NIO 实现高性能处理的原理是使用较少的线程来处理更多的任务。使用较少的 Thread 线程,通过 Selector 选择器来执行不同的 Channel 通道中的任务,执行的任务再结合 AIO (异步 I/O )就能发挥服务器最大的性能,大大提升软件运行效率。
 Java NIO
Java NIO
Java NIO 采用非阻塞高性能运行的方式来避免出现以前“笨拙”的同步 I/O 带来的低效率问题。 NIO 在大文件操作上相比常规 I/O 更加优秀。
Buffer
基础知识点
在使用传统的 I/O 操作时,比如 InputStream /OutputStream ,通常是将数据暂存到 byte [] 或者 char[] 中,亦或者从 byte[] 或者 char[] 中来获取数据,但是在 Java 语言中对 array 数组自身提供的可操作的 API 非常少,常用的操作仅仅是 length 属性和下标 [x] ,如果相对数组中的数据进行更高级的操作,需要自己写代码来实现,处理方式比较原始。而 Java NIO 中的 Buffer 类在暂存数据的同时还提供了很多工具方法,大大提高了程序开发效率。
Buffer 是一个抽象类,用于存储基本数据类型的容器,每个基本数据类型(除去 boolean )都有一个子类与之对应。它具有 7 个直接子类: ByteBuffer 、 CharBuffer 、 DoubleBuffer 、 Float Buffer 、 IntBuffer 、 Long Buffer 、 short Buffer 。
注意:
Buffer 类没有 BooleanBuffer 这个子类。
StringBuffer 在 java.lang 包下,而在 nio 包下并没有,在 Nio 中存储字符的缓冲区可以使用 char Buffer 类。
缓冲区为非线程安全的。
在 Buffer 中有 4 个核心技术点: capacity 、 limit 、 position 、 mark 。他们之间值的大小关系如下:
<= mark <= position <= limit <= capacity
- capacity :容量。代表该缓冲区当前所能容纳的元素的数量。不能为负数,且不能更改。
- limit :限制。代表第一个不应该读取或写入元素的 index 索引。不能为负数,且不能大于其 capacity 。
- position :位置。代表下一个将要读取或写入元素的 index 索引。不能为负数,且不能大于其 limit 。如果新设置的 limit 小于 position ,那么新的 limit 值就是 limit 。
- mark :标记。缓冲区的标记是一个索引,定义标记时,不能将其定义为负数,且不能大于其 position 。标记并不是必需的,如果定义了 mark ,在调用 reset() 方法时,会将缓冲区的 position 重置为该标记索引;在将 position 或者 limit 调整为小于该 mark 的值时,该 mark 会被丢弃,丢弃后 mark 的值时 -1。如果未定义 mark 调用 reset() 方法将导致抛出 invalidMark Exception 异常。
Buffer 中常用 API
返回值 | 方法名 | 作用 |
int | capacity() | 返回此缓冲区的容量 |
int | limit() | 返回此缓冲区的限制 |
Buffer | limit(int newLimit) | 设置此缓冲区的限制 |
int | position() | 返回此缓冲区的位置 |
Buffer | position(int newPosition) | 设置此缓冲区的位置 |
Buffer | mark() | 在此缓冲区的位置设置标记 |
int | remaining() | 返回当前位置(position)与限制(limit)之间的元素个数 return limit – position |
boolean | hasRemaining() | 判断在当前位置和限制之间是否有元素。return position < limit |
boolean | isReadOnly() | 返回此缓冲区是否为只读缓冲区 |
boolean | isDirect() | 判断此缓冲区是否为直接缓冲区 |
Buffer | clear() | 还原缓冲区到初始状态,包含将位置设置为 0,将限制设置为容量,丢弃标记,即 “一切默认”,但不会清除数据。 主要使用场景:在对缓冲区存储数据之前调用此方法 |
Buffer | rewind() | 重绕此缓冲区,将位置设置为0并丢弃标记。 主要使用场景:常在重新读取缓冲区数据时使用。 |
Buffer | flip() | 反转此缓冲区。首先将限制设置为当前位置,然后将位置设置为0。如果定义了标记,则丢弃该标记。 主要使用场景:当向缓冲区存储数据,然后再从缓冲区读取这些数据之前调用 |
堆内存与堆外内存
使用间接缓冲区(堆内存)向硬盘存取数据时需要首先将数据复制暂存到 JVM 的中间缓冲区中,然后 Java 程序才能对数据进行实际的读写操作。如果有频繁操作数据的情况发生,会提高内存占有率,大大降低软件对数据的吞吐量。
使用非间接缓冲区(堆外内存)无需 JVM 创建新的中间缓冲区,可直接在内核空间完成数据的处理,这样就减少了在 JVM 中创建缓冲区的步骤,增加了程序运行效率。
处理数据常用操作
以 ByteBuffer 为例,提供了 5 类操作。
- 以绝对位置和相对位置读写单个字节的 get() 和 put() 方法。
- 使用相对批量 get(byte[] dst) 方法将缓冲区中的连续字节读取到 buty[] dst 目标数组中;相对批量 put(byte[] src) 方法将 byte[] src 数组中或其他字节缓冲区中的连续字节存储到此缓冲区中。
- 使用绝对和相对 getType 和 putType 方法可以按照字节顺序在字节序列中读写其他基本数据类型的值,方法 getType 和 putType 可以进行数据类型的自动转换。
- 提供了创建视图缓冲区的方法,这些方法允许将字节缓冲区视为包含其他基本类型值的缓冲区,这些方法有: asCharBuffer() 、 asDoubleBuffer() 、 asFloatBuffer() 、 asIntBuffer() 、 asLongBuffer() 、 asShortBuffer() 。
- 提供了对缓冲区进行压缩( compacting )、复制( duplicating )和截取( slicing )的方法。
相对 / 绝对位置操作
相对位置操作是指在读取或写入一个或多个元素时,它从“当前位置开始”,然后将位置增加锁传输的元素个数。如果请求的传输超出限制,则相对 get 操作将抛出 BufferUnderflowException 异常,相对 put 操作将抛出 BufferOverflowException 异常,也就是说,在这两种情况下 ,都没有数据传输。
绝对位置操作采用显示元素索引,该操作不影响位置。如果 索引 参数超出限制,则绝对 get 操作和绝对 put 操作将抛出 IndexOutBoundsException 异常。
返回值类型 | 方法名 | 作用 |
Buffer | put(byte b) | 将给定的字节写入缓冲区的“当前位置”。 |
byte | get() | 读取此缓冲区“当前位置”的字节。 |
Buffer | put(byte[] src, int offset, int length) | 把给定源数组中的字节写入此缓冲区的“当前位置中”。如果要从该数据中心复制的字节数多于此缓冲区中的剩余字节(即 length > remaining),则不传输字节且抛出 bufferOverflowException 异常。否则,将给定数组中的 length 个字节复制到此缓冲区中。将数组中给定 offset 偏移量位置的数据复制到此缓冲区的当前位置,复制的元素个数为 length。 |
