MapReduce定义
常用数据序列化类型
Java类型 | Hadoop Writable类型 |
boolean | BooleanWritable |
byte | ByteWritable |
int | IntWritable |
float | FloatWritable |
long | LongWritable |
double | DoubleWritable |
String | Text |
map | MapWritable |
array | ArrayWritable |
MapReduce编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver。
1、Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3)Mapper中的业务逻辑写在map()方法中
(4)Map的输出数据是KV对的形式(KV的类型可自定义)
(5)map()方法(MapTask进程)对每一个<K,V>调用一次
2、Reducer阶段
(1)用户自定义的Reduce要继自己的父类
(2) Reducer的输入 数据类型对应Mappe的输出数据类型,也是KV
(3)Reducer的业务逻捐写在reduce()方法中
(4) ReduceTask进程对每-组相同k的<K,V>组调用一次reduce()方法
3、Driver阶段
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象
WordCount案例实操
(1)需求
在给定的文本文件中统计输出每一个单词出现的总次数

(2)期望输出数据
banzhang 1
cls 2
hadoop 1
jiao 1
ss 2
xue 1
(3)项目实操
pom.xml
| <dependencies> | |
| <dependency> | |
| <groupId>jdk.tools</groupId> | |
| <artifactId>jdk.tools</artifactId> | |
| <version>1.8</version> | |
| <scope>system</scope> | |
| <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> | |
| </dependency> | |
| <dependency> | |
| <groupId>junit</groupId> | |
| <artifactId>junit</artifactId> | |
| <version>RELEASE</version> | |
| </dependency> | |
| <dependency> | |
| <groupId>org.apache.logging.log4j</groupId> | |
| <artifactId>log4j-core</artifactId> | |
| <version>2.8.2</version> | |
| </dependency> | |
| <dependency> | |
| <groupId>org.apache.hadoop</groupId> | |
| <artifactId>hadoop-common</artifactId> | |
| <version>2.7.2</version> | |
| </dependency> | |
| <dependency> | |
| <groupId>org.apache.hadoop</groupId> | |
| <artifactId>hadoop-client</artifactId> | |
| <version>2.7.2</version> | |
| </dependency> | |
| <dependency> | |
| <groupId>org.apache.hadoop</groupId> | |
| <artifactId>hadoop-hdfs</artifactId> | |
| <version>2.7.2</version> | |
| </dependency> | |
| </dependencies> |
log4j.properties
| log4j.rootLogger=INFO, stdout | |
| log4j.appender.stdout=org.apache.log4j.ConsoleAppender | |
| log4j.appender.stdout.layout=org.apache.log4j.PatternLayout | |
| log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n | |
| log4j.appender.logfile=org.apache.log4j.FileAppender | |
| log4j.appender.logfile.File=target/spring.log | |
| log4j.appender.logfile.layout=org.apache.log4j.PatternLayout | |
| log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n |
WordCountMapper
| package com.imooc.mr; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.IntWritable; | |
| import org.apache.hadoop.io.LongWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Mapper; | |
| //map阶段 | |
| //第一个泛型KEYIN 输入数据的key | |
| //第二个泛型VALUEIN 输入数据的value | |
| //第三个泛型KEYOUT 输出数据的key的类型 sa,1 ss,1 | |
| //第四个泛型VALUEOUT 输出的数据的value类型 | |
| public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> { | |
| protected void map(LongWritable key, Text value, Context context) | |
| throws IOException, InterruptedException { | |
| //获取一行 | |
| String line=value.toString(); | |
| //切分 | |
| String[] words=line.split(" "); | |
| //循环 | |
| for (String string : words) { | |
| //SS | |
| Text k=new Text(); | |
| k.set(string); | |
| //1 | |
| IntWritable v=new IntWritable(); | |
| v.set(1); | |
| context.write(k, v); | |
| } | |
| } | |
| } |
WordCountReducer
| package com.imooc.mr; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.IntWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Reducer; | |
| //KETIN KEYOUT map阶段输出的key和value | |
| public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { | |
| protected void reduce(Text key, Iterable<IntWritable> values, Context context) | |
| throws IOException, InterruptedException { | |
| int sum=0; | |
| //累加求和 | |
| for (IntWritable value : values) { | |
| sum+=value.get(); | |
| } | |
| IntWritable v=new IntWritable(); | |
| v.set(sum); | |
| context.write(key, v); | |
| } | |
| } |
WordcountDriver
| package com.imooc.mr; | |
| import java.io.IOException; | |
| import org.apache.hadoop.conf.Configuration; | |
| import org.apache.hadoop.fs.Path; | |
| import org.apache.hadoop.io.IntWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Job; | |
| import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; | |
| import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; | |
| public class WordcountDriver { | |
| public static void main(String[] args) throws Exception { | |
| //输入路径(处理E:\temp\input下的***文件) | |
| String inputPath="E:\\temp\\input"; | |
| //输出路径(output文件夹不能存在,否则报错) | |
| String outputPath="E:\\temp\\output"; | |
| Configuration conf = new Configuration(); | |
| // 1 获取Job对象 | |
| Job job = Job.getInstance(conf); | |
| // 2 设置jar存储位置 | |
| job.setJarByClass(WordcountDriver.class); | |
| // 3 关联Map和Reduce类 | |
| job.setMapperClass(WordCountMapper.class); | |
| job.setReducerClass(WordCountReducer.class); | |
| // 4 设置Mapper阶段输出数据的key和value类型 | |
| job.setMapOutputKeyClass(Text.class); | |
| job.setMapOutputValueClass(IntWritable.class); | |
| // 5 设置最终数据输出的key和value类型 | |
| job.setOutputKeyClass(Text.class); | |
| job.setOutputValueClass(IntWritable.class); | |
| // 6 设置输入路径和输出路径 | |
| FileInputFormat.setInputPaths(job, new Path(inputPath)); | |
| FileOutputFormat.setOutputPath(job, new Path(outputPath)); | |
| // 7 提交job | |
| // job.submit(); | |
| job.waitForCompletion(true); | |
| System.out.println("-------OVER-----------"); | |
| } | |
| } |
Hadoop序列化
为什么不用java的序列化?
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header传输。所以,Hadoop自己开发了一套序列化机制(Writable).
