引语
在1995年5月,Eich 大神在10天内就写出了第一个脚本语言的版本,JavaScript 的第一个代号是 Mocha,Marc Andreesen 起的这个名字。由于商标问题以及很多产品已经使用了 Live 的前缀,网景市场部将它改名为 LiveScript。在1995年11月底,Navigator 2.0B3 发行,其中包含了该语言的原型,这个版本相比之前没有什么大的变化。在1995年12月初,Java 语言发展壮大,Sun 把 Java 的商标授权给了网景。这个语言被再次改名,变成了最终的名字——JavaScript。在之后的1997年1月,标准化以后,就成为现在的 ECMAScript。
近一两年在客户端上用到 JS 的地方也越来越多了,笔者最近接触了一下 JS ,作为前端小白,记录一下近期自己“踩坑”的成长经历。
一. 原始值和对象
在 JavaScript 中,对值的区分就两种:
1.原始值:BOOL,Number,String,null,undefined。 2.对象:每个对象都有唯一的标识且只严格的等于(===)自己。
null,undefined没有属性,连toString( )方法也没有。
false,0,NaN,undefined,null,' ' ,都是false。
typeof 运算符能区分原始值和对象,并检测出原始值的类型。 instanceof 运算符可以检测出一个对象是否是特定构造函数的一个实例或者是否为它的一个子类。
操作数 | typeof |
undefined | 'undefined' |
null | object |
布尔值 | boolean |
数字 | number |
字符串 | string |
函数 | function |
其他的常规值 | object |
引擎创建的值 | 可能返回任意的字符串 |
null 返回的是一个 object,这个是一个不可修复的 bug,如果修改这个 bug,就会破坏现有代码体系。但是这不能表示 null 是一个对象。
因为第一代 JavaScript 引擎中的 JavaScript 值表示为32位的字符。最低3位作为一种标识,表示值是对象,整数,浮点数或者布尔值。对象的标识是000,而为了表现 null ,引擎使用了机器语言 NULL 的指针,该字符的所有位都是0。而 typeof 就是检测值的标志位,这就是为什么它会认为 null 是一个对象了。
所以判断 一个 value 是不是一个对象应该按照如下条件判断:
| function isObject (value) { | |
| return ( value !== null | |
| && (typeof value === 'object' | |
| || typeof value === 'function')); | |
| } |
null 是原型链最顶端的元素
| Object.getPrototypeOf(Object.prototype) | |
| < null |
判断 undefined 和 null 可以用严格相等判断:
| if(x === null) { | |
| // 判断是否为 null | |
| } | |
| if (x === undefined) { | |
| // 判断是否为 undefined | |
| } | |
| if (x === void 0 ) { | |
| // 判断是否为 undefined,void 0 === undefined | |
| } | |
| if (x != null ) { | |
| // 判断x既不是undefined,也不是null | |
| // 这种写法等价于 if (x !== undefined && x !== null ) | |