byte[] | get(byte[] dst, int offset, int length) | 将此缓冲区当前位置的字节传输到给定目标数组中。如果此缓冲区中剩余的字节少于满足请求所需要的字节(即 length > remaining),则不传输字节且抛出 BufferUnderflowWxception 异常。否则此方法将此缓冲区中的 length 个字节复制到给定数组中。从此缓冲区的当前位置和数组中的给定偏移量位置开始复制。然后,此缓冲区的位置将增加 length。 |
Buffer | put(byte[] src) | 将给定的源 byte 数组的所有内容存储到此缓冲区的当前位置。等同于:dst.put(a,0,a.length) |
byte[] | get(byte[] dst) | 将缓冲区 remaining 字节传输到给定的目标数组中。等同于:src.get(a,0,a.length) |
Buffer | put(ByteBuffer src) | 相对批量 put 操作。将给定源缓冲区中的剩余字节传输到此缓冲区当前位置中。如果源缓冲区中的剩余字节多于此缓冲区的剩余字节,即 src.remaining() > remaining(),则不传输字节且抛出 BufferOverflowException 异常。两个缓冲区的位置都会相应递增。 |
Buffer | put(int index, byte b) | 绝对 put 操作,将给定字节写入此缓冲区的给定索引位置。 |
byte | get(int index) | 绝对 get 操作,读取指定位置索引处的字节。 |
getType / putType 操作
可以直接根据源基本数据类型将数据写入此缓冲区,或者从此缓冲区读取指定类型的数据,同时此为缓冲区的位置位置根据不同的数据类型所占的字节数做相应的增加。
返回值类型 | 方法名 | 作用 |
ByteBuffer | putChar (char value) | 相对操作,将给定 char 值按照当前字节顺序写入到此缓冲区的当前位置,然后将此缓冲区位置增加 2,因为一个字符占 2 个字节。 |
ByteBuffer | putChar(int index, char value) | 绝对操作,将给定 char 值按照当前字节顺序写入到此缓冲区的给定位置。 |
ByteBuffer | putDouble(double value) | 相对操作,将给定 double 值按照当前字节顺序写入到此缓冲区的当前位置,然后将此缓冲区位置增加 8,因为一个 double 类型占 8 个字节。 |
ByteBuffer | putDouble(int index, double value) | 绝对操作,将给定 double 值按照当前字节顺序写入到此缓冲区的给定位置。 |
ByteBuffer | put float (float value) | 相对操作,将给定 float 值按照当前字节顺序写入到此缓冲区的当前位置,然后将此缓冲区位置增加 4,因为一个float 类型占 4 个字节。 |
ByteBuffer | putFloat(int index, float value) | 绝对操作,将给定 float 值按照当前字节顺序写入到此缓冲区的给定位置。 |
ByteBuffer | put(int value) | 相对操作,将给定 int 值按照当前字节顺序写入到此缓冲区的当前位置,然后将此缓冲区位置增加 4,因为一个 int 类型占 4 个字节。 |
ByteBuffer | put(int index, int value) | 绝对操作,将给定 int 值按照当前字节顺序写入到此缓冲区的给定位置。 |
ByteBuffer | put( long value) | 相对操作,将给定 long 值按照当前字节顺序写入到此缓冲区的当前位置,然后将此缓冲区位置增加 8,因为一个 long 类型占 8 个字节。 |
ByteBuffer | put(int index, long value) | 绝对操作,将给定 long 值按照当前字节顺序写入到此缓冲区的给定位置。 |
ByteBuffer | putShort(short value) | 相对操作,将给定 short 值按照当前字节顺序写入到此缓冲区的当前位置,然后将此缓冲区位置增加 2,因为一个 short 类型占 2 个字节。 |
ByteBuffer | putShort(int index, short value) | 绝对操作,将给定 short 值按照当前字节顺序写入到此缓冲区的给定位置。 |
缓冲区类型转换
通过调用 asXXXBuffer() 方法,将源字节缓冲区转换成特定类型的缓冲区。新缓冲区的内容将从此缓冲区的当前位置开始。此缓冲区内容的更改,在新缓冲区中是可见的,反之亦然。这两个缓冲区的位置、限制和标记值是相互独立的。新缓冲区的位置将为 0,其容量和限制与所转换的视图缓冲区类型有关,比如,将字节缓冲区通过 asCharBuffer() 方法转换成字符缓冲区,那么新的字符缓冲区的容量和限制将为源字节缓冲区中所剩字节数的 1/2 ,其标记时不确定的。当且仅当源缓冲区为直接缓冲区时,新缓冲区才是直接缓冲区;当且仅当源缓冲区是只读缓冲区时,新缓冲区才是只读缓冲区。
注意:
当缓冲区类型转换后,再读取时,需要注意其读写时的编码,如果编码不一致,会导致中文乱码。解决办法就是调整在转换前后的读写编码一致。
返回值类型 | 方法名 | 作用 |
CharBuffer | asCharBuffer() | 创建此字节缓冲区的视图,作为 char 缓冲区。新的字符缓冲区的容量和限制将为源字节缓冲区中所剩字节数的 1/2 |
DoubleBuffer | asDoubleBuffer() | 创建此字节缓冲区的视图,作为 double 缓冲区。新的字符缓冲区的容量和限制将为源字节缓冲区中所剩字节数的 1/8 |
FloatBuffer | asFloatBuffer() | 创建此字节缓冲区的视图,作为 float 缓冲区。新的字符缓冲区的容量和限制将为源字节缓冲区中所剩字节数的 1/4 |
IntBuffer | asIntBuffer() | 创建此字节缓冲区的视图,作为 int 缓冲区。新的字符缓冲区的容量和限制将为源字节缓冲区中所剩字节数的 1/4 |
LongBuffer | asLongBuffer | 创建此字节缓冲区的视图,作为 long 缓冲区。新的字符缓冲区的容量和限制将为源字节缓冲区中所剩字节数的 1/8 |
ShortBuffer | asShortBuffer() | 创建此字节缓冲区的视图,作为 float 缓冲区。新的字符缓冲区的容量和限制将为源字节缓冲区中所剩字节数的 1/2 |
只读缓冲区
通过 asReadOnlyBuffer() 方法创建共享此缓冲区内容的只读缓冲区。新缓冲区的内容将为此缓冲区的内容。此缓冲区内容的更改在新缓冲区中是可见的,但是新缓冲区是只读,不允许修改共享内容。两个缓冲区的位置、限制和标记值是相互独立的。新缓冲区的容量、限制、位置和标记值将于此缓冲区相同。
压缩缓冲区
将缓冲区的当前位置和限制之间的字节(如果有)复制到缓冲区的开始处。即将所有 p = position() 处的字节复制到索引 0 处,将索引 p+1 处的字节复制到索引 1 处,以此类推,直到将索引 limit() – 1 处的字节复制到索引 n = limit() – 1 – p 处。然后,将缓冲区的位置设置为 n + 1 ,并且将其限制设置为其容量。如果已定义了标记,则丢弃它。
