前言
这篇文章我们接着上一篇的内容,继续学习Linux中一些常见的基本指令。
1. cp 指令(重要)
在Windows中我们经常可能会复制一个文件,然后粘贴到另一个地方。那在Linux也可以对文件或者目录进行复制,对应的命令就是cp,那怎么用呢?
演示一下:
当前目录下有一个目录dd,里面是空的,还有一个文件add.c
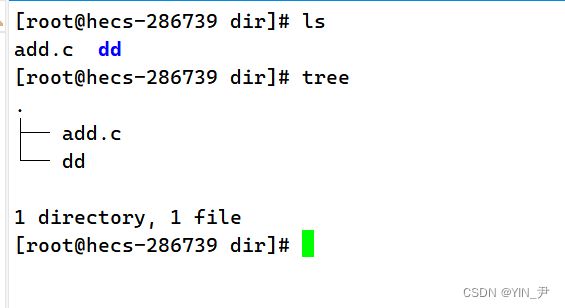
如果我现在想把文件add.c拷贝到dd目录里,怎么做呢? 很简单:cp add.c dd
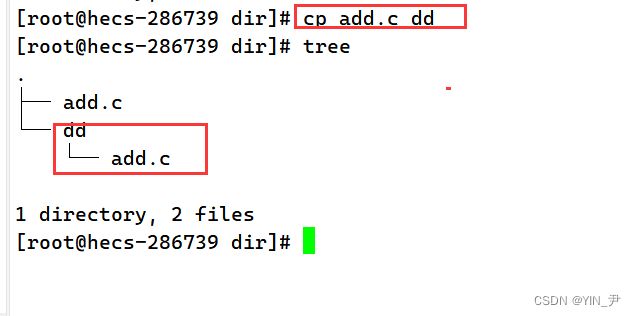
然后我想把目录dd拷贝到上一级目录:
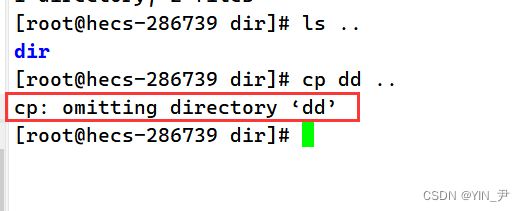
我发现不行,报错了,这是因为默认只能拷贝普通文件,那拷贝目录怎么做呢? 还是加个 -r(递归拷贝,因为目录其实就是递归定义的)
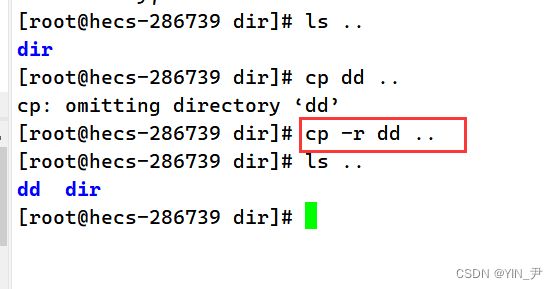
这下就拷贝成功了。
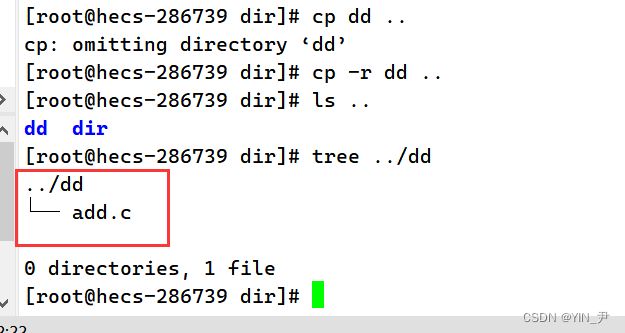
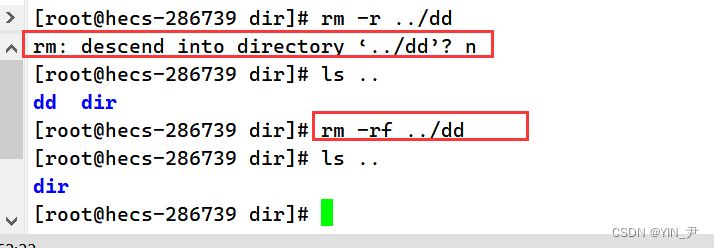
并且它里面的add.c也复制过去了。 另外,同样的,如果在拷贝某些文件的时候收到提示,让你输入y或n,如果你就是要拷且不想被提示加个-f(force 强制)
总结一下:
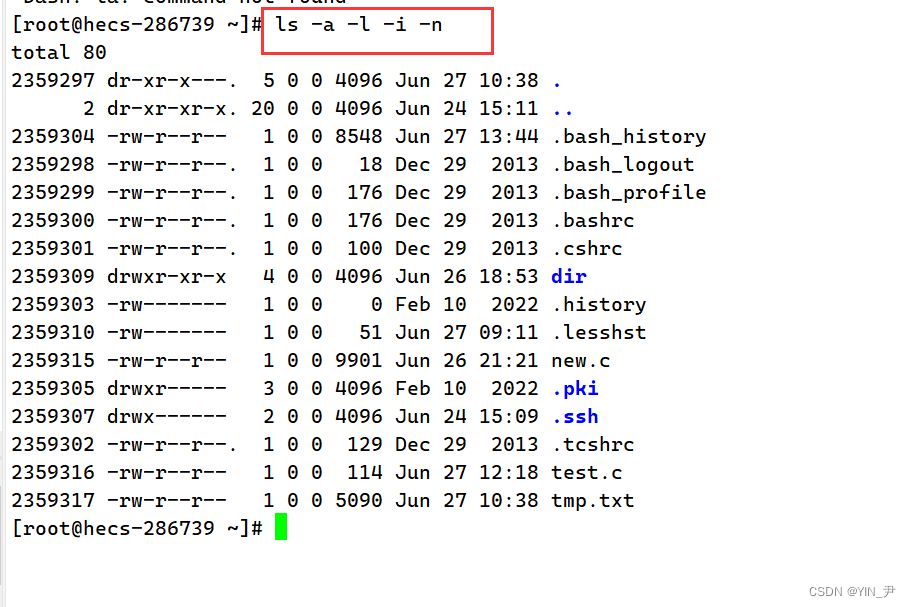
语法:cp [选项] 源文件或目录 目标文件或目录 功能: 复制文件或目录 说明: cp指令用于复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到此目录中。若同时指定多个文件或目录,而最后的目的地并非一个已存在的目录,则会出现错误信息 常用选项: -f 或 --force 强行复制文件或目录, 不论目的文件或目录是否已经存在 -i 或 --interactive 覆盖文件之前先询问用户 -r递归处理,将指定目录下的文件与子目录一并处理。若源文件或目录的形态,不属于目录或符号链接,则一律视为普通文件处理 -R 或 --recursive递归处理,将指定目录下的文件及子目录一并处理
2. mv 指令(重要)
那在Windows上呢,我们还会进行一种操作叫做剪切,相信大家也都用过,那在Linux上能否实现类似的操作呢?