| } |
在原始值里面有一个特例,NaN 虽然是原始值,但是它和它本身是不相等的。
| NaN === NaN | |
| <false |
原始值的构造函数 Boolean,Number,String 可以把原始值转换成对象,也可以把对象转换成原始值。
| // 原始值转换成对象 | |
| var object = new String('abc') | |
| // 对象转换成原始值 | |
| String(123) | |
| <'123' |
但是在对象转换成原始值的时候,需要注意一点:如果用 valueOf() 函数进行转换的时候,转换一切正确。
| new Boolean(true).valueOf() | |
| <true |
但是使用构造函数将包装对象转换成原始值的时候,BOOL值是不能正确被转换的。
| Boolean(new Boolean(false)) | |
| <true |
构造函数只能正确的提取出包装对象中的数字和字符串。
二. 宽松相等带来的bug
在 JavaScript 中有两种方式来判断两个值是否相等。
- 严格相等 ( === ) 和严格不等 ( !== ) 要求比较的值必须是相同的类型。
- 宽松相等 ( == ) 和宽松不等 ( != ) 会先尝试将两个不同类型的值进行转换,然后再使用严格等进行比较。
宽松相等就会遇到一些bug:
| undefined == null // undefined 和 null 是宽松相等的 | |
| <true | |
| 2 == true // 不要误认为这里是true | |
| <false | |
| 1 == true | |
| <true | |
| 0 == false | |
| <true | |
| ' ' == false // 空字符串等于false,但是不是所有的非空字符串都等于true | |
| <true | |
| '1' == true | |
| <true | |
| '2' == true | |
| <false | |
| 'abc' == true // NaN === 1 | |
| <false |
关于严格相等( Strict equality ) 和 宽松相等( Loose equality ),GitHub上有一个人总结了一张图,挺好的,贴出来分享一下,Github地址在这里
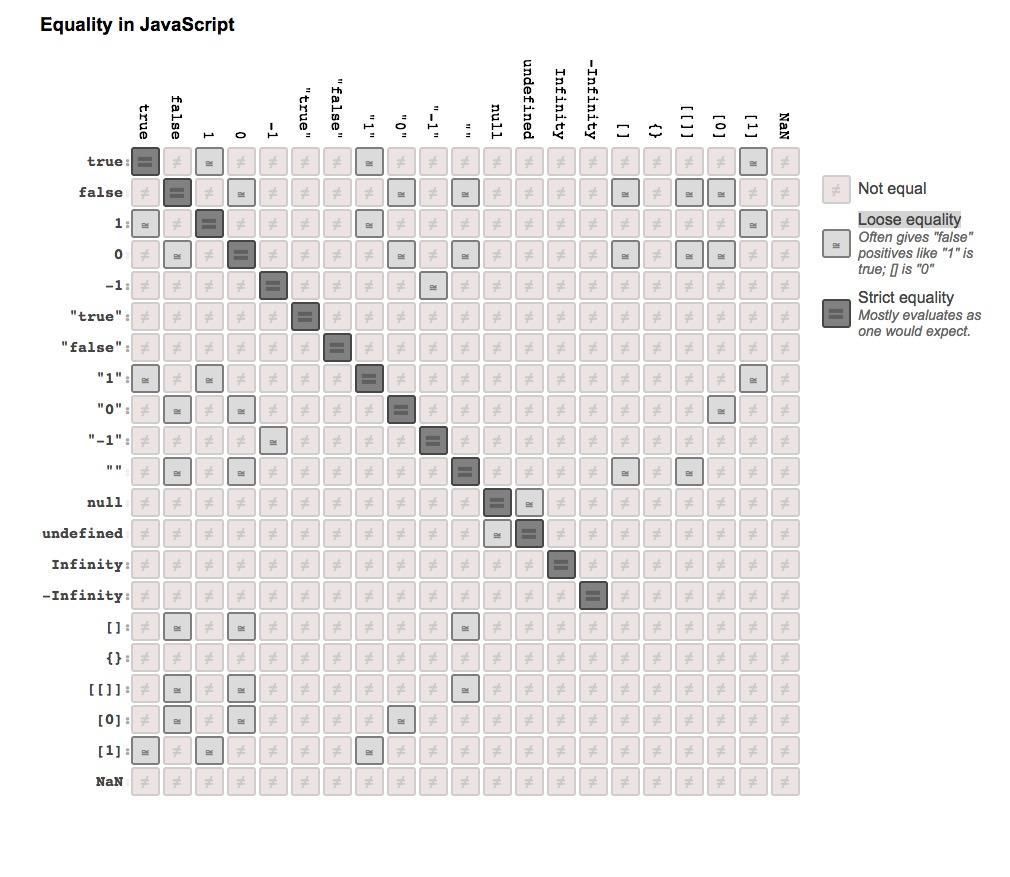
但是如果用 Boolean( ) 进行转换的时候情况又有不同:
值 | 转换成BOOL值 |
undefined | false |
null | false |
BOOL | 与输入值相同 |
数字 | 0,NaN 转换成false,其他的都为 true |
字符串 | ' '转换成false,其他字符串都转换成true |
对象 | 全为true |
这里为何对象总是为true ? 在 ECMAScript 1中,曾经规定不支持通过对象配置来转换(比如 toBoolean() 方法)。原理是布尔运算符 || 和 && 会保持运算数的值。因此,如果链式使用这些运算符,会多次确认相同值的真假。这样的检查对于原始值类型成本不大,但是对于对象,如果能通过配置来转换布尔值,成本很大。所以从 ECMAScript 1 开始,对象总是为 true 来避免了这些成本转换。
三. Number
JavaScript 中所有的数字都只有一种类型,都被当做浮点数,JavaScript 内部会做优化,来区分浮点数组和整数。JavaScript 的数字是双精度的(64位),基于 IEEE 754 标准。
由于所有数字都是浮点数,所以这里就会有精度的问题。还记得前段时间网上流传的机器人的漫画么?