| //. 缓冲区中的内容 | |
| ||2|3|4|5|6|7|8|9| | |
| //. 执行读取操作到索引 3 处 | |
| ||2|3|>4|5|6|7|8|9| | |
| //. 经过 compact 压缩后缓冲区数据内容为 | |
| ||5|6|7|8|9|7|8|9| |
复制缓冲区
通过 duplicate() 方法创建共享此缓冲区内容的新的缓冲区。新缓冲区的内容将为此缓冲区的内容。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然。在创建新缓冲区时,容量、限制、位置和标记值将与此缓冲区相同,但是这两个缓冲区的位置、限制和标记值是相互独立的。当且仅当此缓冲区为直接缓冲区时,新缓冲区才是直接缓冲区;当且仅当此缓冲区为只读缓冲区时,新缓冲区才是只读缓冲区。
截取缓冲区
通过 slice() 方法创建新的字节缓冲区,其内容是此缓冲区内容的共享子序列。新的缓冲区内容将从此缓冲区的当前位置开始。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然。这两个缓冲区的位置、限制和标记是相互独立的。新缓冲区的位置将为 0,其容量和限制为此缓冲区中所剩余的字节数量,标记是不确定的。当且仅当此缓冲区为直接缓冲区时,新缓冲区才是直接缓冲区;当且仅当此缓冲区为只读缓冲区时,新缓冲区才是只读缓冲区。
比较缓冲区的内容
比较缓冲区内容是否相同有两种方法: equals() 和 compareTo() 。这两种方法还是有使用细节上的区别。
| public boolean equals(Object ob) { | |
| //. 如果比较的是同一个对象,则直接返回 true | |
| if (this == ob) | |
| return true; | |
| //. 如果所比较的对象非 ByteBuffer 类型对象,直接返回 false | |
| if (!(ob instanceof ByteBuffer)) | |
| return false; | |
| //. 将所比较的对象转换成 ByteBuffer 类型,然后比较两者剩余元素个数,即 remaing 值,如果不相等,直接返回 false | |
| ByteBuffer that = (ByteBuffer)ob; | |
| if (this.remaining() != that.remaining()) | |
| return false; | |
| //. 倒叙逐个比较两个 ByteBuffer 对象剩余元素是否相同,如果有一个不同,则直接返回 false。 | |
| int p = this.position(); | |
| for (int i = this.limit() -, j = that.limit() - 1; i >= p; i--, j--) | |
| if (!equals(this.get(i), that.get(j))) | |
| return false; | |
| return true; | |
| } |
从源码中可以看出 equals() 方法比较的是两个 ByteBuffer 对象中剩余元素是否相等,包括个数及每个元素的序列值。而两个缓冲区的容量可以不同。
| public int compareTo(ByteBuffer that) { | |
| /** | |
| *.在此缓冲区的基础上,计算需要比较的元素终点位置。 | |
| * 以当前位置为起点,加上两个 ByteBuffer 对象最小的剩余元素个数为终点 | |
| * 说明判断范围是两个 ByteBuffer 对象的 remaining 的交集 | |
| **/ int n = this.position() + Math.min(this.remaining(), that.remaining()); | |
| //. 正序比较两个 ByteBuffer 对象 remaining 交集中的元素是否相同,如果有一个不同,返回两者的差值 thisIndex - thatIndex | |
| for (int i = this.position(), j = that.position(); i < n; i++, j++) { | |
| int cmp = compare(this.get(i), that.get(j)); | |
| if (cmp !=) | |
| return cmp; | |
| } | |
| //. 如果交集中的元素都相同,那么比较两个 ByteBuffer 对象的 remaining 元素个数,返回两者的差值 thisRemaining - thatRemaining | |
| return this.remaining() - that.remaining(); | |
| } |
源码可以看出 compareTo 方法也是比较的两个 ByteBuffer 对象的剩余元素,只不过返回的是某个字节序列的差值或者两个 remaining 的差值。与两个缓冲区的容量无关,这一点与 equals() 方法一致。
- 如果两个 ByteBuffer 对象的 remaining 交集中有一个元素的序列值不相等,那么返回他们的差值。
- 如果两个 ByteBuffer 对象的 remaining 交集中的所有元素的序列值都相等,在进行比较两个 ByteBuffer 对象的 remaining 个数,并返回他们的差值。
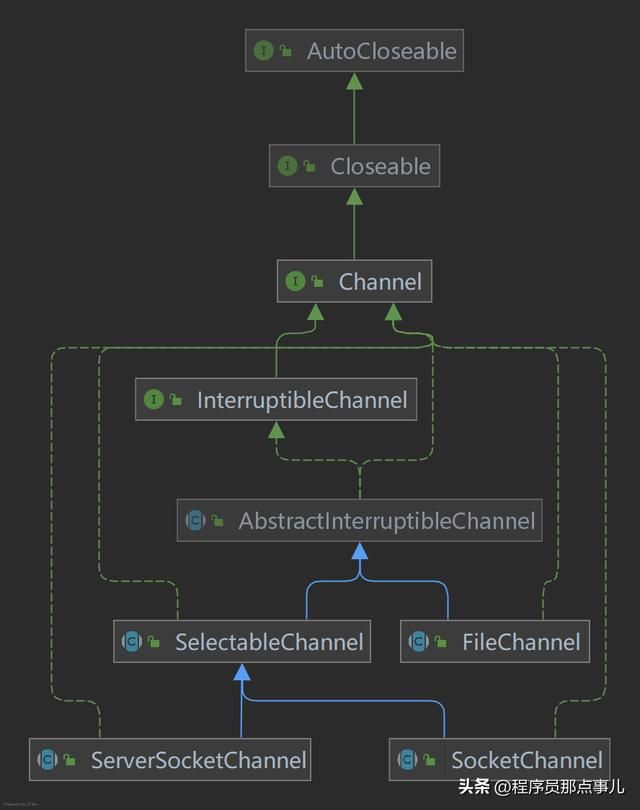
Channel
缓冲区是将数据进行打包,而通道是将数据进行传输。缓冲区是类,而通道都是接口,因为通道的功能实现是要依赖操作系统的, Channel 接口只定义有哪些功能,而功能的具体实现在不同的操作系统中是不一样的。
通道是用于 IO 操作的连接,可处于打开或关闭两种状态,当创建通道时,通道就处于打开状态,一旦将其关闭,则保持关闭状态。通过 isOpen() 方法可以测试通道是否处于打开状态,避免出现 close dChannelException 异常。
Channel 接口类图结构

Channel接口类图
AutoCloseable 接口
AutoCloseable 接口的作用是可以自动关闭,而不需要显示地调用 close() 方法。 AutoCloseable 接口强调的是与 try() 结合实现自动关闭。该接口之定义了一个 close() 方法,因为针对的是任何资源的关闭,而不只是 I/O ,因此 close() 方法抛出的是 Exception 异常。而且该接口不要求是幂等的,也就是重复调用此接口的 close() 方法会出现副作用。
| public class DBOperate implements AutoCloseable { | |
| public void close() throws Exception { | |
| System.out.println("关闭连接"); | |
| } | |
| } | |
| public class Test { | |
| public static void main(String[] args){ | |
| try (DBOprate dbo = new DBOprate()){ | |
| System.out.println("开始数据库操作"); | |
| }catch (Exception e){ | |
| e.printStackTrace(); | |
| } | |
| } | |
| } | |
| //输出结果: | |
| 开始数据库操作 | |
| 关闭连接 |
Closeable 接口