Hadoop序列化特点:
1)紧凑:高效实用存储空间
2)快速:读写数据的额外开销小
3)可扩展:随着通信协议的升级而升级
4)互操作:支持多语言的交互
自定义bean对象实现序列化接口(Writable)
自定义对象序列化步骤:
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
| public FlowBean() { | |
| super(); | |
| } |
(3)重写序列化方法
| @Override | |
| public void write(DataOutput out) throws IOException { | |
| out.writeLong(upFlow); | |
| out.writeLong(downFlow); | |
| out.writeLong(sumFlow); | |
| } |
(4)重写反序列化方法
| public void readFields(DataInput in) throws IOException { | |
| upFlow = in.readLong(); | |
| downFlow = in.readLong(); | |
| sumFlow = in.readLong(); | |
| } |
(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),可用”\t”分开,方便后续用。
(7)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。详见后面排序案例。
| public int compareTo(FlowBean o) { | |
| // 倒序排列,从大到小 | |
| return this.sumFlow > o.getSumFlow() ? -1 : 1; | |
| } |
序列化案例实操
需求
统计每一个手机号耗费的总上行流量、下行流量、总流量
输入数据

期望输出数据
13560436666 1116 954 2070
手机号码 上行流量 下行流量 总流量
编写MapReduce程序
实例化Bean对象
| package com.imooc.flowsum; | |
| import java.io.DataInput; | |
| import java.io.DataOutput; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.Writable; | |
| //步骤1 实现Weitable接口 | |
| public class FlowBean implements Writable { | |
| private long upFlow;// 上行流量 | |
| private long downFlow;// 下行流量 | |
| private long sumFlow;// 总流量 | |
| // 步骤2:无参构造 | |
| public FlowBean() { | |
| } | |
| // 有参构造 | |
| public FlowBean(long upFlow, long downFlow) { | |
| this.upFlow = upFlow; | |
| this.downFlow = downFlow; | |
| this.sumFlow = upFlow + downFlow; | |
| } | |
| // 步骤3:序列化方法 | |
| public void write(DataOutput out) throws IOException { | |
| out.writeLong(upFlow); | |
| out.writeLong(downFlow); | |
| out.writeLong(sumFlow); | |
| } | |
| // 步骤4:反序列化方法 | |
| // 反序列化方法读顺序必须和写序列化方法的写顺序必须一致 | |
| public void readFields(DataInput in) throws IOException { | |
| //必须与序列化中顺序一致 | |
| this.upFlow = in.readLong(); | |
| this.downFlow = in.readLong(); | |
| this.sumFlow = in.readLong(); | |
| } | |
| // 步骤6:为后续方便,重新toString方法 | |
| public String toString() { | |
| return upFlow + "\t" + downFlow + "\t" + sumFlow; | |
| } | |
| public long getUpFlow() { | |
| return upFlow; | |
| } | |
| public void setUpFlow(long upFlow) { | |
| this.upFlow = upFlow; | |
| } | |
| public long getDownFlow() { | |
| return downFlow; | |
| } | |
| public void setDownFlow(long downFlow) { | |
| this.downFlow = downFlow; | |
| } | |
| public long getSumFlow() { | |
| return sumFlow; | |
| } | |
| public void setSumFlow(long sumFlow) { | |
| this.sumFlow = sumFlow; | |
| } | |
| } |
Mapper
| package com.imooc.flowsum; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.LongWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Mapper; | |
| public class FlowBeanMapper extends Mapper<LongWritable, Text, Text, FlowBean> { | |
| protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { | |
| // 1 获取一行 | |
| String line = value.toString(); | |
| // 2 切割字段 | |
| String[] words = line.split("\t"); | |
| // 3 封装对象 | |
| Text k = new Text(); | |
| k.set(words[1]);//取出手机号码 | |
| // 取出上行流量和下行流量 | |
| long upFlow = Long.parseLong(words[words.length - 3]); | |
| long downFlow = Long.parseLong(words[words.length - 2]); | |
| FlowBean v = new FlowBean(upFlow, downFlow); | |
| System.out.println("map输出的参数:"+v); | |
| // 4 写出 | |
| context.write(k, v); | |
| } | |
| } |
Reducer
| package com.imooc.flowsum; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Reducer; | |
| public class FlowBeanReducer extends Reducer<Text, FlowBean, Text, FlowBean> { | |
| protected void reduce(Text key, Iterable<FlowBean> values, Context context) | |
| throws IOException, InterruptedException { | |
| long sum_up = 0; | |
| long sum_dowm = 0; | |
| for (FlowBean flowBean : values) { | |
| System.out.println("reduce输入的参数:"+flowBean); | |
| sum_up += flowBean.getUpFlow(); | |
| sum_dowm += flowBean.getDownFlow(); | |
| } | |
| FlowBean temp = new FlowBean(sum_up, sum_dowm); | |
| System.out.println("reduce输出的参数:"+temp); | |
| context.write(key, temp); | |
| } | |
| } |
Driver
| package com.imooc.flowsum; | |
| import org.apache.hadoop.conf.Configuration; | |
| import org.apache.hadoop.fs.Path; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Job; | |
| import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; | |
| import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; | |
| public class FlowBeanDriver { | |
| public static void main(String[] args) throws Exception { | |
| // 输入路径(处理E:\temp\input下的***文件) | |
| String inputPath = "E:\\temp\\input"; | |
| // 输出路径(output文件夹不能存在,否则报错) | |
| String outputPath = "E:\\temp\\output"; | |
| Configuration conf = new Configuration(); | |
| // 1 获取Job对象 | |
| Job job = Job.getInstance(conf); | |
| // 2 设置jar存储位置(当前类.class) | |
| job.setJarByClass(FlowBeanDriver.class); | |
| // 3 关联Map和Reduce类 | |
| job.setMapperClass(FlowBeanMapper.class); | |
| job.setReducerClass(FlowBeanReducer.class); | |
| // 4 设置Mapper阶段输出数据的key和value类型 | |
| job.setMapOutputKeyClass(Text.class); | |
| job.setMapOutputValueClass(FlowBean.class); | |
| // 5 设置最终数据输出的key和value类型 | |
| job.setOutputKeyClass(Text.class); | |
| job.setOutputValueClass(FlowBean.class); | |
| // 6 设置输入路径和输出路径 | |
| FileInputFormat.setInputPaths(job, new Path(inputPath)); | |
| FileOutputFormat.setOutputPath(job, new Path(outputPath)); | |
| // 7 提交job | |
| // job.submit(); | |
| job.waitForCompletion(true); | |
| System.out.println("-------OVER-----------"); | |
| } | |
| } |
FileInputFormat实现类
FileInoutFormat常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等。
TextInputFormat
TextInputFormat是默认的FileInputFormat实现类。按行读取每条记录。键是存储该行在整个文件中起始字节偏移量,LongWritable类型。值是这行的内容,不包括任何终止符(换行符和回车符),Text类型。
一下是一个实例,比如一个分片包含一下四条记录

每条记录表示为以下键值对

KeyValueTextInputFormat
每一行均为一条记录,被分隔符分为key,value.可以通过咋驱动类中设置conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR,"\t");来设定分隔符。默认分隔符为tab(\t)。
以下是一个实例,输入的是一个包含四条记录的分片。其中--->表示一个(水平方向的)制表符

每条记录表示为一下键/值对

KeyValueTextInputFormat实操
1需求:
统计输入文件中每一行的第一个单词相同的行数。
输入数据:
| banzhang ni hao | |
| xihuan hadoop banzhang | |
| banzhang ni hao | |
| xihuan hadoop banzhang |
期望输出数据:
| banzhang 2 | |
| xihuan 2 |
2注意事项
| // 设置切割符 | |
| conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " "); | |
| // 设置输入格式 | |
| job.setInputFormatClass(KeyValueTextInputFormat.class); |
3代码实现
Mapper
| package com.imooc.keyvaluetext; | |
| import org.apache.hadoop.io.IntWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Mapper; | |
| public class KVTextMapper extends Mapper<Text, Text, Text, IntWritable> { | |
| protected void map(Text key, Text value, Context context) throws java.io.IOException, InterruptedException { | |
| IntWritable v = new IntWritable(1); | |
| context.write(key, v); | |
| }; | |
| } |
Reducer
| package com.imooc.keyvaluetext; | |