当然是可以的,用到的命令是——mv(可以理解为move,移动)。那在讲之前呢先给大家再补充一点东西:
我们在上一篇文章中有提到一个叫做家目录的概念,那我们登录上自己的机器的时候,其实默认就是处在自己的家目录下的。 对于root用户来说,家目录就是/root,普通用户的家目录是在/home/用户名下,home下面是可以有多个普通用户的,那对于一个普通用户而言,一般来说,它可以在自己的家目录下畅通无阻,当然这并不是说就一定不可以在其它用户家目录下做操作了,只是如果你在其它用户目录下面做操作的时候,可以能受到一些限制和约束。 所以这里想告诉大家的是,我们平时如果登录普通用户去做一些练习比如拷贝,剪切这下操作时,在自己的家目录下进行就行。
那我们下面就来练习一下mv命令,先来mv 文件试一下:
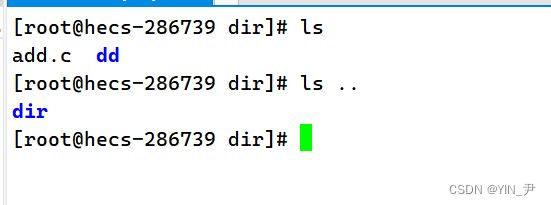
现在当前目录下有一个文件add.c,现在我把它剪切到上级目录去:
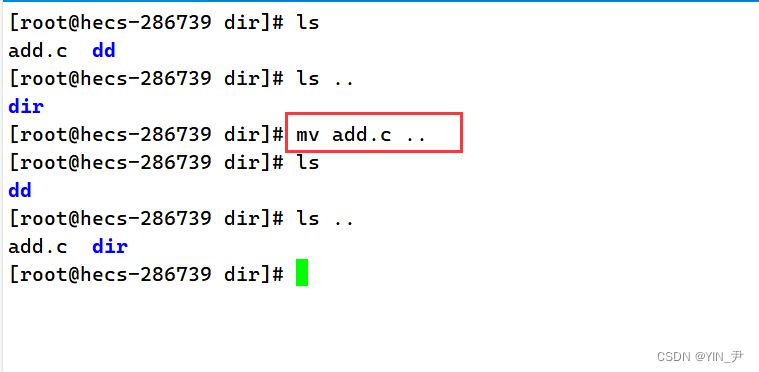
🆗,这样就可以了,我们看到此时上级目录就有add.c了,当当前目录就没有了,剪切成功。
那我想mv目录呢?
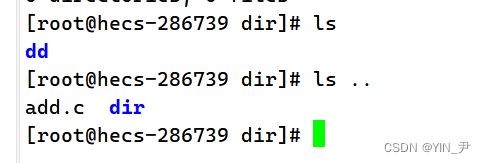
我想把dd移动到上级目录
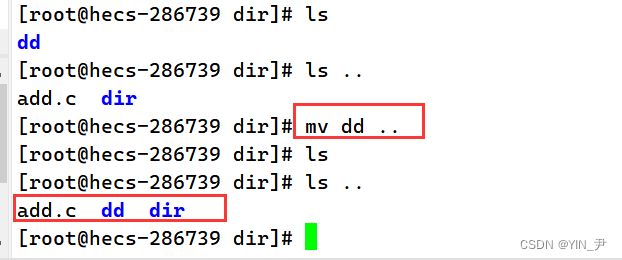
就可以了
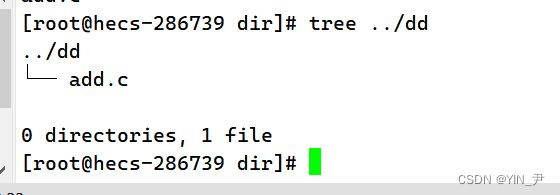
并且目录里面的内容也会直接移动过去,它默认就是递归去移动目录里面的所有内容。
那mv指令呢,除了可以移动(剪切)文件之外,其实还有另外一个功能:
在Windows上我们还可能经常做一个操作,就是给文件重命名
那在Linux上,mv指令其实也可以实现对文件重命名的这样一个功能
演示一下:
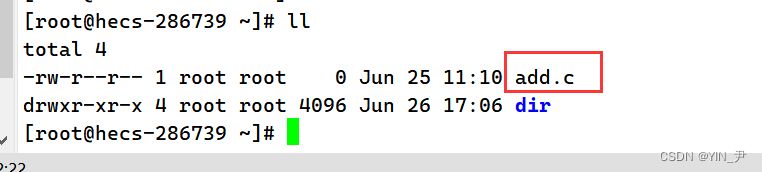
当前目录下有一个名为add.c的文件,现在我们来对它改一下名
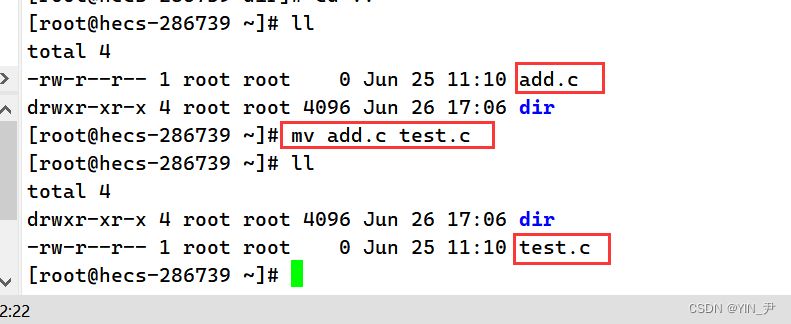