Closeable 接口继承自 AutoCloseable 接口,其作用是关闭 I/O 流,释放系统资源,所以该接口的 close() 方法抛出 IOException 异常。该接口的 close() 方法是幂等的,可以重复调用此接口的 close() 方法,而不会出现任何效果与影响。
AsynchronousChannel 接口
主要作用是使通道支持异步 I/O 操作。异步 I/O 操作有以下两种方式进行实现:
- 方法 Future<V> operation (…)
- Future 对象可以用于检测 I/O 操作是否完成,或者等待完成,以及用于接收 I/O 操作处理后的结果。但是需要开发人员编写检测逻辑。
- 回调 void operation (… A attachment, CompletionHandler<V,? super A> handler)
- A 类型的对象 attachment 的主要作用是让外部与 CompletionHandler 对象内部进行通信。有点是 CompletionHandler 对象可以被复用,当 I/O 操作成功或失败时, CompletionHandler 对象中的指定方法会自动被调用,不需要开发人员编写检测的逻辑。
异步通道在多线程并发的情况下是线程安全的。某些通道的实现是可以支持并发读和写的,但是不允许在一个未完成的 I/O 操作上再次调用 read 或 wwrite 操作。
异步通道支持取消操作,通过调用 Future 接口定义的 cancel() 方法来取消执行,这会导致那些等待处理 I/O 结果的线程抛出 CancellationException 异常。
AsynchronousByteChannel 接口
主要作用是使通道支持异步 I/O 操作,操作单位为字节。在上一个 read() 或 write() 方法未完成之前再次调用,会抛出 ReadPendingException 或者 WritePendingException 异常。
ByteBuffer 类不是线程安全的,尽量保证在对其进行读写操作时,没有其他线程一同进行读写操作。
ReadableByteChannel 接口
主要作用是使通道运行对字节进行读操作。该接口只允许有 1 个读操作在进行,如果 1 个线程正在 1 个通道上执行 1 个 read() 操作,那么任何试图发起另一个 read() 操作的线程都会被阻塞,直到第 1 个 read() 操作完成。即该接口的 read() 方法是同步的。
该通道只接受以字节为单位的数据处理,因为通道和操作系统进行交互时,操作系统只接受字节数据。
ScatteringByteChannel 接口
主要作用是可以从通道中读取字节到多个缓冲区中。
WritableByteChannel 接口
主要作用是使通道运行对字节进行写操作。将字节缓冲区中的字节序列写入到通道的当前位置,该接口只允许有 1 个写操作在进行,如果 1 个线程正在 1 个通道上执行 1 个 write() 操作,那么任何试图发起另一个 write() 操作的线程都会被阻塞,直到第 1 个 write() 操作完成。即该接口的 write() 方法是同步的。
GatheringByteChannel 接口
主要作用是可以将多个缓冲区中的数据写入到通道中。
ByteChannel 接口
主要作用是将 ReadableByteChannel (可读字节通道)与 WritableByteChannel (可写字节通道)的规范进行了统一。 ByteChannel 没有添加任何新的方法就实现了具有读和写的功能,是双向的操作。
SeekableByteChannel 接口
主要作用是在字节通道中维护 position ,以及允许 position 发生改变。
NetworkChannel 接口
主要作用是使通道与 Socket 进行关联,使通道中的数据能在 Socket 技术上进行传输。
MulticastChannel 接口
主要作用是使通道支持 Internet Protocol(IP) 多播。也就是将多个主机地址进行打包,形成一个组( group ),然后将 IP 报文向这个组进行发送,也就相当于同时向多个主机传输数据。
InterruptibleChannel 接口
主要作用是使通道能以异步的方式进行关闭与中断。
FileChannel 类的使用
以 FileChannel 为例来介绍下通道( Channel )的一般常用操作,不同的通道虽然 Channel 类型不同,但是在程序中所起到的作用是相同的,再结合上述的接口类图,根据不同类型的 Channel 接口实现可以实现特定的功能。

FileChannel类图
通过类图分析得知 FileChannel 是一个可以读取、写入、可中断和操作文件的通道:
- 实现了 WritebleByteChannel 和 ReadableByteChannel 类型的接口,说明支持读和写操作;
- 继承了 AbstractInterruptibleChannel 类,说明是一个可中断的通道;
- 没有实现 AsynchronousChannel 类型的接口,所以 FileChnnel 不支持异步,永远是阻塞的操作;
FileChannel 在内部维护当前文件的 position ,可对其进行查询和修改。该文件本身包含一个可读写、长度可变的字节序列,并且可以查询该文件的当前大小。当写入的字节超出文件的当前大小时,则增加文件的大小;截取该文件时,则减小文件的大小;但此类未定义访问元数据的方法,所以无法访问文件的元数据,比如:权限、内容类型和最后修改时间等。
除了通道常见的读、写和关闭操作外,此类还定义了下列特定于文件的操作:
- 以不影响通道当前位置的方式,对文件中绝对位置的字节进行读取或写入;
- 将文件中的某个区域直接映射到内存中。对于较大的文件,这通常比调用普通的 read() 或 write() 方法更有效;
- 强制对底层存储设备进行文件的更新,确保在系统崩溃时不丢失数据;
- 以一种可被很多操作系统优化为直接向文件系统缓存发送或从中读取的高速传输方法,将字节从文件传输到某个其他通道中,反之亦然;
- 可以锁定某个文件区域,以阻止其他程序对其进行访问;
FileChannel 类没有定义打开现有文件通道或创建新文件通道的方法,可通过调用现有的 FileInputStream 、 FileOutputStream 、或 RandomAccessFile 对象的 getChannel() 方法来获得。
- 通过 FiltInputStream 实例的 getChannel() 方法获得的通道将允许进行读取操作;
- 通过 FileOutputStream 实例的 getChannel() 方法获得的通道将允许进行写入操作,如果输出流对象是通过 FileOutputStream(File,boolean) 构造方法且第二个参数传入 true 创建的,则该通道模式可能处于添加模式,每次调用相关的写入操作都会首先将位置移动到文件的末尾,然后写入请求的数据;
- 通过调用通过 r 模式创建的 RandomAccessFile 实例的 getChannel() 方法获得的通道将允许进行读取操作, RandomAccessFile 实例是通过 rw 模式创建,那么获得的通道将允许进行读取和写入操作;
返回值类型 | 方法名 | 作用 |
int | write(ByteBuffer src) | 同步方法,将给定 ByteBuffer 的 remaining 字节序列写入到通道的当前位置; |
int | read(ByteBuffer dst) | 同步方法,将字节序列从通道的当前位置读入给定的缓冲区的当前位置,如果该通道已到达流的末尾,则返回 -1;正数 – 代表读入缓冲区的字节个数;0 – 代表从通道中没有读取任何字节,可能发生的情况就是缓冲区中没有 remaining 剩余空间了;-1 – 代表到达流的末端; |