| import org.apache.hadoop.io.IntWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Reducer; | |
| public class KVTextReducer extends Reducer<Text, IntWritable, Text, IntWritable> { | |
| protected void reduce(Text key, java.lang.Iterable<IntWritable> values, Context context) | |
| throws java.io.IOException, InterruptedException { | |
| int sum = 0; | |
| for (IntWritable value : values) { | |
| sum++; | |
| } | |
| context.write(key, new IntWritable(sum)); | |
| }; | |
| } |
Driver
| package com.imooc.keyvaluetext; | |
| import java.io.IOException; | |
| import org.apache.hadoop.conf.Configuration; | |
| import org.apache.hadoop.fs.Path; | |
| import org.apache.hadoop.io.IntWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Job; | |
| import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; | |
| import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader; | |
| import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; | |
| import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; | |
| public class KVTextDriver { | |
| public static void main(String[] args) throws Exception { | |
| // 输入路径(处理E:\temp\input下的***文件) | |
| String inputPath = "E:\\temp\\input"; | |
| // 输出路径(output文件夹不能存在,否则报错) | |
| String outputPath = "E:\\temp\\output"; | |
| Configuration conf = new Configuration(); | |
| // 设置切割符(KeyValueInputFormat重点配置)(KeyValueInputFormat重点配置)(KeyValueInputFormat重点配置) | |
| conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " "); | |
| // 1 获取Job对象 | |
| Job job = Job.getInstance(conf); | |
| // 2 设置jar存储位置 | |
| job.setJarByClass(KVTextDriver.class); | |
| // 3 关联Map和Reduce类 | |
| job.setMapperClass(KVTextMapper.class); | |
| job.setReducerClass(KVTextReducer.class); | |
| // 4 设置Mapper阶段输出数据的key和value类型 | |
| job.setMapOutputKeyClass(Text.class); | |
| job.setMapOutputValueClass(IntWritable.class); | |
| // 5 设置最终(reducer)数据输出的key和value类型 | |
| job.setOutputKeyClass(Text.class); | |
| job.setOutputValueClass(IntWritable.class); | |
| // 设置输入格式(KeyValueInputFormat重点配置)(KeyValueInputFormat重点配置)(KeyValueInputFormat重点配置) | |
| job.setInputFormatClass(KeyValueTextInputFormat.class); | |
| // 6 设置输入路径和输出路径 | |
| FileInputFormat.setInputPaths(job, new Path(inputPath)); | |
| FileOutputFormat.setOutputPath(job, new Path(outputPath)); | |
| // 7 提交job | |
| // job.submit(); | |
| job.waitForCompletion(true); | |
| System.out.println("-------OVER-----------"); | |
| } | |
| } |
NLineInputFormat
如果使用NLineInputFormat,代表每个进程处理的InputSpit不再按Block块去划分,而是按照NLineInputFormat指定的行数N进行划分。即输入文件的总行数/N=切片数,如果不整切,切片数=商+1
Key/value和TextInputFormat一样
原始数据

N=2切片结果

N=3切片结果

代码注意事项
| //设置每个切片InputSplit中划分三条记录 NLineInputFormat.setNumLinesPerSplit(job, 3); | |
| //使用NLineInputFormat处理记录数 | |
| job.setInputFormatClass(NLineInputFormat.class); |
自定义InputFormat
自定义InputFormat步骤如下:
- 自定义一个类继承FileInputFormat
- 改写RecordReader,实现一次读取一个完整文件封装为KV。
- 在输出时使用SequenceFileOutPutFormat输出合并文件。
Shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
Partition分区
问题引出
要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机归属地不同的省份输入到不同的文件中(分区)
默认分区

默认分区是根据key的hashcode对ReduceTasks个数取模得到的。用户没发控制哪个key存储到哪个分区。
自定义分区步骤
- 自定义继承Partitioner,重写getPartition()方法。
- 在job驱动中,设置自定义的Partitioner。
| // 指定自定义数据分区 | |
| job.setPartitionerClass(ProvincePartitioner.class); |
- 自定义PPartition后,要根据自定义Partitioner的逻辑设置响应数量的ReduceTask。
| // 同时指定相应数量的reduce task | |
| job.setNumReduceTasks(5); |
自定义分区实操(在上面的序列化案例实操项目的基础上进行实操)
需求:
将手机号开头为136、137、138、139和其他的分别放置5个文件中
输入数据:
| 1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200 | |
| 2 13846544121 192.196.100.2 264 0 200 | |
| 3 13956435636 192.196.100.3 132 1512 200 | |
| 4 13966251146 192.168.100.1 240 0 404 | |
| 5 18271575951 192.168.100.2 www.atguigu.com 1527 2106 200 | |
| 6 84188413 192.168.100.3 www.atguigu.com 4116 1432 200 | |
| 7 13590439668 192.168.100.4 1116 954 200 | |
| 8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200 | |
| 9 13729199489 192.168.100.6 240 0 200 | |
| 10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200 | |
| 11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200 | |
| 12 15959002129 192.168.100.9 www.atguigu.com 1938 180 500 | |
| 13 13560439638 192.168.100.10 918 4938 200 | |
| 14 13470253144 192.168.100.11 180 180 200 | |
| 15 13682846555 192.168.100.12 www.qq.com 1938 2910 200 | |
| 16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200 | |
| 17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404 | |
| 18 18390173782 192.168.100.15 www.sogou.com 9531 2412 200 | |
| 19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200 | |
| 20 13768778790 192.168.100.17 120 120 200 | |
| 21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200 | |
| 22 13568436656 192.168.100.19 1116 954 200 |
期望输出结果:
将手机号开头为136、137、138、139和其他的分别放置5个文件中
136 | 分区0 |
137 | 分区1 |
138 | 分区2 |
139 | 分区3 |
其他 | 分区4 |
自定义partition类
| package com.imooc; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Partitioner; | |
| import com.imooc.flowsumpartition.FlowBean; | |
| //自定义partition | |
| public class ProvincePartitioner extends Partitioner<Text, com.imooc.flowsumpartition.FlowBean> { | |
| public int getPartition(Text key, FlowBean value, int numPartitions) { | |
| // 1 获取电话号码的前三位 | |
| String preNum = key.toString().substring(0, 3); | |
| int partition = 4; | |
| // 2 判断是哪个省 | |
| if ("136".equals(preNum)) { | |
| partition = 0; | |
| } else if ("137".equals(preNum)) { | |
| partition = 1; | |
| } else if ("138".equals(preNum)) { | |
| partition = 2; | |
| } else if ("139".equals(preNum)) { | |
| partition = 3; | |
| } | |
| return partition; | |
| } | |
| } |
Driver驱动类
| package com.imooc.flowsumpartition; | |
| import org.apache.hadoop.conf.Configuration; | |
| import org.apache.hadoop.fs.Path; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Job; | |
| import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; | |
| import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; | |
| import com.imooc.ProvincePartitioner; | |
| public class FlowBeanDriver { | |
| public static void main(String[] args) throws Exception { | |
| // 输入路径(处理E:\temp\input下的***文件) | |
| String inputPath = "E:\\temp\\input"; | |
| // 输出路径(output文件夹不能存在,否则报错) | |
| String outputPath = "E:\\temp\\output"; | |
| Configuration conf = new Configuration(); | |
| // 1 获取Job对象 | |
| Job job = Job.getInstance(conf); | |
| // 2 设置jar存储位置(当前类.class) | |
| job.setJarByClass(FlowBeanDriver.class); | |
| // 3 关联Map和Reduce类 | |
| job.setMapperClass(FlowBeanMapper.class); | |
| job.setReducerClass(FlowBeanReducer.class); | |
| // 4 设置Mapper阶段输出数据的key和value类型 | |
| job.setMapOutputKeyClass(Text.class); | |
| job.setMapOutputValueClass(FlowBean.class); | |
| // 5 设置最终数据输出的key和value类型 | |
| job.setOutputKeyClass(Text.class); | |