就可以了。 那如果如果我这样呢:
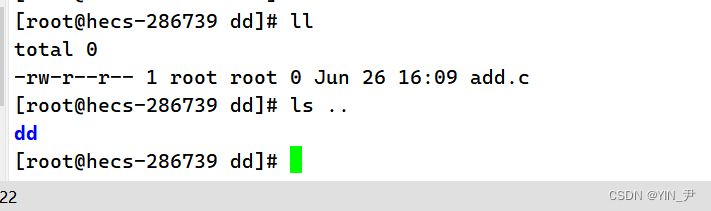
当前目录下只有一个add.c文件,上级目录有一个名为dd的目录,那现在我写这样一句指令:
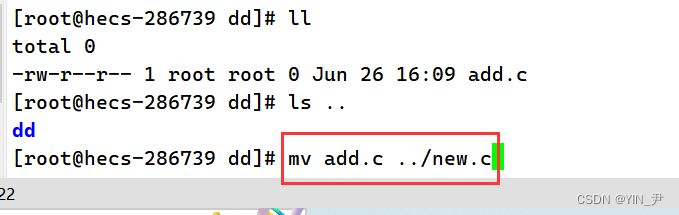
大家看这句指令是什么意思? 我们来看一下结果先
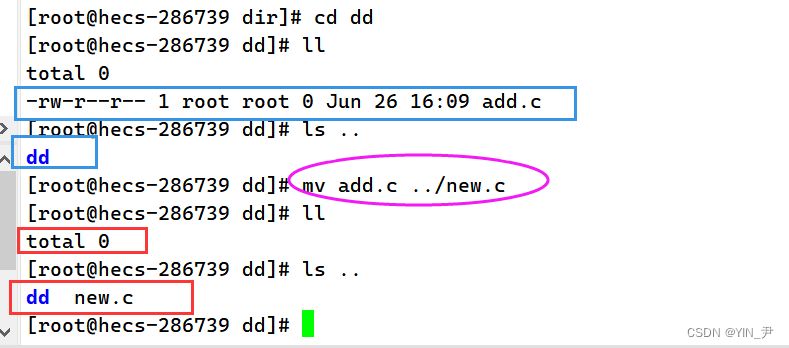
我们看到当前目录没有add.c这个文件了,而上级目录多了一个文件且名字为new.c 所以mv add.c ../new.c这句命令其实就是把add.c移动到上级目录,并且把它重命名为new.c 对目录重命名也是一样的!
总结一下:
mv命令是move的缩写,可以用来移动文件或者将文件改名(move (rename) files),是Linux系统下常用的命令,经常用来备份文件或者目录。
语法: mv [选项] 源文件或目录 目标文件或目录
功能:
- 视mv命令中第二个参数类型的不同(是目标文件还是目标目录),mv命令将文件重命名或将其移至一个新的 目录中。
- 当第二个参数类型是文件时,mv命令完成文件重命名,此时,源文件只能有一个(也可以是源目录名),它将所给的源文件或目录重命名为给定的目标文件名。
- 当第二个参数是已存在的目录名称时,源文件或目录参数可以有多个,mv命令将各参数指定的源文件均移至目标目录中。 常用选项: -f :force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖 -i :若目标文件 (destination) 已经存在时,就会询问是否覆盖!
3. cat 指令
再来学一个命令叫做cat,它的作用其实就是用来查看文件的内容:
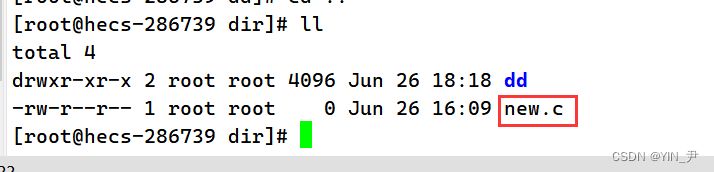
当前目录下有一个文件new.c,我们来给他里面写入一些内容。 使用我们上一篇文章提到的nano:
保存退出
不是说cat可以查看文件内容嘛,那我们来试一下
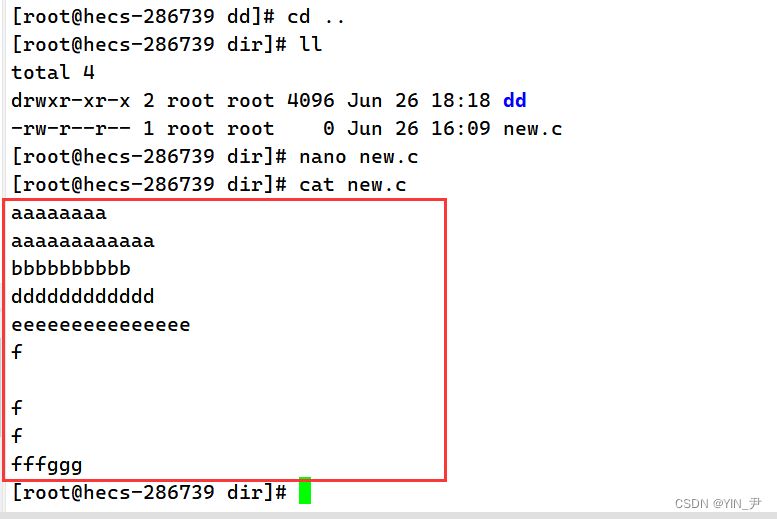