long | write(ByteBuffer[] srcs) | 同步方法,将给定的缓冲区数组中的每个缓冲区的 remaining 字节序列写入到通道的当前位置; |
long | read(ByteBuffer[] dsts) | 同步方法,从此通道当前位置开始将通道中剩余的字节序列,读入到多个给定的字节缓冲区中;如果通道中可读出来的数据大于 ByteBuffer[] 缓冲区组总共的容量,那么 ByteBuffer[] 缓冲区组总共的容量多少,就读取多少字节的数据 |
long | write(ByteBuffer[] srcs, int offset, int length) | 同步方法,以指定缓冲区数组的 offset 下标开始,向后使用 length 个字节缓冲区,再将每个缓冲区的 remaining 剩余字节序列写入到此通道的当前位置; |
long | read(ByteBuffer[] dsts, int offset, int length) | 同步方法,将通道中当前位置的字节序列读入以下标为 offset 开始的 ByteBuffer[] 数组中的 remaining 剩余空间中,并且连续写入 length 个 ByteBuffer 缓冲区; |
int | write(ByteBuffer src, long position) | 将缓冲区的 remaining 字节序列写入通道的指定位置;如果给定的位置大于该文件的当前大小,则该文件将扩大以容纳新的字节,在文件末尾和新写入字节之间的字节值是未指定的;该方法不影响此通道的当前位置; |
int | read(ByteBuffer dst, long position) | 将通道的指定位置的字节序列读入给定的缓冲区的当前位置;如果给定的位置大于该文件的当前大小,则不读取任何字节;该方法不影响此通道的当前位置; |
long | position(long newPosition) | 设置此通道的当前位置。当设置为大于当前文件大小的值时,并不会改变文件的大小,稍后试图在这样的位置读取字节将立即返回已到达文件末尾的指示,稍后试图在这样的位置写入字节将导致文件扩大,以容纳新的字节,在原来的文件位置和新设置的文件位置之间的字节值时未指定的; |
long | size() | 返回此通道所关联文件的当前大小; |
FileChannel | truncate(long sieze) | 将此通道所关联文件截取为给定大小。如果给定大小小于该文件的当前大小,则截取该文件,丢弃文件新末尾后面的所有字节;如果给定大小大于或等于该文件的当前大小,则不修改文件;如果该通道的位置大于给定的大小,则将位置设置为给定的大小; |
long | transferTo(long position, long count, WritableByteChannel dest) | 将字节从此通道的文件传输到给定的可写入字节通道。读取从此通道的文件中给定 position 处开始的 count 个字节,并将其写入目标通道的当前位置。如果此通道的文件从给定的 position 处开始包含的字节数小于 count 个字节,或者如果目标通道是非阻塞的并且其输出缓冲区中的自由空间少于 count 个字节,则所传输的字节数小于请求的字节数;该方法不影响此通道的当前位置;如果给定的 position 位置大于当前文件的大小,则不传输任何字节; |
long | transferFrom(ReadableByteChannel src, long position, long count) | 将字节从给定的可读取字节通道传输到此通道的文件中。试着从源通道 src 中最多读取 count 个字节,并将其写入到此通道的文件中从给定的 position 处开始的位置;如果源通道的剩余空间小于 count 个字节,或者如果源通道是非阻塞的并且其输入缓冲区中直接可用的空间小于 count 个字节,则所传输的字节数要小于请求的字节数;如果给定的位置大于该文件的当前大小,则不传输任何字节;该方法不影响此通道的当前位置; |
FileLock | lock(long position, long size, boolean shared) | 同步方法,获取此通道的文件给定区域上的锁定。在可以锁定该区域之前、已关闭此通道之前或者已中断调用线程之前(以先到者为准),将阻塞此方法的调用;在此方法调用期间,如果另一个线程关闭了此通道,则抛出 AsynchronousCloseException 异常;如果在等待获取锁定的同时中断了调用线程,则将状态设置为中断并抛出 FileLockInterruptionException 异常。如果调用此方法时已设置调用方的中断状态,则立即抛出该异常;不更改线程的中断状态;lock() 方法只锁定大小为 Long.MAX_VALUES 的区域;文件锁要么是独占的,要么是共享的。共享锁定可以阻止其他并发运行的程序获取重叠的独占锁定,但是允许该程序获取重叠的共享锁定。独占锁定则阻止其他程序获取共享或独占类型的重叠锁定;某些操作系统不支持共享锁定,这种情况下,自动将对共享锁定的请求转换为对独占锁定的请求; |
FileLock | tryLock(long position, long size, boolean shared) | 试图获取对此通道的文件给定区域的锁定。此方法不会阻塞,无论是否成功获取请求区域上的锁定,都会立即返回;如果由于另一个程序保持着一个重叠锁定而无法获取锁定,此方法返回 null,其他原因则抛出异常; |
void | force(boolean metaData) | 强制将所有对此通道的文件更新写入包含该文件的存储设备中。如果此通道的文件驻留在本地存储设备上,此方法返回时可以保证:在此通道创建后或在最后一次调用此方法后,对该文件进行的所有更改都写入存储设备中。这对确保在系统崩溃时不会丢失重要信息特别有用。如果该文件不再本地设备商,则无法提供这样的保证。metaData 参数可用于限制此方法是否必须更新文件元数据信息,fase 表示对文件内容的更新写入存储设备; true 表示必须写入对文件内容和元数据的更新,这通常需要一个以上的 I/O 操作。此参数是否有效取决于底层操作系统;调用此方法可能导致发送 I/O 操作,即使该通道仅允许进行读取操作时也是如此,例如,某些操作系统将最后一次访问的时间作为元数据的一部分进行维护,每当读取问件时就更新此时间,但实际是否会执行 I/O 操作还是与操作系统相关;该方法只能保证强制进行通过此类中已定义的方法对此通道的文件所进行的更改,而不一定强制那些通过修改已映射字节缓冲区的内容所进行的更改。 |
FileLock 类具有平台依赖性,此文件锁定 API 直接映射到底层操作系统的本机锁定机制。因此,无论程序使用何种语言编写的,某个文件上所保持的锁定对于所有访问该文件的程序来说都应该是可见的。
关于 force(boolean metaData) 强制更新
其实在调用 FileChannel 类的 Write() 方法时,操作系统为了运行的效率,显示把那些将要保存到硬盘上的数据暂时放入操作系统的缓存中,以减少硬盘的读写次数,然后在某一个时间点再将内核缓存中的数据批量地同步到硬盘中,但同步的时间却是由操作系统决定的。通过 force(boolean metaData) 强制进行同步,这样做的目的是防止在系统崩溃或断电时缓存中的数据丢失而造成损失。但是, force(boolean metaData) 方法并不能完全保证数据不丢失,如果正在执行 force(boolean metaData) 方法时出现断电的情况,那么硬盘上的数据有可能就不是完整的,而且由于断电的原因导致内核缓存中的数据也丢失了,最终造成的结果就是 force(boolean metaData) 方法执行了,数据也有可能丢失。所以, force(boolean metaData) 方法的最终目的是尽最大的努力减少数据的丢失。