精度的问题就会引发一些奇妙的事情
| 0.1 + 0.2 ; // 0.300000000000004 | |
| ( 0.1 + 0.2 ) + 0.3; // 0.6000000000001 | |
| 0.1 + ( 0.2 + 0.3 ); // 0.6 | |
| (0.8+0.7+0.6+0.5) / 4 // 0.65 | |
| (0.6+0.7+0.8+0.5) / 4 // 0.6499999999999999 |
变换一个位置,加一个括号,都会影响精度。为了避免这个问题,建议还是转换成整数。
| ( 8 + 7 + 6 + 5) / 4 / 10 ; // 0.65 | |
| ( 6 + 8 + 5 + 7) / 4 / 10 ; // 0.65 |
值 | 转换成Number值 |
undefined | NaN |
null | 0 |
BOOL | false = 0,true = 1 |
数字 | 与原值相同 |
字符串 | 解析字符串中的数字(忽略开头和结尾的空格);空字符转换成0。 |
对象 | 调用 ToPrimitive( value,number) 并转换成原始类型 |
在数字里面有4个特殊的数值:
- 2个错误值:NaN 和 Infinity
- 2个0,一个+0,一个-0。0是会带正号和负号。因为正负号和数值是分开存储的。
| typeof NaN | |
| <"number" |
(吐槽:NaN 是 “ not a number ”的缩写,但是它却是一个数字)
NaN 是 JS 中唯一一个不能自身严格相等的值:
| NaN === NaN | |
| <false |
所以不能通过 Array.prototype.indexOf 方法去查找 NaN (因为数组的 indexOf 方法会进行严格等的判断)。
| [ NaN ].indexOf( NaN ) | |
| <-1 |
正确的姿势有两种:
第一种:
| function realIsNaN( value ){ | |
| return typeof value === 'number' && isNaN(value); | |
| } |
上面这种之所以需要判断类型,是因为字符串转换会先转换成数字,转换失败为 NaN。所以和 NaN 相等。
| isNaN( 'halfrost' ) | |
| <true |
第二种方法是利用 IEEE 754 标准里面的定义,NaN 和任意值比较,包括和自身进行比较,都是无序的
| function realIsNaN( value ){ | |
| return value !== value ; | |
| } |
另外一个错误值 Infinity 是由表示无穷大,或者除以0导致的。
判断它直接用 宽松相等 == ,或者严格相等 === 判断即可。
但是 isFinite() 函数不是专门用来判断Infinity的,是用来判断一个值是否是错误值(这里表示既不是 NaN,又不是 Infinity,排除掉这两个错误值)。
在 ES6 中 引入了两个函数专门判断 Infinity 和 NaN的,Number.isFinite() 和 Number.isNaN() 以后都建议用这两个函数进行判断。
JS 中整型是有一个安全区间,在( -2^53 , 2^53)之间。所以如果数字超过了64位无符号的整型数字,就只能用字符串进行存储了。
利用 parseInt() 进行转换成数字的时候,会有出错的时候,结果不可信:
| parseInt(1000000000000000000000000000.99999999999999999,10) | |
| <1 |
parseInt( str , redix? ) 会先把第一个参数转换成字符串:
| String(1000000000000000000000000000.99999999999999999) | |
| <"1e+27" |
parseInt 不认为 e 是整数,所以在 e 之后的就停止解析了,所以最终输出1。
JS 中的 % 求余操作符并不是我们平时认为的取模。
| -9%7 | |
| <-2 |
求余操作符会返回一个和第一个操作数相同符号的结果。取模运算是和第二个操作数符号相同。
所以比较坑的就是我们平时判断一个数是否是奇偶数的问题就会出现错误:
| function isOdd( value ){ | |
| return value % 2 === 1; | |
| } | |
| console.log(-3); // false | |
| console.log(-2); // false |
正确姿势是:
| function isOdd( value ){ | |
| return Math.abs( value % 2 ) === 1; | |
| } | |
| console.log(-3); // true | |
| console.log(-2); // false |
四. String
字符串比较符,是无法比较变音符和重音符的。
| 'ä' < 'b' | |
| <false | |
| 'á' < 'b' | |
| <false |
五. Array
创建数组的时候不能用单个数字创建数组。
| new Array(2) // 这里的一个数字代表的是数组的长度 | |
| <[ , , ] | |
| new Array(2,3,4) | |
| <[2,3,4] |
删除元素会删出空格,但是不会改变数组的长度。
| var array = [1,2,3,4] | |
| array.length | |
| <4 | |
| delete array[1] | |
| array | |
| <[1, ,3,4] | |
| array.length | |
| <4 |
所以这里的删除不是很符合我们之前的删除,正确姿势是用splice