| job.setOutputValueClass(FlowBean.class); | |
| // 指定自定义数据分区(自定义partition重要配置)(自定义partition重要配置)(自定义partition重要配置) | |
| job.setPartitionerClass(ProvincePartitioner.class); | |
| // 同时指定相应数量的reduce | |
| // task(自定义partition重要配置)(自定义partition重要配置)(自定义partition重要配置) | |
| job.setNumReduceTasks(5); | |
| // 6 设置输入路径和输出路径 | |
| FileInputFormat.setInputPaths(job, new Path(inputPath)); | |
| FileOutputFormat.setOutputPath(job, new Path(outputPath)); | |
| // 7 提交job | |
| // job.submit(); | |
| job.waitForCompletion(true); | |
| System.out.println("-------OVER-----------"); | |
| } | |
| } |
分区总结
- 如果ReduceTask的数据>getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
- 如果ReduceTask的数据<getPartition的结果数,则会Exception;
- 如果ReduceTask的数据==1,分区效果不起作用,最终也就只会产生一个结果part-r-00000;
WritableComparable排序(全排序)(全排序)(全排序)
排序分类
- 部分排序
MapReduce根据输入记录的键对数据集排序,保证输出的每个文件内部有序。
- 全排序
最终输出的结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所以文件,完全丧失了MapReduce所提供的并行架构。
- 辅助排序(GroupingComparator分组):
在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或者几个字段相同(全部字段比较不同)的key进入到同一个reduce方法时,可以采用分组排序
- 二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序
WritableComparable排序案例实操
需求
将数据按照总流量(上行流量+下行流量)从大到小排序
输入数据
手机号 上行流量 下行流量 总流量
| 13470253144 180 180 360 | |
| 13509468723 7335 110349 117684 | |
| 13560439638 918 4938 5856 | |
| 13568436656 3597 25635 29232 | |
| 。。。 |
预期结果(按照最后一列排序)
| 13509468723 7335 110349 117684 | |
| 13736230513 2481 24681 27162 | |
| 13956435636 132 1512 1644 | |
| 13846544121 264 0 264 |
实体类实现WritableComparable接口
| package com.imooc.compareto; | |
| import java.io.DataInput; | |
| import java.io.DataOutput; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.Writable; | |
| import org.apache.hadoop.io.WritableComparable; | |
| //步骤1 实现WritableComparable接口 | |
| public class FlowBean implements WritableComparable<FlowBean> { | |
| private long upFlow;// 上行流量 | |
| private long downFlow;// 下行流量 | |
| private long sumFlow;// 总流量 | |
| // 步骤2:无参构造 | |
| public FlowBean() { | |
| } | |
| // 有参构造 | |
| public FlowBean(long upFlow, long downFlow) { | |
| this.upFlow = upFlow; | |
| this.downFlow = downFlow; | |
| this.sumFlow = upFlow + downFlow; | |
| } | |
| // 步骤3:序列化方法 | |
| public void write(DataOutput out) throws IOException { | |
| out.writeLong(upFlow); | |
| out.writeLong(downFlow); | |
| out.writeLong(sumFlow); | |
| } | |
| // 步骤4:反序列化方法 | |
| // 反序列化方法读顺序必须和写序列化方法的写顺序必须一致 | |
| public void readFields(DataInput in) throws IOException { | |
| // 必须与序列化中顺序一致 | |
| this.upFlow = in.readLong(); | |
| this.downFlow = in.readLong(); | |
| this.sumFlow = in.readLong(); | |
| } | |
| 步骤5:比较 | |
| public int compareTo(FlowBean bean) { | |
| int result; | |
| // 按照总流量大小,倒序排列 | |
| if (sumFlow > bean.getSumFlow()) { | |
| result = -1; | |
| } else if (sumFlow < bean.getSumFlow()) { | |
| result = 1; | |
| } else { | |
| result = 0; | |
| } | |
| return result; | |
| } | |
| // 步骤6:为后续方便,重新toString方法 | |
| public String toString() { | |
| return upFlow + "\t" + downFlow + "\t" + sumFlow; | |
| } | |
| public long getUpFlow() { | |
| return upFlow; | |
| } | |
| public void setUpFlow(long upFlow) { | |
| this.upFlow = upFlow; | |
| } | |
| public long getDownFlow() { | |
| return downFlow; | |
| } | |
| public void setDownFlow(long downFlow) { | |
| this.downFlow = downFlow; | |
| } | |
| public long getSumFlow() { | |
| return sumFlow; | |
| } | |
| public void setSumFlow(long sumFlow) { | |
| this.sumFlow = sumFlow; | |
| } | |
| } |
Mapper
| package com.imooc.compareto; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.LongWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Mapper; | |
| public class FlowBeanMapper extends Mapper<LongWritable, Text, FlowBean, Text> { | |
| protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { | |
| // 1 获取一行 | |
| String line = value.toString(); | |
| // 2 切割字段 | |
| String[] words = line.split("\t"); | |
| // 3 封装对象 | |
| Text v = new Text(); | |
| v.set(words[0]);//取出手机号码 | |
| // 取出上行流量和下行流量 | |
| long upFlow = Long.parseLong(words[1]); | |
| long downFlow = Long.parseLong(words[2]); | |
| long sumFlow=Long.parseLong(words[3]); | |
| FlowBean k = new FlowBean(upFlow, downFlow); | |
| // 4 写出 | |
| context.write(k, v); | |
| } | |
| } |
Reducer
| package com.imooc.compareto; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Reducer; | |
| public class FlowBeanReducer extends Reducer<FlowBean, Text, Text, FlowBean> { | |
| protected void reduce(FlowBean key, Iterable<Text> values, Context context) | |
| throws IOException, InterruptedException { | |
| for (Text text : values) { | |
| context.write(text, key); | |
| } | |
| } | |
| } |
Driver
| package com.imooc.compareto; | |
| import org.apache.hadoop.conf.Configuration; | |
| import org.apache.hadoop.fs.Path; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Job; | |
| import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; | |
| import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; | |
| public class FlowBeanDriver { | |
| public static void main(String[] args) throws Exception { | |
| // 输入路径(处理E:\temp\input下的***文件) | |
| String inputPath = "E:\\temp\\input"; | |
| // 输出路径(output文件夹不能存在,否则报错) | |
| String outputPath = "E:\\temp\\output"; | |
| Configuration conf = new Configuration(); | |
| // 1 获取Job对象 | |
| Job job = Job.getInstance(conf); | |
| // 2 设置jar存储位置(当前类.class) | |
| job.setJarByClass(FlowBeanDriver.class); | |
| // 3 关联Map和Reduce类 | |
| job.setMapperClass(FlowBeanMapper.class); | |
| job.setReducerClass(FlowBeanReducer.class); | |
| // 4 设置Mapper阶段输出数据的key和value类型 | |
| job.setMapOutputKeyClass(FlowBean.class); | |
| job.setMapOutputValueClass(Text.class); | |
| // 5 设置最终数据输出的key和value类型 | |
| job.setOutputKeyClass(Text.class); | |
| job.setOutputValueClass(FlowBean.class); | |
| // 6 设置输入路径和输出路径 | |
| FileInputFormat.setInputPaths(job, new Path(inputPath)); | |
| FileOutputFormat.setOutputPath(job, new Path(outputPath)); | |
| // 7 提交job | |
| // job.submit(); | |
| job.waitForCompletion(true); | |
| System.out.println("-------OVER-----------"); | |
| } | |
| } |
WritableComparable排序(分区排序)(分区排序)(分区排序)
需求
要求每个省份(136、137、148、139、其他)手机号输出的文件中按照总流量内部排序。
需求分析:基于前一个需求WritableComparableq排序(全排序),增加自定义分区类,分区按照省份手机号设置。
自定义分区
| package com.imooc.compareto_partition; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Partitioner; | |
| //泛型为map的输出类型,即reduce的输入类型 | |
| public class ProvincePartitioner extends Partitioner<FlowBean, Text> { | |
| public int getPartition(FlowBean key, Text value, int numPartitions) { | |
| // 1 获取电话号码的前三位 | |
| String preNum = value.toString().substring(0, 3); | |
| int partition = 4; | |
| // 2 判断是哪个省 | |
| if ("136".equals(preNum)) { | |
| partition = 0; | |
| } else if ("137".equals(preNum)) { | |