内存映射
通过 MappedByteBuffer map(FileChannel.MapMode mode, long position, long size) 方法可以将此通道的文件区域直接映射到内存中。
映射模式有以下 3 种:
- 只读( MapMode.READ_ONLY ):试图修改得到的缓冲区将抛出 ReadOnlyBufferException 异常。
- 读取/写入( MapMode.READ_WRITE ):对得到的缓冲区的更改最终将传播到文件;该更改对映射到同一文件的其他程序不一定是可见的。
- 专用( MapMode.PRIVATE ):对得到的缓冲区的更改不会传播到文件,并且该更改对映射到同一文件的其他程序也是不可见的;相反,会创建缓冲区已修改部分的专用副本。
对于只读映射关系,此通道必须可以进行读取操作;对于读取/写入或专用映射关系,此通道必须可以进行读取和写入操作。
映射关系一经创建,就不再依赖于创建它时所用的文件通道。特别是关闭该通道对映射关系的有效性没有任何影响。
对于大多数操作系统而言,与通过普通的 read() 和 write() 方法读取或写入数千字节的数据相比,将文件映射到内存中开销更大。从性能的观点来看,通常将相对较大的文件映射到内存中才是值得的。
MappedByteBuffer 类的 force() 方法的作用是将此缓冲区所做的更改强制写入包含映射文件的存储设备中。如果此缓冲区不是以读/写模式映射的,则调用此方法无效。
零拷贝
零拷贝( Zero-copy )技术是指计算机执行操作时, CPU 不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。——百度百科
如果要读取一个文件并通过网络发送它,传统方式下每个读/写周期都需要复制两次数据和切换两次上下文(用户空间和内核空间之间的切换),而数据的复制都需要依靠CPU。通过零复制技术完成相同的操作,上下文切换减少到两次,并且不需要CPU复制数据。
传统I/O操作

BIO
- 读虚拟机会从用户空间向内核空间发起一个读命令的系统调用,由用户空间模式切换到内核空间模式(一次上下文切换)。内核空间通过 DAM 将数据读取到内核空间的一个缓冲区(第一次拷贝)完成真正向磁盘读取数据的请求,。 将内核空间缓冲区中的数据通过 CPU 再次拷贝到用户空间的缓冲区中(第二次拷贝)。 读取操作完成,程序对数据业务处理。
- 写虚拟机从用户空间向内核空间发起一个写命令的系统调用,将用户空间缓冲区中的数据通过 CPU 拷贝到内核空间缓冲区。并由用户空间模式切换到内核空间模式(一次上下文切换和一次数据拷贝)。 内核空间通过DAM完成数据写入网络的功能(第二次拷贝,将数据拷贝到协议栈)。并返回内核空间。内核空间将结果反馈给用户空间(第二次上下文切换)。结束。
代码示例
| File file = new File("test.txt"); | |
| RandomAccessFile = raf = new RandomAccessFile(file,"rw"); | |
| byte[] arr = new byte[(int)file.length()]; | |
| raf.read(arr); | |
| Socket socket = new ServerSocket().accept(); | |
| socket.getOutputStream().write(arr); |
这段代码就是读取一个本地文件内容,然后再将其内容通过 Socket 连接写出去。看起来就几行代码,但是涉及到多次内存拷贝。其流程如下:
- 读取需要文件内容将文件内容通过 DMA(Direct memory access) (直接内存访问) 拷贝到系统内核的 buffer 中; 在内核 buffer 中通过 CPU 拷贝到用户 buffer 中;
- 写输入将数据从用户 buffer 通过 CPU 拷贝到 socket buffer 中; socket buffer 通过 DMA(Direct memory access) (直接内存访问)拷贝到协议栈;
Java NIO 操作
Java NIO 中的 transferTo 可以实现零拷贝。零拷贝,并不是不拷贝,而是整个过程不需要进行 CPU 拷贝。

NIO
首先还是通过 DAM 拷贝到内核空间的 buffer 中,然后再通过 CPU 拷贝到 socket buffer ,最后由 DAM 拷贝到协议栈。但这次的 CPU 拷贝内容很少,只拷贝内核 buffer 的长度、偏移量等信息,消耗很低,可以忽略。因此称为零拷贝。减少了用户空间与内核空间的相互切换和数据拷贝次数。
代码示例
传统 I/O 拷贝大文件
| /** | |
| * 服务端 | |
| */public class OldIoServer { | |
| public static void main(String[] args) throws IOException { | |
| ServerSocket serverSocket = new ServerSocket(); | |
| while (true) { | |
| Socket socket = serverSocket.accept(); | |
| DataInputStream dataInputStream = new DataInputStream(socket.getInputStream()); | |
| byte[] byteArray = new byte[]; | |
| while (true) { | |
| int readCount = dataInputStream.read(byteArray,, byteArray.length); | |
| if (- == readCount) { | |
| break; | |
| } | |
| } | |
| } | |
| } | |
| } | |
| /** | |
| * 客户端 | |
| */public class OldIoClient { | |
| public static void main(String[] args) throws Exception { | |
| Socket socket = new Socket(".0.0.1", 6666); | |
| // 需要拷贝的文件 | |
| String fileName = "E:downloadsoftwindowsjdk-u171-windows-x64.exe"; | |
| InputStream inputStream = new FileInputStream(fileName); | |
| DataOutputStream dataOutputStream = new DataOutputStream(socket.getOutputStream()); | |
| byte[] buffer = new byte[]; | |
| long readCount; | |
| long total =; | |
| long start = System.currentTimeMillis(); | |
| while ((readCount = inputStream.read(buffer)) >=) { | |
| total += readCount; | |
| dataOutputStream.write(buffer); | |