| var array = [1,2,3,4,56,7,8,9] | |
| array.splice(1,3) | |
| array | |
| <[1, 56, 7, 8, 9] | |
| array.length | |
| <5 |
针对数组里面的空缺,不同的遍历方法行为不同
在 ES5 中:
方法 | 针对空缺 |
forEach() | 遍历时跳过空缺 |
every() | 遍历时跳过空缺 |
some() | 遍历时跳过空缺 |
map() | 遍历时跳过空缺,但是最终结果会保留空缺 |
filter() | 去除空缺 |
join() | 把空缺,undefined,null转化为空字符串 |
toString() | 把空缺,undefined,null转化为空字符串 |
sort() | 排序时保留空缺 |
apply() | 把每个空缺转化为undefined |
在 ES6 中:规定,遍历时不跳过空缺,空缺都转化为undefined
方法 | 针对空缺 |
Array.from() | 空缺都转化为undefined |
...(扩展运算符有) | 空缺都转化为undefined |
copyWithin() | 连空缺一起复制 |
fill() | 遍历时不跳过空缺,视空缺为正常的元素 |
for...of | 遍历时不跳过空缺 |
entries() | 空缺都转化为undefined |
keys() | 空缺都转化为undefined |
values() | 空缺都转化为undefined |
find() | 空缺都转化为undefined |
findIndex() | 空缺都转化为undefined p0p0 |
六. Set 、Map、WeakSet、WeakMap
数据结构 | 特点 |
Set | 类似于数组,但是成员值唯一,注意(这里是一个例外),这里 NaN 等于自身 |
WeakSet | 成员只能是对象,而不能是其他类型的值。对象的引用都是弱引用,所以不能引用 WeakSet 的成员,不可遍历它(因为遍历的过程中随时都可以消失) |
Map | 类似于对象,键值对的集合,键的范围不限于字符串,各种类型都可以,是“值—值”的映射,这一点区别于对象的“字符串—值”的映射 |
WeakMap | 于 Map 类似,区别在于它只接受对象作为键名( null 除外),键名指向的对象也不计入垃圾回收机制中,它也无法遍历,也无法清空clear |
七. 循环
先说一个 for-in 的坑:
| var scores = [ 11,22,33,44,55,66,77 ]; | |
| var total = 0; | |
| for (var score in scores) { | |
| total += score; | |
| } | |
| var mean = total / scores.length; | |
| mean; |
一般人看到这道题肯定就开始算了,累加,然后除以7 。那么这题就错了,如果把数组里面的元素变的更加复杂:
var scores = [ 1242351,252352,32143,452354,51455,66125,74217 ];
其实这里答案和数组里面元素是多少无关。只要数组元素个数是7,最终答案都是17636.571428571428。
原因是 for-in 循环的是数组下标,所以 total = ‘00123456’ ,然后这个字符串再除以7。
循环方式 | 遍历对象 | 副作用 |
for | 写法比较麻烦 | |
for-in | 索引值(键名),而非数组元素 | 遍历所有(非索引)属性,以及继承过来的属性(可以用hasOwnProperty()方法排除继承属性),主要是为遍历对象而设计的,不适用于遍历数组 |
forEach | 不方便break,continue,return | |
for...of | 内部通过调用 Symbol.iterator 方法,实现遍历获得键值 | 不可遍历普通的对象,因为没有 Iterator 接口 |
遍历对象的属性,ES6 中有6种方法:
循环方式 | 遍历对象 |
for...in | 循环遍历对象自身的和继承的可枚举属性(不包含Symbol属性)) |
Object.key(obj) | 返回一个数组,包括对象自身的(不含继承的)所有可枚举属性(不含Symbol属性) |
Object.getOwnPropertyNames(obj) | 返回一个数组,包含对象自身的所有属性(不含 Symbol 属性,但是包含不可枚举的属性) |
Object.getOwnPropertySymbols(obj) | 返回一个数组,包含对象自身的所有 Symbol 属性 |
Reflect.ownKeys(obj) | 返回一个数组,包含对象自身的所有属性,不管属性名是 Symbol 或者字符串或者是否可枚举 |
Reflect.enumerate(obj) | 返回一个 Iterator对象,遍历对象自身的和继承的所有可枚举属性(不包含 Symbol 属性),与 for...in循环相同 |
八. 隐式转换 / 强制转换 带来的bug
| var formData = { width : '100'}; | |
| var w = formData.width; | |
| var outer = w + 20; | |
| console.log( outer === 120 ); // false; | |
| console.log( outer === '10020'); // true |
九. 运算符重载
在 JavaScript 无法重载或者自定义运算符,包括等号。
十. 函数声明和变量声明的提升
先举一个函数提升的例子。
| function foo() { | |
| bar(); | |
| function bar() { | |