🆗,这里就把new.c文件的内容打印显示出来了
echo 命令
然后在这里再给大家补充一点东西:
Linux里面还有一个命令echo,它可以帮我们输出或者说打印信息,比如:
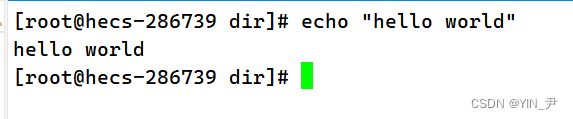
不加双引号也可以,但建议加上。 那这里呢我们看到用echo打印信息的时候默认是通过显示器就直接打印出来了。
输出重定向
那其实还可以这样玩:
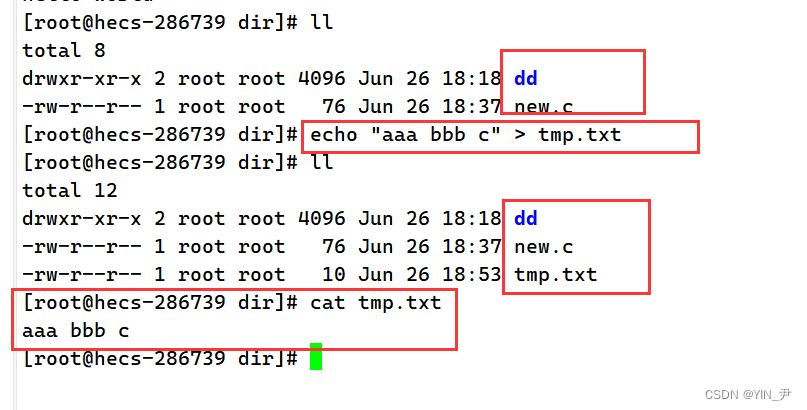
我们看到这次echo并没有直接把后面的字符串之间显示出来,而且当前目录下新创建了一个文件tmp.txt,然后echo后面的字符串被写入了tmp.txt文件中。 为什么会这样呢? echo "aaa bbb c" > tmp.txt中的>这个符号可以实现输出重定向。 什么意思呢? 其实就可以理解为重新确定了输出的方向。那上面的这个过程其实就是一个输出重定向,把本应该输出到显示器的信息写入到了tmp.txt文件中,那这个文件原来是并不存在的,而系统其实会去自动创建对应的文件。
那还想告诉大家什么呢:
上面我们提到echo可以直接通过显示器打印信息,那通过显示器打印信息其实我们可以理解为把信息写入到显示器,所以,其实我们也可以把显示器看成一种“文件”。 另外呢,我们学习什么C语言用的scanf或者C++的cin去获取数据,这些数据来源是啥,是不是来自于我们从键盘输进去去的数据啊,所以其实键盘我们也可以看作一种“文件”。 那从这里呢,我们既可以引出一个结论,这个结论大家可能也听说过,就是——Linux下一切皆文件。
那再回到输出重定向的问题:
我们刚才演示的是重定向到一个不存在的文件,那我们看到结果是自动创建了目标文件,并且把原本要输出到显示器的内容写入到了目标文件夹中。 那如果重定向到一个已经存在并且有内容的文件呢?
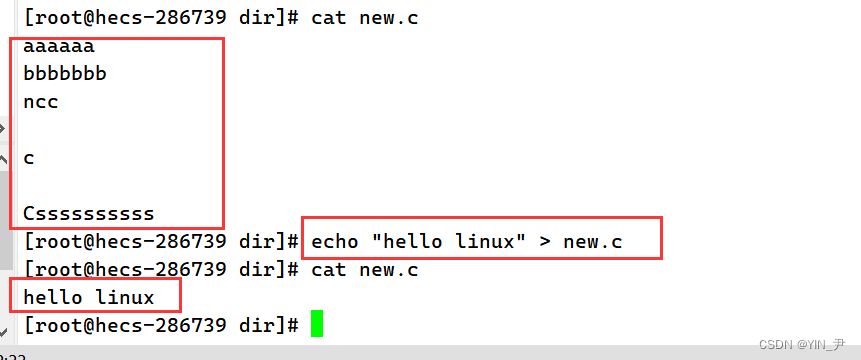
通过结果我们其实可以得出>的重定向是一种覆盖式的,会把文件原来的内容覆盖掉,不过其实它是在写入之前把原来的内容清空,然后在把echo后面的内容写入文件中。 清空文件:>文件名