| } | |
| long end = System.currentTimeMillis(); | |
| System.out.println("传输总字节数:" + total + ",耗时:" + (end - start) + "毫秒"); | |
| dataOutputStream.close(); | |
| inputStream.close(); | |
| socket.close(); | |
| } | |
| } |
这里拷贝了一个 JDK ,最后运行结果如下:
传输总字节数:,耗时:4803毫秒
使用 Java NIO 的 transferTo 拷贝
| /** | |
| * 服务端 | |
| */public class NioServer { | |
| public static void main(String[] args) throws IOException { | |
| InetSocketAddress address = new InetSocketAddress(); | |
| ServerSocketChannel serverSocketChannel = ServerSocketChannel.open(); | |
| ServerSocket serverSocket = serverSocketChannel.socket(); | |
| serverSocket.bind(address); | |
| ByteBuffer buffer = ByteBuffer.allocate(); | |
| while (true) { | |
| SocketChannel socketChannel = serverSocketChannel.accept(); | |
| int readCount =; | |
| while (- != readCount) { | |
| readCount = socketChannel.read(buffer); | |
| buffer.rewind(); // 倒带,将position设置为,mark设置为-1 | |
| } | |
| } | |
| } | |
| } | |
| /** | |
| * 客户端 | |
| */public class NioClient { | |
| public static void main(String[] args) throws IOException { | |
| SocketChannel socketChannel = SocketChannel.open(); | |
| socketChannel.connect(new InetSocketAddress(".0.0.1", 6666)); | |
| String fileName = "E:downloadsoftwindowsjdk-u171-windows-x64.exe"; | |
| FileChannel channel = new FileInputStream(fileName).getChannel(); | |
| long start = System.currentTimeMillis(); | |
| // 在linux下,transferTo方法可以一次性发送数据 | |
| // 在windows中,transferTo方法传输的文件超过M得分段 | |
| long totalSize = channel.size(); | |
| long transferTotal =; | |
| long position =; | |
| long count = * 1024 * 1024; | |
| if (totalSize > count) { | |
| BigDecimal totalCount = new BigDecimal(totalSize).divide(new BigDecimal(count)).setScale(, RoundingMode.UP); | |
| for (int i=; i<=totalCount.intValue(); i++) { | |
| if (i == totalCount.intValue()) { | |
| transferTotal += channel.transferTo(position, totalSize, socketChannel); | |
| } else { | |
| transferTotal += channel.transferTo(position, count + position, socketChannel); | |
| position = position + count; | |
| } | |
| } | |
| } else { | |
| transferTotal += channel.transferTo(position, totalSize, socketChannel); | |
| } | |
| long end = System.currentTimeMillis(); | |
| System.out.println("发送的总字节:" + transferTotal + ",耗时:" + (end - start) + "毫秒"); | |
| channel.close(); | |
| socketChannel.close(); | |
| } | |
| } |
运行结果如下:
发送的总字节:,耗时:415毫秒
从结果可以看到, BIO 与 NIO 耗时相差一个数量级, NIO 只要0.4s,而 BIO 要4s。所以在网络传输中,使用 NIO 的零拷贝,可以大大提高性能。
Selector
Selector 与 I/O 多路复用
Selector 称为选择器,可以将通道注册进选择器中,选择器与通道之间属于一对多的关系,也就是使用 1 个线程来操作多个通道。主要作用就是使用 1 个线程来对多个通道中已就绪的通道进行选择,然后就可以对选择的通道进行数据处理。这种机制在 NIO 技术中称为 I/O 多路复用。它的优势是可以节省 CPU 资源,因为只有 1 个线程, CPU 不需要在不同的线程间进行上下文切换(线程的上下文切换是一个非常耗时的动作),并且因为线程对象的数量大幅减少,降低了内存占用率,这对设计高性能服务器具有很重要的意义。
多路复用的核心目的是使用最少的线程去操作更多的通道,在其内部其实并不永远只是一个线程,线程数量会随着通道的多少而动态地增减以进行适配。在 JDK 源码中,创建线程的个数是根据通道的数量来决定的,每注册 1023 个通道就创建 1 个新的线程。
注意:
在使用 I/O 多路复用时,这个线程不是以 for 循环的方式来判断每个通道是否有数据进行处理,而是以操作系统底层作为”通知器”,来 “通知 JVM 中的线程”哪个通道中的数据需要进行处理。当不使用 for 循环的方式来进行判断,而是使用通知的方式时,这就大大提高了程序运行的效率,不会出现无限期的 for 循环迭代空运行了。
Selector 类是抽象类,是 SelectableChannel 对象的多路复用器。也就是说只有 selectableChannel 通道才能被 Selector 所复用。
通过 Selector.open() 方法来获得一个 Selector 对象。 open() 方法内部又是通过 SelectorProvider 对象来获取/打开一个选择器并返回的。 SelectorProvider 类的作用是用于选择器和可选择通道的服务提供者类,给定的对 Java 虚拟机的调用维护了单个系统级的默认提供者实例,它由 provider() 方法返回。