| …… | |
| } | |
| } |
var 变量也具有提升的特性。但是把函数赋值给变量以后,提升的效果就会消失。
| function foo() { | |
| bar(); // error! | |
| var bar = function () { | |
| …… | |
| } | |
| } |
上述函数就没有提升效果了。
函数声明是做了完全提升,变量声明只是做了部分提升。变量的声明才有提升的作用,赋值的过程并不会提升。
JavaScript 支持词法作用域( lexical scoping ),即除了极少的例外,对变量 foo 的引用会被绑定到声明 foo 变量最近的作用域中。ES5中 不支持块级作用域,即变量定义的作用域并不是离其最近的封闭语句或代码块,而包含它们的函数。所有的变量声明都会被提升,声明会被移动到函数的开始处,而赋值则仍然会在原来的位置进行。
| function foo() { | |
| var x = -10; | |
| if ( x < 0) { | |
| var tmp = -x; | |
| …… | |
| } | |
| console.log(tmp); // 10 | |
| } |
这里 tmp 就有变量提升的效果。
再举个例子:
| foo = 2; | |
| var foo; | |
| console.log( foo ); |
上面这个例子还是输出2,不是输出undefined。
这个经过编译器编译以后,其实会变成下面这个样子:
| var foo; | |
| foo = 2; | |
| console.log( foo ); |
变量声明被提前了,赋值还在原地。 为了加深一下这句话的理解,再举一个例子:
| console.log( a ); | |
| var a = 2; |
上述代码会被编译成下面的样子:
| var foo; | |
| console.log( foo ); | |
| foo = 2; |
所以输出的是undefined。
如果变量和函数都存在提升的情况,那么函数提升优先级更高。
| foo(); // 1 | |
| var foo; | |
| function foo() { | |
| console.log( 1 ); | |
| } | |
| foo = function() { | |
| console.log( 2 ); | |
| }; |
上面经过编译过会变成下面这样子:
| function foo() { | |
| console.log( 1 ); | |
| } | |
| foo(); // 1 | |
| foo = function() { | |
| console.log( 2 ); | |
| }; |
最终结果输出是1,不是2 。这就说明了函数提升是优先于变量提升的。
为了避免变量提升,ES6中引入了 let 和 const 关键字,使用这两个关键字就不会有变量提升了。原理是,在代码块内,使用 let 命令声明变量之前,该变量都是不可用的,这块区域叫“暂时性死区”(temporal dead zone,TDZ)。TDZ 的做法是,只要一进入到这一区域,所要使用的变量就已经存在了,变量还是“提升”了,但是不能获取,只有等到声明变量的那一行出现,才可以获取和使用该变量。
ES6 的这种做法也给 JS 带来了块级作用域,(在 ES5 中只有全局作用于和函数作用域),于是立即执行匿名函数(IIFE)就不在必要了。
十一. arguments 不是数组
arguments 不是数组,它只是类似于数组。它有length属性,可以通过方括号去访问它的元素。不能移除它的元素,也不能对它调用数组的方法。
不要在函数体内使用 arguments 变量,使用 rest 运算符( ... )代替。因为 rest 运算符显式表明了你想要获取的参数,而且 arguments 仅仅只是一个类似的数组,而 rest 运算符提供的是一个真正的数组。
下面有一个把 arguments 当数组用的例子:
| function callMethod(obj,method) { | |
| var shift = [].shift; | |
| shift.call(arguments); | |
| shift.call(arguments); | |
| return obj[method].apply(obj,arguments); | |
| } | |
| var obj = { | |
| add:function(x,y) { return x + y ;} | |
| }; | |
| callMethod(obj,"add",18,38); |
上述代码直接报错:
| Uncaught TypeError: Cannot read property 'apply' of undefined | |
| at callMethod (<anonymous>:5:21) | |
| at <anonymous>:12:1 |
出错的原因就在于 arguments 并不是函数参数的副本,所有命名参数都是 arguments 对象中对应索引的别名。因此通过 shift 方法移除 arguments 对象中的元素之后,obj 仍然是 arguments[0] 的别名,method 仍然是 arguments[1] 的别名。看上去是在调用 obj[add],实际上是在调用17[25]。
还有一个问题,使用 arguments 引用的时候。
| function values() { | |
| var i = 0 , n = arguments.length; | |
| return { | |
| hasNext: function() { | |
| return i < n; | |
| }, | |
| next: function() { | |