| partition = 1; | |
| } else if ("138".equals(preNum)) { | |
| partition = 2; | |
| } else if ("139".equals(preNum)) { | |
| partition = 3; | |
| } | |
| return partition; | |
| } | |
| } |
Driver启动类
核心代码
| // 指定自定义数据分区(自定义partition重要配置)(自定义partition重要配置)(自定义partition重要配置) | |
| job.setPartitionerClass(ProvincePartitioner.class); | |
| // 同时指定相应数量的reducetask(自定义partition重要配置)(自定义partition重要配置)(自定义partition重要配置) | |
| job.setNumReduceTasks(5); | |
| package com.imooc.compareto_partition; | |
| import org.apache.hadoop.conf.Configuration; | |
| import org.apache.hadoop.fs.Path; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Job; | |
| import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; | |
| import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; | |
| public class FlowBeanDriver { | |
| public static void main(String[] args) throws Exception { | |
| // 输入路径(处理E:\temp\input下的***文件) | |
| String inputPath = "E:\\temp\\input"; | |
| // 输出路径(output文件夹不能存在,否则报错) | |
| String outputPath = "E:\\temp\\output"; | |
| Configuration conf = new Configuration(); | |
| // 1 获取Job对象 | |
| Job job = Job.getInstance(conf); | |
| // 2 设置jar存储位置(当前类.class) | |
| job.setJarByClass(FlowBeanDriver.class); | |
| // 3 关联Map和Reduce类 | |
| job.setMapperClass(FlowBeanMapper.class); | |
| job.setReducerClass(FlowBeanReducer.class); | |
| // 4 设置Mapper阶段输出数据的key和value类型 | |
| job.setMapOutputKeyClass(FlowBean.class); | |
| job.setMapOutputValueClass(Text.class); | |
| // 5 设置最终数据输出的key和value类型 | |
| job.setOutputKeyClass(Text.class); | |
| job.setOutputValueClass(FlowBean.class); | |
| // 指定自定义数据分区(自定义partition重要配置)(自定义partition重要配置)(自定义partition重要配置) | |
| job.setPartitionerClass(ProvincePartitioner.class); | |
| // 同时指定相应数量的reduce | |
| // task(自定义partition重要配置)(自定义partition重要配置)(自定义partition重要配置) | |
| job.setNumReduceTasks(5); | |
| // 6 设置输入路径和输出路径 | |
| FileInputFormat.setInputPaths(job, new Path(inputPath)); | |
| FileOutputFormat.setOutputPath(job, new Path(outputPath)); | |
| // 7 提交job | |
| // job.submit(); | |
| job.waitForCompletion(true); | |
| System.out.println("-------OVER-----------"); | |
| } | |
| } |
Combiner合并
简介
- Combiner是MR程序中Mapper和Reducer之外的一种组件
- Combiner组件的父类就是Reducer
- Combiner和Reducer的区别在于运行的位置(Combiner是在每一个MapTask所在的节点运行)(Reducer是在接收全局所有Mapper的输出结果)
- Combiner的意义就是对每一个MapTask的输出进行局部徽章,以减少网络传输量。
- Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出KV应该和Reducer的输入KV类型对应起来
GroupingComparator分组(辅助排序)
在reduce端对key进行分组,应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不同)的key进入到同一个reduce方法时,可以采用分组排序
分组排序步骤:
- (1)自定义类继承WritableComparator
- (2)重写compare()方法
| public int compare(WritableComparable a, WritableComparable b) { | |
| // 比较的业务逻辑 | |
| return result; | |
| } |
- (3)创建一个构造将比较对象的类传给父类
| protected OrderGroupingComparator() { | |
| super(OrderBean.class, true); | |
| } |
(4)在驱动里设置关联
| // 8 设置reduce端的分组 | |
| job.setGroupingComparatorClass(OrderGroupingComparator.class); |
GroupingComparator分组实操:
需求:统计一个订单里价格最高的数据
我认为,GroupingComparator所解决的问题是:当一个entity里有多个属性(id,price,age'等等)需要排序时候,需要将entity作为作为mapper的输出K,这样才能排序,但是因为(id,price,age)只要有一个不同,他们就不同,所以每一个k(entity)都是不同的,而我又想将id相同的但是实际不同的K伪装成相同的放在一个reduce中
比如:
(id,price) A(1,11) B(1,33) C(2,33) 三个数都作为map的输出K是不相同(假设我实体类的compare方法中先按id排序,在按price排序)的,所以要进入3个reduce中,如下图
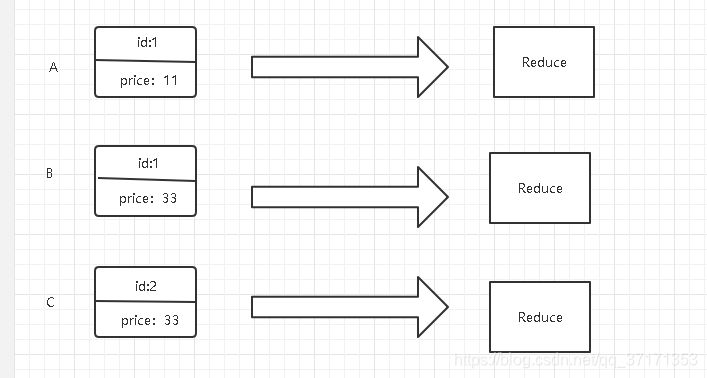
但是我的需求是id相同的进入一个reduce中,所以出现了GroupingComparator
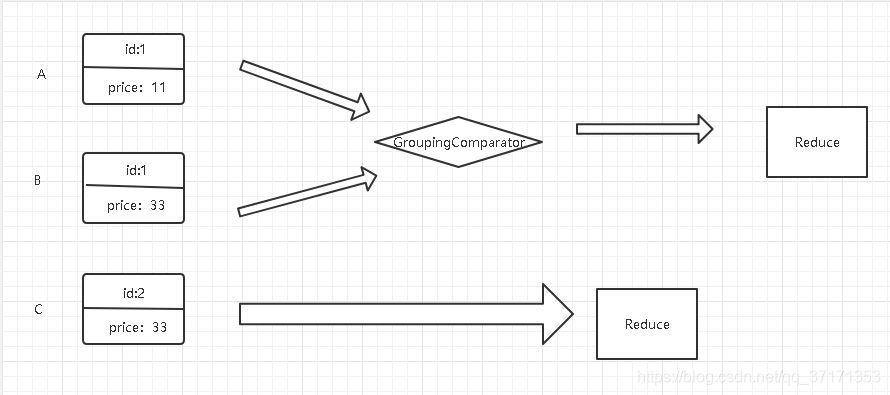
在通俗一点:在reduce端对key进行分组,应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不同)的key进入到同一个reduce方法时,可以采用分组排序
输入数据:
订单号 商品号 价格
| 0000001 Pdt_01 222.8 | |
| 0000002 Pdt_05 722.4 | |
| 0000001 Pdt_02 33.8 | |
| 0000003 Pdt_06 232.8 | |
| 0000003 Pdt_02 33.8 | |
| 0000002 Pdt_03 522.8 | |
| 0000002 Pdt_04 122.4 |
期望输出结果:
| 1 222.8 | |
| 2 722.4 | |
| 3 232.8 |
需求分析:
- 利用“订单id和成交金额”作为key,可以将Map阶段读取到的所有订单数据按照id升序排序,如果id相同再按照金额降序排序,发送到Reduce。
- 在Reduce端利用groupingComparator将订单id相同的kv聚合成组,然后取第一个即是该订单中最贵商品,
封装的实体类(实现WritableComparable接口)
| package com.imooc.GroupingComparator; | |
| import java.io.DataInput; | |
| import java.io.DataOutput; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.WritableComparable; | |
| public class OrderBean implements WritableComparable<OrderBean> { | |
| private int order_id; | |
| private double price; | |
| public void readFields(DataInput in) throws IOException { | |
| this.order_id = in.readInt(); | |
| this.price = in.readDouble(); | |
| } | |
| public void write(DataOutput out) throws IOException { | |
| out.writeInt(order_id); | |
| out.writeDouble(price); | |
| } | |
| // 二次排序 | |
| public int compareTo(OrderBean o) { | |
| int result; | |
| //先按id升序,在按价格降序 | |
| if (order_id > o.getOrder_id()) { | |
| result = 1; | |
| } else if (order_id < o.getOrder_id()) { | |
| result = -1; | |
| } else { | |
| // 价格倒序排序 | |
| result = price > o.getPrice() ? -1 : 1; | |
| } | |
| return result; | |
| } | |
| public OrderBean() { | |
| } | |
| public int getOrder_id() { | |
| return order_id; | |
| } | |
| public void setOrder_id(int order_id) { | |
| this.order_id = order_id; | |
| } | |
| public double getPrice() { | |
| return price; | |
| } | |
| public void setPrice(double price) { | |
| this.price = price; | |
| } | |
| public String toString() { | |
| return order_id + "\t" + price; | |
| } | |
| } |
Mapper
| package com.imooc.GroupingComparator; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.LongWritable; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Mapper; | |
| public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> { | |
| protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { | |
| // 1 获取一行 | |
| String line = value.toString(); | |
| // 2 截取 | |
| String[] fields = line.split("\t"); | |
| // 3 封装对象 | |
| OrderBean k = new OrderBean(); | |
| k.setOrder_id(Integer.parseInt(fields[0])); | |
| k.setPrice(Double.parseDouble(fields[2])); | |
| // 4 写出 | |
| context.write(k, NullWritable.get()); | |
| } | |
| } |
Reducer
| package com.imooc.GroupingComparator; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.mapreduce.Reducer; | |
| public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> { | |
| protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) | |
| throws IOException, InterruptedException { | |
| context.write(key, NullWritable.get()); | |
| } | |
| } |
继承GroupingComparator的类
| package com.imooc.GroupingComparator; | |
| import org.apache.hadoop.io.WritableComparable; | |
| import org.apache.hadoop.io.WritableComparator; | |
| public class OrderGroupingComparator extends WritableComparator { | |
| protected OrderGroupingComparator() { | |
| super(OrderBean.class, true); | |
| } | |
| public int compare(WritableComparable a, WritableComparable b) { | |
| OrderBean aBean = (OrderBean) a; | |
| OrderBean bBean = (OrderBean) b; | |