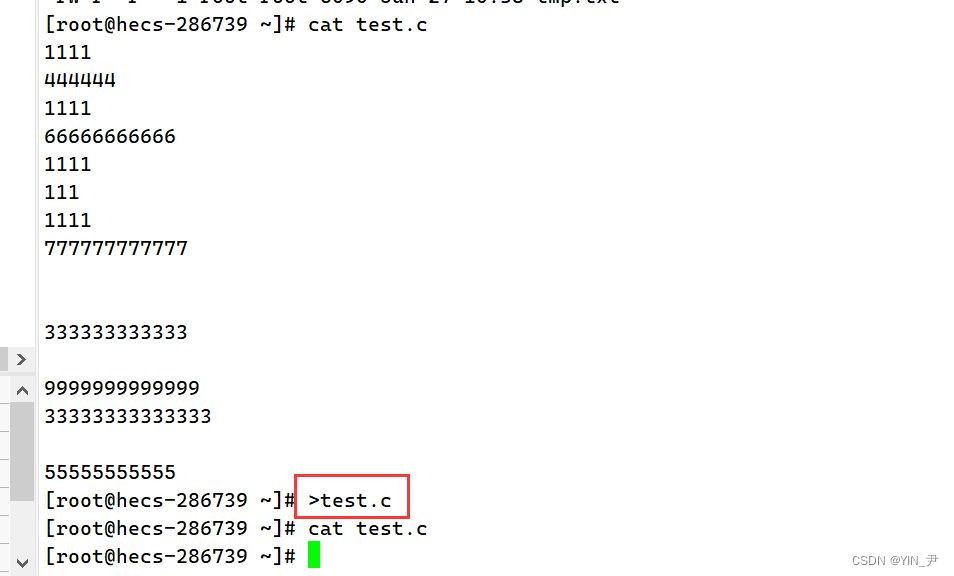
追加重定向
再来看另外一种玩法:
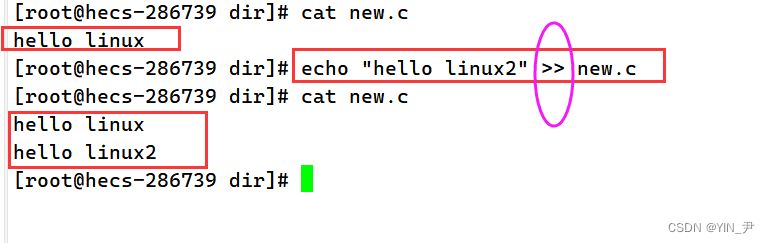
这次我们用两个>,echo "hello linux2" >> new.c然后我们发现这次并没有覆盖,而是把内容追加到原来内容的后面了 再试几次:
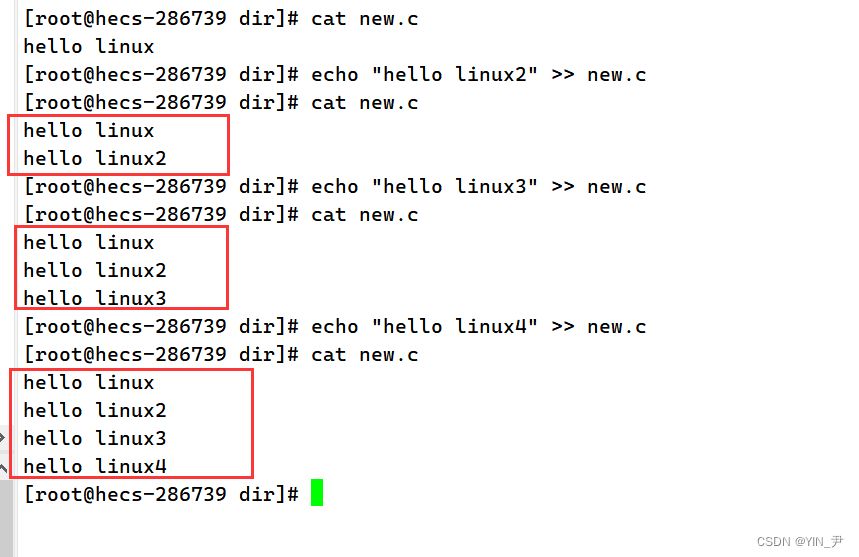
🆗,确实是这样。 所以呢,>>可以实现追加重定向,把指定内容追加到目标文件中。
wc 命令
再来了解一个命令——wc
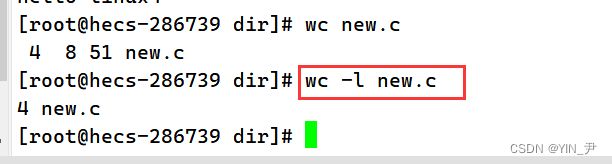
wc可以统计文件的行数、单词数和字节数这些信息:
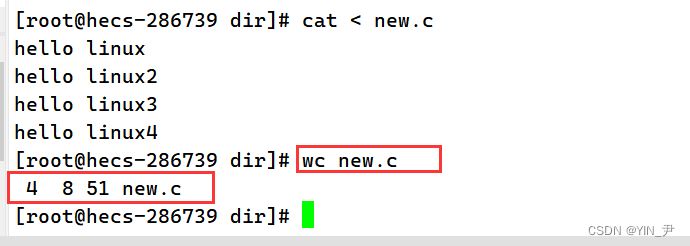
加选项-l可以只显示行数
输入重定向
上面我们学了cat命令,一般我们后面会跟一个文件,就可以显示文件的内容,那如果cat之后不跟文件名呢:

🆗,如果我们只输入一个cat,这时我们输入什么,按回车后,显示器就回显什么,一直输入,就一直回显,按crtl+c可以结束。 也就是说,cat如果后面不跟文件的话,它默认是从键盘去读取数据的,我们敲什么,它就读取什么然后并显示出来。 那如果我们不想让它从键盘读呢,那就可以这样:
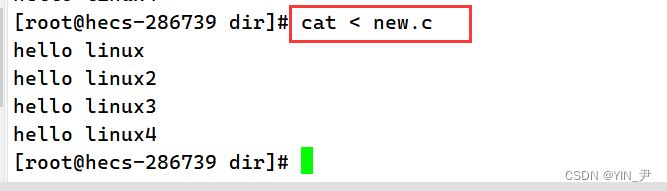
cat 后面加一个<,然后跟文件名,这时他就去读取目标文件的内容并显示出来。那这里的<我们把它叫做输入重定向。 欸,那大家可能疑问了,那跟着样写cat new.c不是一样吗?
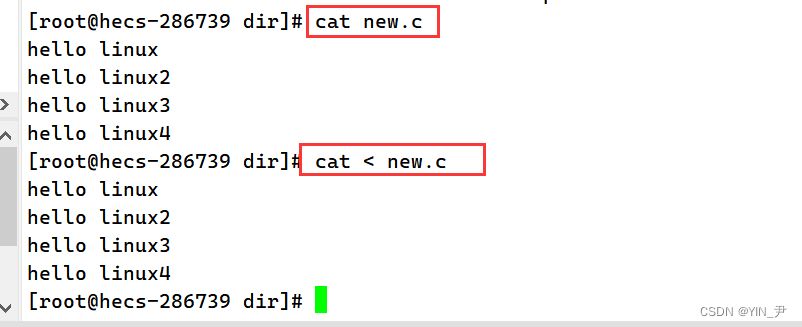
🆗,其实它们是有区别的,这个我们后面再说。
那现在我们在来回到我们的cat:
它也有一些常用的选项 首先第一个可以加 -n: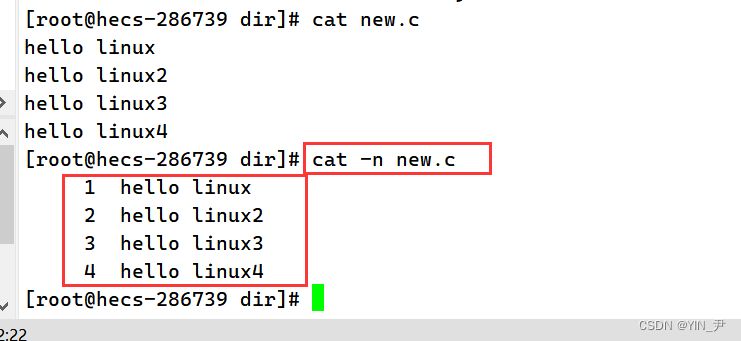
它可以在显示信息的同时显示文本的行号。然后 -s ,作用是不输出多行空行 啥意思呢?