| if (i >= n) { | |
| throw new Error("end of iteration"); | |
| } | |
| return arguments[i++]; | |
| } | |
| } | |
| } | |
| var it = values(1,24,53,253,26,326,); | |
| it.next(); // undefined | |
| it.next(); // undefined | |
| it.next(); // undefined |
上述代码是想构造一个迭代器来遍历 arguments 对象的元素。这里之所以会输出 undefined,是因为有一个新的 arguments 变量被隐式的绑定到了每个函数体内,每个迭代器 next 方法含有自己的 arguments 变量,所以执行 it.next 的参数时,已经不是 values 函数中的参数了。
更改方式也简单,只要声明一个局部变量,next 的时候能引用到这个变量即可。
| function values() { | |
| var i = 0 , n = arguments.length,a = arguments; | |
| return { | |
| hasNext: function() { | |
| return i < n; | |
| }, | |
| next: function() { | |
| if (i >= n) { | |
| throw new Error("end of iteration"); | |
| } | |
| return a[i++]; | |
| } | |
| } | |
| } | |
| var it = values(1,24,53,253,26,326,); | |
| it.next(); // 1 | |
| it.next(); // 24 | |
| it.next(); // 53 |
十二. IIFE 引入新的作用域
在 ES5 中 IIFE 是为了解决 JS 缺少块级作用域,但是到了 ES6 中,这个就可以不需要了。
十三. 函数中 this 的问题
在嵌套函数中不能访问方法中的 this 变量。
| var halfrost = { | |
| name:'halfrost', | |
| friends: [ 'haha' , 'hehe' ], | |
| sayHiToFriends: function() { | |
| 'use strict'; | |
| this.friends.forEach(function (friend) { | |
| // 'this' is undefined here | |
| console.log(this.name + 'say hi to' + friend); | |
| }); | |
| } | |
| } | |
| halfrost.sayHiToFriends() |
这时就会出现一个TypeError: Cannot read property 'name' of undefined。
解决这个问题有两种方法:
第一种:将 this 保存在变量中。
| sayHiToFriends: function() { | |
| 'use strict'; | |
| var that = this; | |
| this.friends.forEach(function (friend) { | |
| console.log(that.name + 'say hi to' + friend); | |
| }); | |
| } |
第二种:利用bind()函数
使用bind()给回调函数的this绑定固定值,即函数的this
| sayHiToFriends: function() { | |
| 'use strict'; | |
| this.friends.forEach(function (friend) { | |
| console.log(this.name + 'say hi to' + friend); | |
| }.bind(this)); | |
| } |
第三种:利用 forEach 的第二个参数,把 this 指定一个值。
| sayHiToFriends: function() { | |
| 'use strict'; | |
| this.friends.forEach(function (friend) { | |
| console.log(this.name + 'say hi to' + friend); | |
| }, this); | |
| } |
到了 ES6 里面,建议能用箭头函数的地方用箭头函数。
简单的,单行的,不会复用的函数,都建议用箭头函数,如果函数体很复杂,行数很多,还应该用传统写法。
箭头函数里面的 this 对象就是定义时候的对象,而不是使用时候的对象,这里存在“绑定关系”。
这里的“绑定”机制并不是箭头函数带来的,而是因为箭头函数根本就没有自己的 this,导致内部的 this 就是外层代码块的 this,正因为这个特性,也导致了以下的情况都不能使用箭头函数:
- 不能当做构造函数,不能使用 new 命令,因为没有 this,否则会抛出一个错误。
- 不可以使用 argument 对象,该对象在函数体内不存在,非要使用就只能用 rest 参数代替。也不能使用 super,new.target 。
- 不可以使用 yield 命令,不能作为 Generator 函数。
- 不可以使用call(),apply(),bind()这些方法改变 this 的指向。
十四. 异步
异步编程有以下几种:
- 回调函数callback
- 事件监听
- 发布 / 订阅
- Promise对象
- Async / Await
(这个日记可能一直未完待续......)