| int result; | |
| if (aBean.getOrder_id() > bBean.getOrder_id()) { | |
| result = 1; | |
| } else if (aBean.getOrder_id() < bBean.getOrder_id()) { | |
| result = -1; | |
| } else { | |
| result = 0; | |
| } | |
| return result; | |
| } | |
| } |
Driver驱动类
| package com.imooc.GroupingComparator; | |
| import java.io.IOException; | |
| import org.apache.hadoop.conf.Configuration; | |
| import org.apache.hadoop.fs.Path; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.mapreduce.Job; | |
| import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; | |
| import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; | |
| public class OrderDriver { | |
| public static void main(String[] args) throws Exception { | |
| // 输入路径(处理E:\temp\input下的***文件) | |
| String inputPath = "E:\\temp\\input"; | |
| // 输出路径(output文件夹不能存在,否则报错) | |
| String outputPath = "E:\\temp\\output"; | |
| Configuration conf = new Configuration(); | |
| // 1 获取Job对象 | |
| Job job = Job.getInstance(conf); | |
| // 2 设置jar存储位置(当前类.class) | |
| job.setJarByClass(OrderDriver.class); | |
| // 3 关联Map和Reduce类 | |
| job.setMapperClass(OrderMapper.class); | |
| job.setReducerClass(OrderReducer.class); | |
| // 4 设置Mapper阶段输出数据的key和value类型 | |
| job.setMapOutputKeyClass(OrderBean.class); | |
| job.setMapOutputValueClass(NullWritable.class); | |
| // 5 设置最终数据输出的key和value类型 | |
| job.setOutputKeyClass(OrderBean.class); | |
| job.setOutputValueClass(NullWritable.class); | |
| // 6 设置输入路径和输出路径 | |
| FileInputFormat.setInputPaths(job, new Path(inputPath)); | |
| FileOutputFormat.setOutputPath(job, new Path(outputPath)); | |
| // 8 设置reduce端的分组 | |
| job.setGroupingComparatorClass(OrderGroupingComparator.class); | |
| // 7 提交job | |
| // job.submit(); | |
| job.waitForCompletion(true); | |
| System.out.println("-------OVER-----------"); | |
| } | |
| } |
OutputFormat数据输出
OutputFormat接口实现类
OutputFormat是MapReduce输出的基类,所有 实现MapReduce输出都实现了OutputFormat接口。下面我们介绍几种常见的OutputFormat实现类。
- 1.文本输出TextOutputFormat
默认的输出格式是TextOutputFormat ,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把它们转换为字符串。
- 2. SequenceFileOutputF ormat
将SequenceFileOutputFormat输出作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很客易被压缩。
- 3.自定义OutputFormat
根据用户需求,自定义实现输出。
自定义OutputFormat步骤
- 自定义一个类继承FileOutputFormat
- 改写recordWriter,具体改写输出数据的方法write()
- job.setOutputFormatClass(FilterOutputFormat.class);
自定义OutputFormat案例实操
需求:
过滤输入的log日志,包含atguigu的网站输出到e:/atguigu.log,不包含atguigu的网站输出到e:/other.log。
输入数据:
| http://www.baidu.com | |
| http://www.google.com | |
| http://cn.bing.com | |
| http://www.atguigu.com | |
| http://www.sohu.com | |
| http://www.sina.com | |
| http://www.sin2a.com | |
| http://www.sin2desa.com | |
| http://www.sindsafa.com |
期望输出数据:
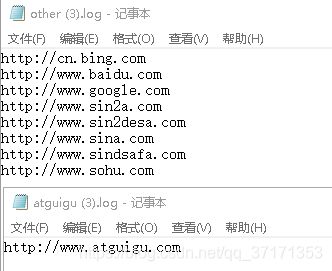
Mapper
单纯的切割和写
| package com.imooc.myoutputformat; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.LongWritable; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Mapper; | |
| public class FilterMapper extends Mapper<LongWritable, Text, Text, NullWritable> { | |
| protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { | |
| String line = value.toString(); | |
| Text k=new Text(line); | |
| context.write(k, NullWritable.get()); | |
| } | |
| } |
Reducer
单纯的写,但是要改一下格式,方便在输出文件里看,否则连在一起在一样
| package com.imooc.myoutputformat; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Reducer; | |
| public class FilterReducer extends Reducer<Text, NullWritable, Text, NullWritable> { | |
| protected void reduce(Text key, Iterable<NullWritable> values, Context context) | |
| throws IOException, InterruptedException { | |
| // 1 获取一行 | |
| String line = key.toString(); | |
| // 2 拼接 | |
| line = line + "\r\n"; | |
| // 3 设置key | |
| Text k=new Text(); | |
| k.set(line); | |
| for (NullWritable nullWritable : values) { | |
| context.write(k, NullWritable.get()); | |
| } | |
| } | |
| } |
FRecordWriter
继承RecordWriter
初始化数据流并且完整业务逻辑
而且在这个类中还可以写入MySQL,Redis等数据库中
| package com.imooc.myoutputformat; | |
| import java.io.IOException; | |
| import org.apache.hadoop.fs.FSDataOutputStream; | |
| import org.apache.hadoop.fs.FileSystem; | |
| import org.apache.hadoop.fs.Path; | |
| import org.apache.hadoop.io.IOUtils; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.RecordWriter; | |
| import org.apache.hadoop.mapreduce.TaskAttemptContext; | |
| public class FRecordWriter extends RecordWriter<Text, NullWritable> { | |
| FSDataOutputStream fosatguigu; | |
| FSDataOutputStream fosother; | |
| // 初始化方法 | |
| public FRecordWriter(TaskAttemptContext job){ | |
| try { | |
| // 1、获取文件系统 | |
| FileSystem fs = FileSystem.get(job.getConfiguration()); | |
| fosatguigu = fs.create(new Path("e:/atguigu.log")); | |
| // 2、创建两个文件输出流 | |
| fosother = fs.create(new Path("e:/other.log")); | |
| } catch (Exception e) { | |
| // TODO Auto-generated catch block | |
| e.printStackTrace(); | |
| } | |
| } | |
| // 业务逻辑类 | |
| public void write(Text key, NullWritable value) throws IOException, InterruptedException { | |
| try { | |
| // 判断是否包含“atguigu”输出到不同文件 | |
| if (key.toString().contains("atguigu")) { | |
| fosatguigu.write(key.toString().getBytes()); | |
| } else { | |
| fosother.write(key.toString().getBytes()); | |
| } | |
| } catch (Exception e) { | |
| // TODO Auto-generated catch block | |
| e.printStackTrace(); | |
| } | |
| } | |
| // close方法 | |
| public void close(TaskAttemptContext context) throws IOException, InterruptedException { | |
| // 关闭流 | |
| IOUtils.closeStream(fosatguigu); | |
| IOUtils.closeStream(fosother); | |
| } | |
| } |
FilterOutputFormat
因为上面创建了FRecordWriter类,所在下面的类中直接返回,基本不用改
| package com.imooc.myoutputformat; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.RecordWriter; | |
| import org.apache.hadoop.mapreduce.TaskAttemptContext; | |
| import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; | |
| public class FilterOutputFormat extends FileOutputFormat<Text,NullWritable>{ | |
| public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) | |
| throws IOException, InterruptedException { | |
| return new FRecordWriter(job); | |
| } | |
| } |
Driver启动类
核心代码
| // 设置(自定义outputFormat重点配置)(自定义outputFormat重点配置)(自定义outputFormat重点配置) | |
| job.setOutputFormatClass(FilterOutputFormat.class); | |
| // 6 设置输入路径和输出路径 | |
| FileInputFormat.setInputPaths(job, new Path(inputPath)); | |
| // 虽然我们自定义了outputformat,但是因为我们的outputformat继承fileoutputforma而fileoutputformat要输出一个_SUCCESS文件,所以,在这还得指定一个输出目录 | |
| FileOutputFormat.setOutputPath(job, new Path(outputPath)); | |
| package com.imooc.myoutputformat; | |
| import org.apache.hadoop.conf.Configuration; | |
| import org.apache.hadoop.fs.Path; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Job; | |
| import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; | |
