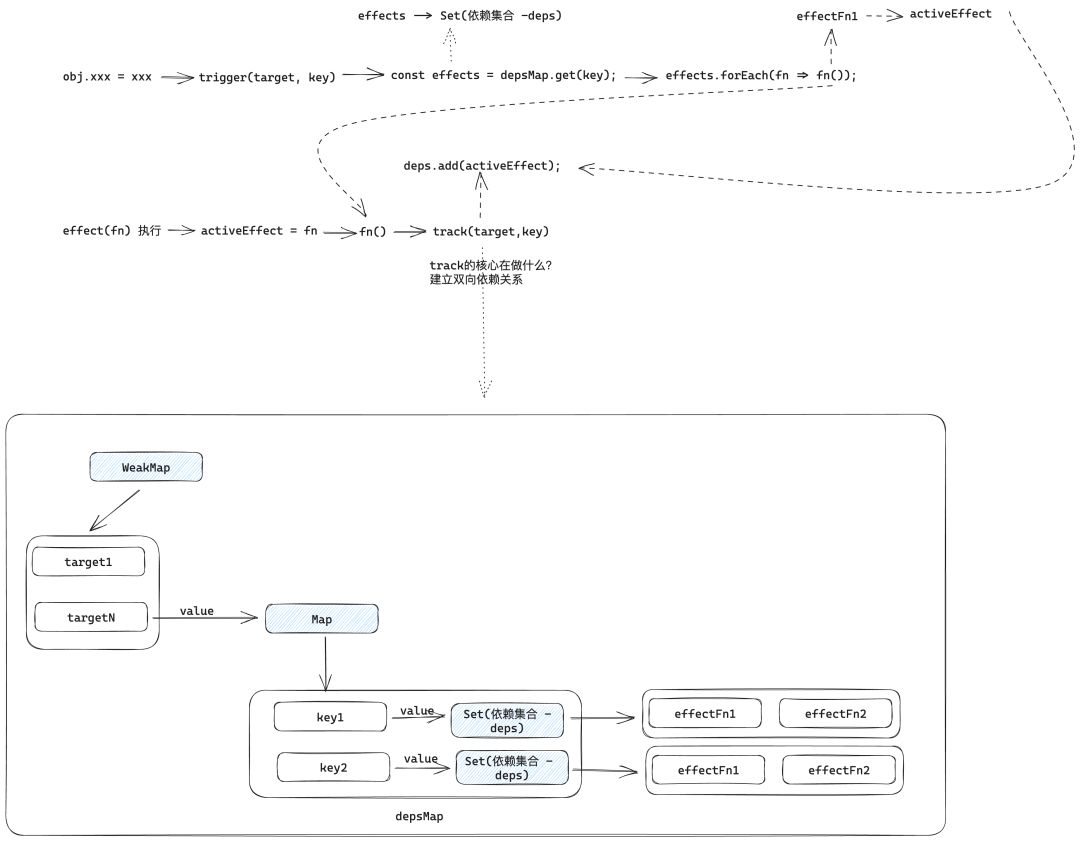
由于篇幅原因,本文就到此结束。后续文章会在此基础上进一步优化这个响应式系统,所以本文的内容一定要弄清楚。后续文章的内容将会包括:依赖清理、嵌套 effect、scheduler、computed、watch 等,最终会实现出一个mini-vue!