在通过调用选择器的 close() 方法关闭选择器之前,选择器一直保持打开状态。
通过 SelectionKey 对象来表示 SelectableChannel 到选择器的注册。选择器维护了 3 种 SelectionKey-Set (选择键集),在新建的选择器中,这 3 个集合都是空集合:
- 键集:包含的键表示当前通道到此选择器的注册,也就是通过某个通道的 register() 方法注册该通道时,所带来的的影响是向选择器的键集中添加了一个键。此集合由 keys() 方法返回。键集本身是不可直接修改的。
- 已选择键集:在首先调用 select() 方法选择期间,检测每个键的通道是否已经至少为该键相关操作集所标识的一个操作准备就绪,然后调用 selectedKeys() 方法返回已就绪键的集合。已选择键集始终是键集的一个子集。
- 已取消键集:标识已被取消但其通道尚未注销的键的集合。不可直接访问此集合。已取消键集始终是键集的一个子集。在 select() 方法选择操作期间,从键集中移除已取消的键。
无论是通过关闭某个键的通道还是调用该键的 cancel() 方法来取消键,该键都被添加到选择器的已取消键集中。取消某个键会导致在下一次 select() 方法选择操作期间注销该键的通道,而在注销时将从所有选择器的键集中移除该键。
通过 select() 方法选择操作将键添加到已选择键集中。可通过调用已选择键集的 remove() 方法,或者通过调用从该键集获得的 iterator 的 remove() 方法直接移除某个键。通过任何其他方式都无法直接将键从已选择键集中移除。无法将键直接添加到已选择键集中。
select() 方法返回值的含义是已更新其准备就绪操作集的键的数目,该数目可能为零或非零,非零的情况就是新的准备就绪键的个数。零说明当前没有通道准备就绪,更新准备就绪操作集的键的个数为零,如果没有调用 remove() 方法,此时准备就绪操作集的键与上次保持一致。
注意:
在每次处理完一个已选择键对应的事件后,需要手动调用 remove() 方法将其从已选择键集中移除,不然会造成重复消费的情况,导致程序异常。
在每次 select() 操作期间,都可以将键添加到选择器的已选择键集或从中将其移除,并且可以从其键集合已取消键集中移除。涉及以下 3 个步骤:
- 将已取消键集中的每个键从所有键集中移除,并注销其通道。此步骤使已取消键集成为空集。
- 在开始进行 select() 方法选择操作时,应查询基础操作系统来更新每个剩余通道的准备就绪信息,以执行由其键的相关集合所标识的任意操作。 如果该通道的键尚未在已选择键集中,则将其添加到该集合中,并修改其准备就绪操作集,以准确的标识那些通道现在已报告为之准备就绪的操作。丢弃准备就绪操作集中以前记录的所有准备就绪信息。如果该通道已经在已选择键集中,则修改其准备就绪操作集,以准确的标识所有通道已报告为之准备就绪的新操作。保留准备就绪操作以前记录记录的所有准备就绪信息。换句话说,基础系统所返回的准备就绪操作集是和该键的当前准备就绪操作集按位分开的。 如果在此步骤开始时键集中的所有键都为空的相关集合,则不会更新已选择键集合任意键的准备就绪操作集。
- 如果在步骤 2 进行时已将任何键添加到已取消的键集,则他们按照步骤 1 进行处理。
在执行选择操作的过程中,更改选择器键的相关集合对该操作没有影响,在进行下一次选择操作时才会看到此更改。一般情况下,选择器的键和已选择键集由多个并发线程使用是不安全的。
返回值类型 | 方法名 | 作用 |
int | select() | 同步操作,选择一组键,其相应的通道已为 I/O 操作准备就绪 |
int | select(long timeout) | 在指定时间内同步操作,选择一组键,其相应的通道已为 I/O 操作准备就绪。如果 timeout 参数为 0 则无限期地阻塞 |
int | selectNow() | 非阻塞操作,选择一组键,其相应的通道已为 I/O 操作准备就绪 |
SelectionKey
SelectionKey 表示 SelectableChannel 在选择器中的注册的标记。
SelectionKey 支持将单个任意对象附加到某个键的操作。可通过 attach() 方法附加对象,然后通过 attachment() 方法获取该对象。
返回值类型 | 方法名 | 作用 |
SelectableChannel | cancel() | 将 SelectionKey 放入取消键集中,并且在下一次执行 select() 方法是删除这个 SelectionKey 所有的键集,并且注销其对应的通道。 |
boolean | isAcceptable() | 测试此键的通道是否已准备好接受新的套接字连接。 |
boolean | isConnectable() | 测试此键的通道是否已完成其套接字的连接操作。 |
boolean | isReadable() | 测试此键的通道是否已准备好进行读取。 |
boolean | isWritable() | 测试此键的通道是否已准备好进行写入。 |
Selector | selector() | 返回 SelectionKey 关联的选择器,即使已取消该键,此方法仍然有效。 |
Object | attach(Object obj) | 将给定的对象附加到此键。一次只能附加一个对象,调用此方法会导致丢弃所有以前的附加对象。返回值代表先前已附加的对象(如果有),否则返回 null。 |
Object | attachment() | 获取已附加的对象(如果有),否则返回 null。 |
SelectableChannel
SelectableChannel 类和 FileChannel 类是平级关系,都是继承自父类 AbstractInterruptibleChannel 。抽象类 SelectableChannel 有很多子类,这里只展示了在 Socket 编程中常用的 ServerSocketChannel 和 SocketChannel , 如下图:
SelectableChannel 类可以通过选择器实现多路复用。在与选择器结合使用的时候,首先需要调用 SelectableChannel 对象的 register() 方法在选择器对象里注册当前 SelectableChannel 。
一个通道最多只能在任意特定选择器上注册一次。可以通过 isRegistered() 方法来确定是否已经向一个或多个选择器注册了某个通道。
新创建的 SelectableChannel 总是处于阻塞模式,在结合使用基于选择器的多路复用时,向选择器注册某个通道前,必须先将该通道置于非阻塞模式。
ServerSocketChannel 类是抽象的,可通过其 open() 方法创建实例。其实 ServerSocketChannel 和 SocketChannel 只是对 ServerSocket 和 Socket 的封装,目的就是要结合选择器达到多路复用的效果。单纯的使用 SocketChannel 只是对 ServerSocket 是实现不了 I/O 多路复用的。
SelectionKey register(Selector sel, int ops) 方法的作用是向给定的选择器注册此通道,返回一个选择键( SelectionKey )。参数 sel 代表要向其注册此通道的选择器, ops 参数就是通道感兴趣的时间,也就是通道能执行操作的集合,包括: SelectionKey.OP_ACCEPT – 用于套接字接受操作的操作集位、 SelectionKey.OP_CONNECT – 用于套接字连接操作的操作集位、 SelectionKey.OP_READ – 用于读取操作的操作集位和 SelectionKey.OP_WRITE – 用于写入操作的操作集位。