| import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader; | |
| import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; | |
| public class FilterDriver { | |
| public static void main(String[] args) throws Exception { | |
| // 输入路径(处理E:\temp\input下的***文件) | |
| String inputPath = "E:\\temp\\input"; | |
| // 输出路径(output文件夹不能存在,否则报错) | |
| String outputPath = "E:\\temp\\output"; | |
| Configuration conf = new Configuration(); | |
| // 设置切割符(KeyValueInputFormat重点配置)(KeyValueInputFormat重点配置)(KeyValueInputFormat重点配置) | |
| conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " "); | |
| // 1 获取Job对象 | |
| Job job = Job.getInstance(conf); | |
| // 2 设置jar存储位置 | |
| job.setJarByClass(FilterDriver.class); | |
| // 3 关联Map和Reduce类 | |
| job.setMapperClass(FilterMapper.class); | |
| job.setReducerClass(FilterReducer.class); | |
| // 4 设置Mapper阶段输出数据的key和value类型 | |
| job.setMapOutputKeyClass(Text.class); | |
| job.setMapOutputValueClass(NullWritable.class); | |
| // 5 设置最终(reducer)数据输出的key和value类型 | |
| job.setOutputKeyClass(Text.class); | |
| job.setOutputValueClass(NullWritable.class); | |
| // 设置(自定义outputFormat重点配置)(自定义outputFormat重点配置)(自定义outputFormat重点配置) | |
| job.setOutputFormatClass(FilterOutputFormat.class); | |
| // 6 设置输入路径和输出路径 | |
| FileInputFormat.setInputPaths(job, new Path(inputPath)); | |
| // 虽然我们自定义了outputformat,但是因为我们的outputformat继承自fileoutputformat | |
| // 而fileoutputformat要输出一个_SUCCESS文件,所以,在这还得指定一个输出目录 | |
| FileOutputFormat.setOutputPath(job, new Path(outputPath)); | |
| // 7 提交job | |
| // job.submit(); | |
| job.waitForCompletion(true); | |
| System.out.println("-------OVER-----------"); | |
| } | |
| } |
Reduce Join
注意:
一般业务逻辑都在map阶段处理,所以不推荐reduce join ,推荐map join
工作原理
- Map端的主要工作:
为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key ,其余部分和新加的标志作为value,最后进行输出。
- Reduce端的主要工作:
在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在Map阶段已经打标志分开,最后进行合并就ok了。
Reduce Join案例实操
需求、输入数据、输出数据
(select id,pname,amount form t_order,t_product where t_order.pid=t_product.pid )
订单数据表t_order + 商品信息表t_product ====== 最终数据形式
id | pid | amount |
1001 | 01 | 1 |
1002 | 02 | 2 |
1003 | 03 | 3 |
1004 | 01 | 4 |
1005 | 02 | 5 |
1006 | 03 | 6 |
pid | pname |
01 | 小米 |
02 | 华为 |
03 | 格力 |
id | pname | amount |
1001 | 小米 | 1 |
1004 | 小米 | 4 |
1002 | 华为 | 2 |
设计思路
- 创建一个(订单id,商品pid,数量amount,商品名称pname,标志位flag)实体类(包含两个表的所有属性)
- 在map阶段中根据切片的信息获取操作文件名称,并且封装对象,如果操作的名称为order.txt,flag="order”,否则flag="product"
- map的输出 key 为共同的属性 pid ,value为封装的实体类
- 同一个reduce里有两种数据,一种是pid为某某某的订单记录(多条),另一种是pid为某某某的商品记录(一条),而且有fiag标记位,很容易分开,然后就可以拼接成最终的数据形式了
编码
实体类
| package com.imooc.reducejoin; | |
| import java.io.DataInput; | |
| import java.io.DataOutput; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.Writable; | |
| /** | |
| * @author 柴火 | |
| * | |
| */ | |
| public class TableBean implements Writable { | |
| private String order_id; // 订单id | |
| private String p_id; // 产品id | |
| private int amount; // 产品数量 | |
| private String pname; // 产品名称 | |
| private String flag; // 表的标记 | |
| public TableBean() { | |
| super(); | |
| } | |
| public void readFields(DataInput in) throws IOException { | |
| this.order_id = in.readUTF(); | |
| this.p_id = in.readUTF(); | |
| this.amount = in.readInt(); | |
| this.pname = in.readUTF(); | |
| this.flag = in.readUTF(); | |
| } | |
| public void write(DataOutput out) throws IOException { | |
| out.writeUTF(order_id); | |
| out.writeUTF(p_id); | |
| out.writeInt(amount); | |
| out.writeUTF(pname); | |
| out.writeUTF(flag); | |
| } | |
| public String toString() { | |
| return order_id + "\t" + amount + "\t" + pname; | |
| } | |
| public String getOrder_id() { | |
| return order_id; | |
| } | |
| public void setOrder_id(String order_id) { | |
| this.order_id = order_id; | |
| } | |
| public String getP_id() { | |
| return p_id; | |
| } | |
| public void setP_id(String p_id) { | |
| this.p_id = p_id; | |
| } | |
| public int getAmount() { | |
| return amount; | |
| } | |
| public void setAmount(int amount) { | |
| this.amount = amount; | |
| } | |
| public String getPname() { | |
| return pname; | |
| } | |
| public void setPname(String pname) { | |
| this.pname = pname; | |
| } | |
| public String getFlag() { | |
| return flag; | |
| } | |
| public void setFlag(String flag) { | |
| this.flag = flag; | |
| } | |
| } |
mapper
| package com.imooc.reducejoin; | |
| import java.io.IOException; | |
| import org.apache.hadoop.io.LongWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Mapper; | |
| import org.apache.hadoop.mapreduce.lib.input.FileSplit; | |
| public class TableMapper extends Mapper<LongWritable, Text, Text, TableBean> { | |
| String name; | |
| TableBean bean = new TableBean(); | |
| Text k = new Text(); | |
| protected void setup(Context context){ | |
| // 1 获取输入文件切片 | |
| FileSplit split = (FileSplit) context.getInputSplit(); | |
| // 2 获取输入文件名称 | |
| name = split.getPath().getName(); | |
| } | |
| protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { | |
| // 1 获取输入数据 | |
| String line = value.toString(); | |
| // 2 不同文件分别处理 | |
| if (name.startsWith("order")) {// 订单表处理 | |
| // 2.1 切割 | |
| String[] fields = line.split("\t"); | |
| // 2.2 封装bean对象 | |
| bean.setOrder_id(fields[0]); | |
| bean.setP_id(fields[1]); | |
| bean.setAmount(Integer.parseInt(fields[2])); | |
| bean.setPname(""); | |
| bean.setFlag("order"); | |
| k.set(fields[1]); | |
| } else {// 产品表处理 | |
| // 2.3 切割 | |
| String[] fields = line.split("\t"); | |
| // 2.4 封装bean对象 | |
| bean.setP_id(fields[0]); | |
| bean.setPname(fields[1]); | |
| bean.setFlag("pd"); | |
| bean.setAmount(0); | |
| bean.setOrder_id(""); | |
| k.set(fields[0]); | |
| } | |
| // 3 写出 | |
| context.write(k, bean); | |
| } | |
| } |
Reducer
| package com.imooc.reducejoin; | |
| import java.io.IOException; | |
| import java.util.ArrayList; | |
| import org.apache.commons.beanutils.BeanUtils; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Reducer; | |
| public class TableReducer extends Reducer<Text, TableBean, TableBean, NullWritable> { | |
| protected void reduce(Text key, Iterable<TableBean> values, Context context) | |
| throws IOException, InterruptedException { | |
| // 1准备存储订单的集合 | |
| ArrayList<TableBean> orderBeans = new ArrayList<>(); | |
| // 2 准备bean对象 | |
| TableBean pdBean = new TableBean(); | |
| for (TableBean bean : values) { | |
| if ("order".equals(bean.getFlag())) {// 订单表 | |
| // 拷贝传递过来的每条订单数据到集合中 | |
| TableBean orderBean = new TableBean(); | |
| try { | |
| BeanUtils.copyProperties(orderBean, bean); | |
| } catch (Exception e) { | |
| e.printStackTrace(); | |
| } | |
| orderBeans.add(orderBean); | |
| } else {// 产品表 | |
| try { | |
| // 拷贝传递过来的产品表到内存中 | |
| BeanUtils.copyProperties(pdBean, bean); | |