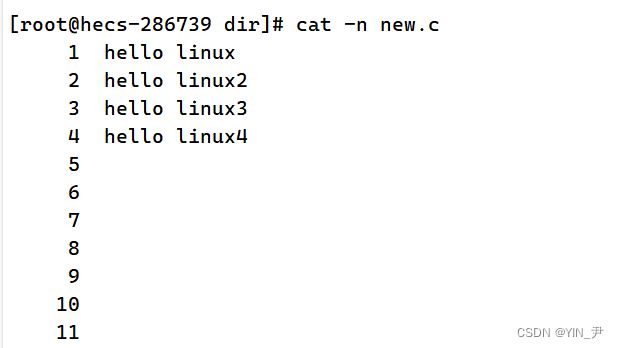
我现在给new.c中添加一些空行。 然后我再加-s,来看结果:
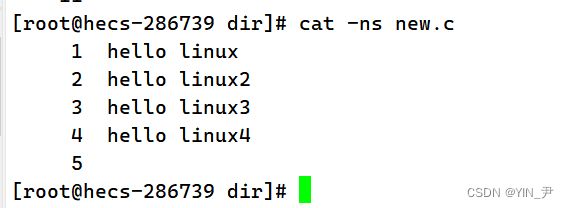
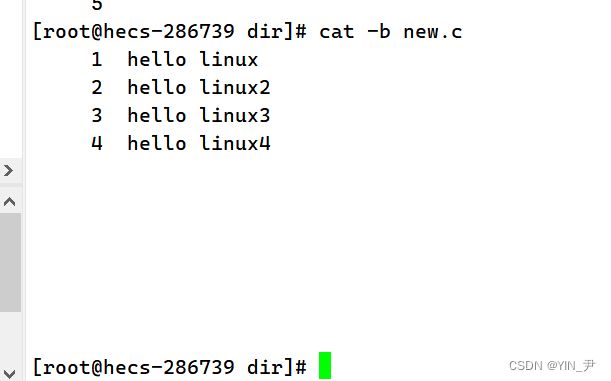
🆗,原来有多个空行,现在只显示一行。就是这个作用。 -b 对非空输出行编号
总结一下cat:
语法:cat [选项][文件] 功能: 查看目标文件的内容 常用选项: -b 对非空输出行编号 -n 对输出的所有行编号 -s 不输出多行空行
4. more 指令
在讲more命令之前我先创建一个大文本:
cnt=0; while [ cnt -le 1000 ]; do echo "hello
那有没有其它方法呢?
有的,这种情况我们就可以用一个命令叫做more,那more的功能呢类似cat。 但是呢more会默认按照我们屏幕的大小去显示文本信息: 我们输入more new.c,敲回车:
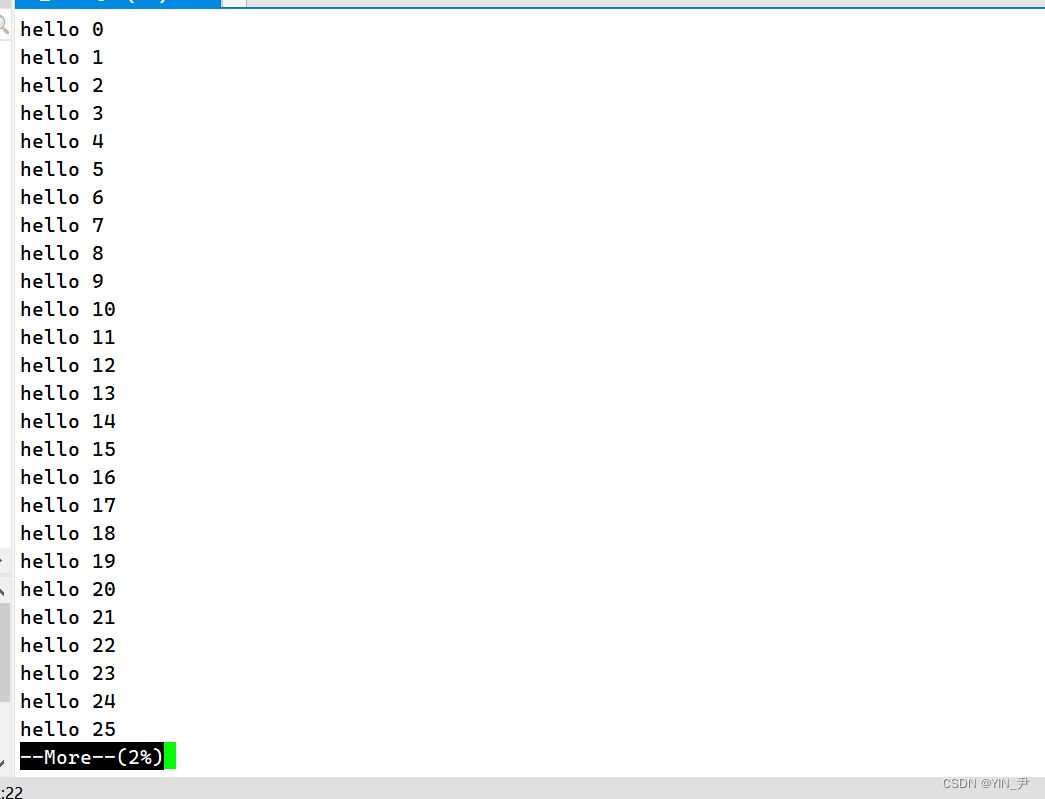
它就会从第一行开始显示,这一屏幕满了,就停止显示后面的信息了。 然后我们敲回车就可以一行一行往下查看:

要退出的话按q就可以退出。
more命令:
语法:more [选项][文件] 功能:more命令,功能类似 cat 常用选项: -n 对输出的所有行编号 q 退出more
5. less指令(重要)
与more类似,还有一个命令叫做less,它也可以对文件内容进行分页显示:

但是呢,比more好的是,它不仅可以下翻,还可以上翻,直接按上下键就可以了。 那除此之外,它还支持进行搜索,在浏览状态下直接按/,就可以跟相应的信息进行搜索