| } catch (Exception e) { | |
| e.printStackTrace(); | |
| } | |
| } | |
| } | |
| // 3 表的拼接 | |
| for (TableBean bean : orderBeans) { | |
| bean.setPname(pdBean.getPname()); | |
| System.out.println(bean); | |
| // 4 数据写出去 | |
| context.write(bean, NullWritable.get()); | |
| } | |
| } | |
| } |
Driver驱动类
| package com.imooc.reducejoin; | |
| import org.apache.hadoop.conf.Configuration; | |
| import org.apache.hadoop.fs.Path; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Job; | |
| import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; | |
| import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; | |
| public class TableDriver { | |
| public static void main(String[] args) throws Exception { | |
| // 0 根据自己电脑路径重新配置 | |
| args = new String[] { "e:/temp/input", "e:/temp/output" }; | |
| // 1 获取配置信息,或者job对象实例 | |
| Configuration configuration = new Configuration(); | |
| Job job = Job.getInstance(configuration); | |
| // 2 指定本程序的jar包所在的本地路径 | |
| job.setJarByClass(TableDriver.class); | |
| // 3 指定本业务job要使用的Mapper/Reducer业务类 | |
| job.setMapperClass(TableMapper.class); | |
| job.setReducerClass(TableReducer.class); | |
| // 4 指定Mapper输出数据的kv类型 | |
| job.setMapOutputKeyClass(Text.class); | |
| job.setMapOutputValueClass(TableBean.class); | |
| // 5 指定最终输出的数据的kv类型 | |
| job.setOutputKeyClass(TableBean.class); | |
| job.setOutputValueClass(NullWritable.class); | |
| // 6 指定job的输入原始文件所在目录 | |
| FileInputFormat.setInputPaths(job, new Path(args[0])); | |
| FileOutputFormat.setOutputPath(job, new Path(args[1])); | |
| // 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行 | |
| job.waitForCompletion(true); | |
| System.out.println("---------OVER------------"); | |
| } | |
| } |
Map Join
使用场景
Map Join适用于一张表十分小、一张表很大的场景。
优点
思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。
具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在驱动函数中加载缓存。
// 缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file://e:/cache/pd.txt"));
MapJoin实操
需求、输入数据、输出数据同上面的ReduceJoin
编码步骤
- 创建Mapper类
- 重新setup方法,读小表
| protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) | |
| throws IOException, InterruptedException { | |
| // 1 获取缓存的文件 | |
| URI[] cacheFiles = context.getCacheFiles(); | |
| String path = cacheFiles[0].getPath().toString(); | |
| BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(path), "UTF-8")); | |
| String line; | |
| while (StringUtils.isNotEmpty(line = reader.readLine())) { | |
| // 2 切割 | |
| String[] fields = line.split("\t"); | |
| // 3 缓存数据到集合 | |
| pdMap.put(fields[0], fields[1]); | |
| } | |
| // 4 关流 | |
| reader.close(); | |
| } |
- 重新map方法,进行join
- 编写Driver驱动类
| // 5、设置最终输出数据类型 | |
| job.setOutputKeyClass(Text.class); | |
| job.setOutputValueClass(NullWritable.class); | |
| // 6 加载缓存数据 | |
| job.addCacheFile(new URI("file:///e:/temp/product.txt")); | |
| // 7 Map端Join的逻辑不需要Reduce阶段,设置reduceTask数量为0 | |
| job.setNumReduceTasks(0); |
编码
mapper
| package com.imooc.mapjoin; | |
| import java.io.BufferedReader; | |
| import java.io.FileInputStream; | |
| import java.io.IOException; | |
| import java.io.InputStreamReader; | |
| import java.net.URI; | |
| import java.util.HashMap; | |
| import java.util.Map; | |
| import org.apache.commons.lang.StringUtils; | |
| import org.apache.hadoop.io.LongWritable; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Mapper; | |
| public class DistributedCacheMapper extends Mapper<LongWritable, Text, Text, NullWritable> { | |
| Map<String, String> pdMap = new HashMap<>(); | |
| protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) | |
| throws IOException, InterruptedException { | |
| // 1 获取缓存的文件 | |
| URI[] cacheFiles = context.getCacheFiles(); | |
| String path = cacheFiles[0].getPath().toString(); | |
| BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(path), "UTF-8")); | |
| String line; | |
| while (StringUtils.isNotEmpty(line = reader.readLine())) { | |
| // 2 切割 | |
| String[] fields = line.split("\t"); | |
| // 3 缓存数据到集合 | |
| pdMap.put(fields[0], fields[1]); | |
| } | |
| // 4 关流 | |
| reader.close(); | |
| } | |
| Text k = new Text(); | |
| protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { | |
| // 1 获取一行 | |
| String line = value.toString(); | |
| // 2 截取 | |
| String[] fields = line.split("\t"); | |
| // 3 获取产品id | |
| String pId = fields[1]; | |
| // 4 获取商品名称 | |
| String pdName = pdMap.get(pId); | |
| // 5 拼接 | |
| k.set(line + "\t" + pdName); | |
| // 6 写出 | |
| context.write(k, NullWritable.get()); | |
| } | |
| } |
Driver
| package com.imooc.mapjoin; | |
| import java.net.URI; | |
| import org.apache.hadoop.conf.Configuration; | |
| import org.apache.hadoop.fs.Path; | |
| import org.apache.hadoop.io.NullWritable; | |
| import org.apache.hadoop.io.Text; | |
| import org.apache.hadoop.mapreduce.Job; | |
| import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; | |
| import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; | |
| public class DistributedCacheDriver { | |
| public static void main(String[] args) throws Exception { | |
| // 0 根据自己电脑路径重新配置 | |
| args = new String[] { "e:/temp/input", "e:/temp/output" }; | |
| // 1 获取job信息 | |
| Configuration configuration = new Configuration(); | |
| Job job = Job.getInstance(configuration); | |
| // 2 设置加载jar包路径 | |
| job.setJarByClass(DistributedCacheDriver.class); | |
| // 3 关联map | |
| job.setMapperClass(DistributedCacheMapper.class); | |
| // 4、设置输入输出路径 | |
| FileInputFormat.setInputPaths(job, new Path(args[0])); | |
| FileOutputFormat.setOutputPath(job, new Path(args[1])); | |
| // 5、设置最终输出数据类型 | |
| job.setOutputKeyClass(Text.class); | |
| job.setOutputValueClass(NullWritable.class); | |
| // 6 加载缓存数据 | |
| job.addCacheFile(new URI("file:///e:/temp/product.txt")); | |
| // 7 Map端Join的逻辑不需要Reduce阶段,设置reduceTask数量为0 | |
| job.setNumReduceTasks(0); | |
| // 8 提交 | |
| boolean result = job.waitForCompletion(true); | |
| System.exit(result ? 0 : 1); | |
| } | |
| } |
倒排索引案例(多job串联)
敲黑板
多job串联不是配置在一起的,而是单独运行的,比如2个job串联就有2个驱动类,而不是一个驱动类
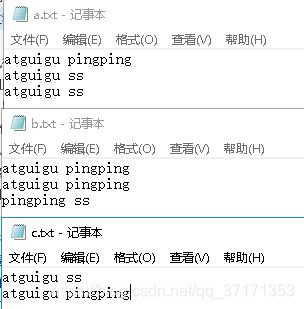
输入数据
期望输出数据
atguigu c.txt-->2 b.txt-->2 a.txt-->3
pingping c.txt-->1 b.txt-->3 a.txt-->1
ss c.txt-->1 b.txt-->1 a.txt-->2
操作步骤
job1
首先将a.txt
| atguigu pingping | |
| atguigu ss | |
| atguigu ss |
转换为
| atguigu--a.txt 3 | |
| ss--a.txt 2 | |
| ..... |
切分,然后在setup中获得切片中文件的名称(a.txt),在map方法中将其拼接在atguigu后作为K,传入到reduce中,value为1
在reduce阶段进行累加
job2
job1的输出结果,即为job2的输出结果
| atguigu--a.txt 3 | |
| atguigu--b.txt 2 | |
| atguigu--c.txt 2 | |
| pingping--a.txt 1 | |
| pingping--b.txt 3 | |
| pingping--c.txt 1 | |
| ss--a.txt 2 | |
| ss--b.txt 1 | |
| ss--c.txt 1 |
在map阶段将 (atguigu--a.txt 3)切分为 key=atguigu value=a.txt 3 ,传给reduce
在reduce阶段将key相同的values(a.txt 3 b.txt 3 c.txt 2 )进行拼接,从而得出预期结果
编码
如果上面看懂的话在这编码已经不是问题了,重要的是思路,思路,思路
学习资料
尚硅谷hadoop