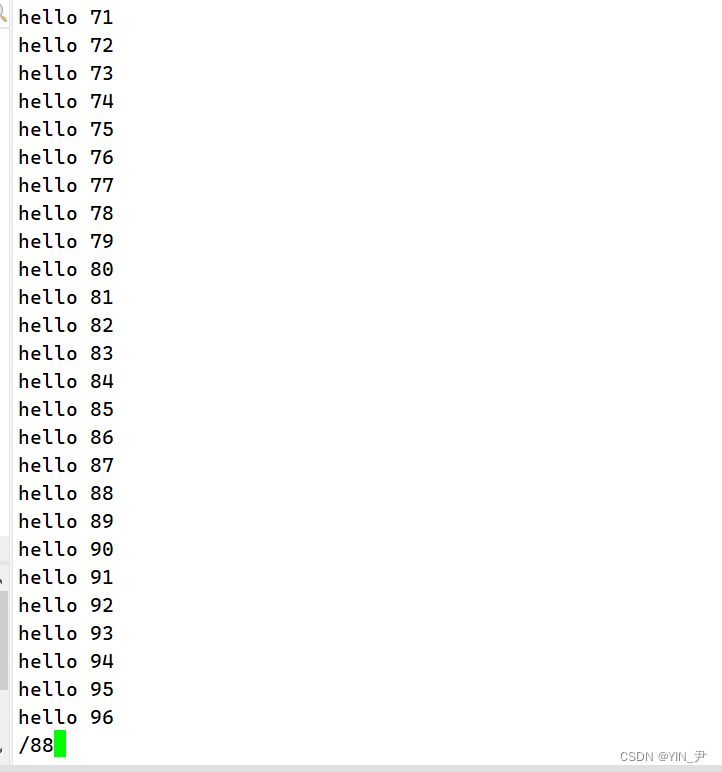
比如要搜索88,在/后输入88,然后回车

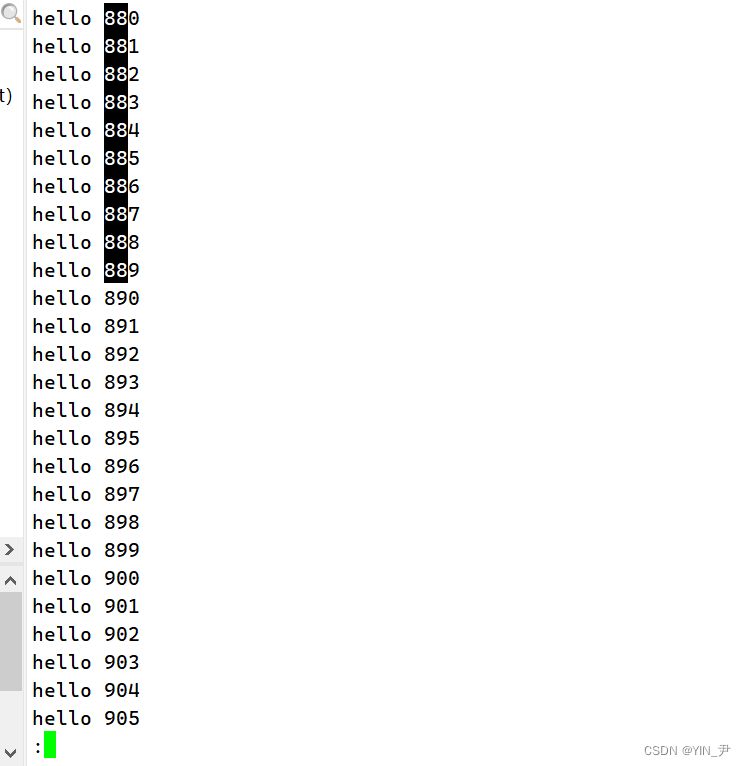
如果存在,就搜索出来了 另外,按n(next),还可以搜索下一个88
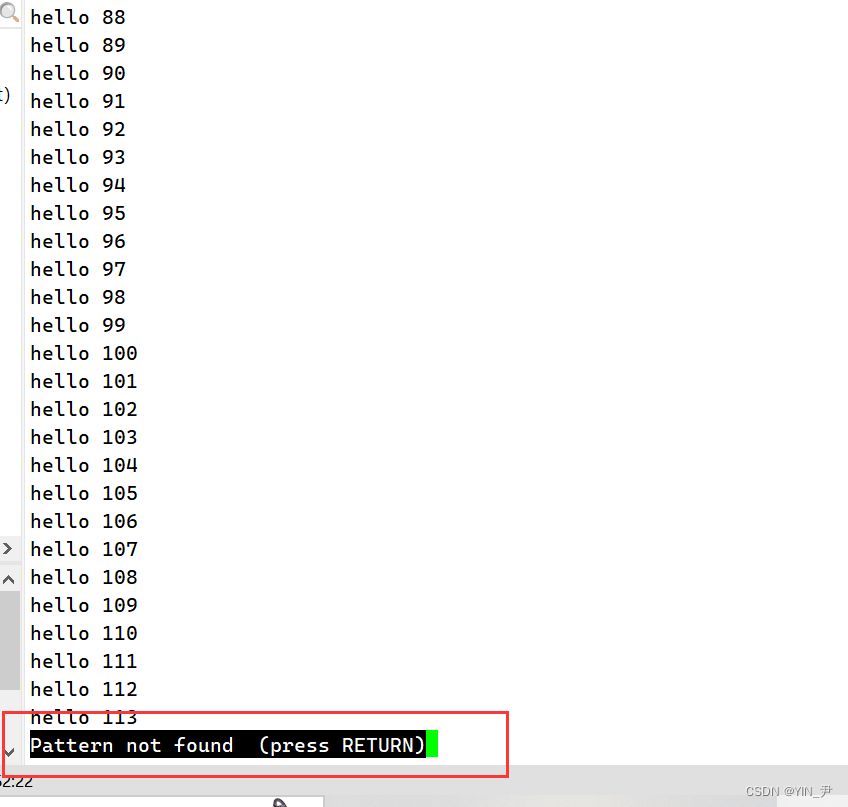
如果搜索的内容不存在的话会提示你:
总结一下:
less 工具也是对文件或其它输出进行分页显示的工具,应该说是linux正统查看文件内容的工具,功能极其强大。 less 的用法比起 more 更加的有弹性。在 more 的时候,我们并没有办法向前面翻, 只能往后面看。 但若使用了 less 时,就可以使用 [pageup][pagedown] 等按键的功能来往前往后翻看文件,更容易用来查看一个文件的内容! 除此之外,在 less 里头可以拥有更多的搜索功能,不止可以向下搜,也可以向上搜。
语法: less [参数] 文件 功能:
less与more类似,但使用less可以随意浏览文件,而more仅能向前移动,却不能向后移动,而且less在查看之前不会加载整个文件。
选项:
-i 忽略搜索时的大小写 -N 显示每行的行号 /字符串:向下搜索“字符串”的功能 ?字符串:向上搜索“字符串”的功能 n:重复前一个搜索(与 / 或 ? 有关) N:反向重复前一个搜索(与 / 或 ? 有关) q: quit
6. head指令
head指令的功能和它的名字一些浅显易懂。
如果head后面直接跟文件名:
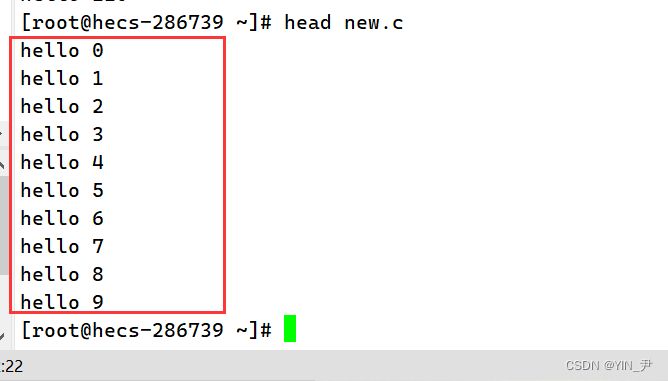
它默认会把对应文件的前10行显示出来。
当然我们也可以自己指定想要显示的行数
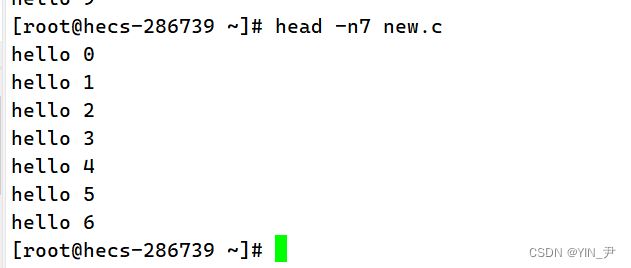
-n 后面加行数,当然这个n其实可以不加:
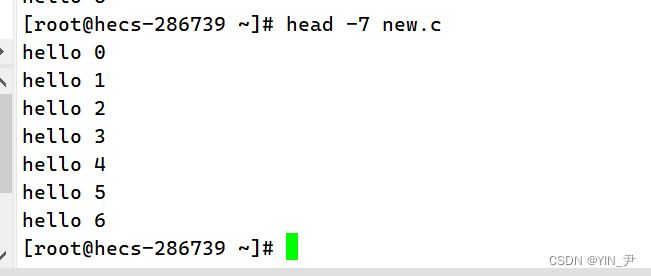
那head的功能就这么简单,总结一下:
head 与 tail 就像它的名字一样的浅显易懂,它是用来显示开头或结尾某个数量的文字区块,head 用来显示档案的开头至标准输出中,而 tail 想当然尔就是看档案的结尾。 语法: head [参数]… [文件]… 功能: head 用来显示档案的开头至标准输出中,默认head命令打印其相应文件的开头10行。 选项: -n<行数> 显示的行数(n可以不加)
7. tail指令
学了上面的head,tail就很好理解了
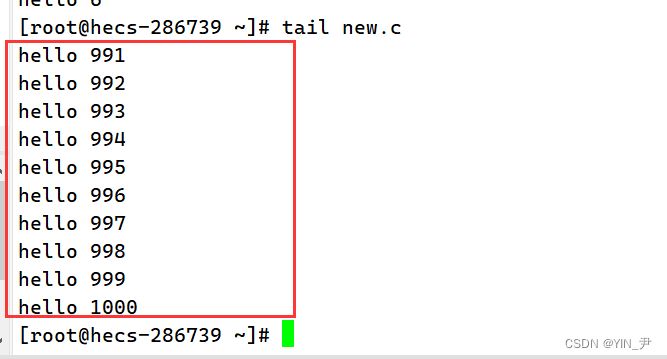
tail后面直接跟文件名,默认显示后10行 当然也可以自己指定行数,和head一样
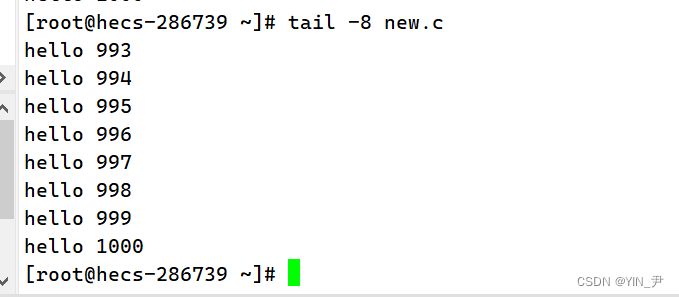
-8,就显示后8行。
总结一下:
语法: tail[必要参数][选择参数][文件] 功能: 用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。 选项: -n<行数> 显示行数
8. 命令行管道(了解)
下面我们再来了解一个东西。
如果我现在想统计一个文件有多少行? 那我们上面了解过一个指令wc嘛,他可以统计文件的信息,-l就是只显示行数

没毛病,这就统计出来了。 那我们上面还学了cat,可以显示文件内容
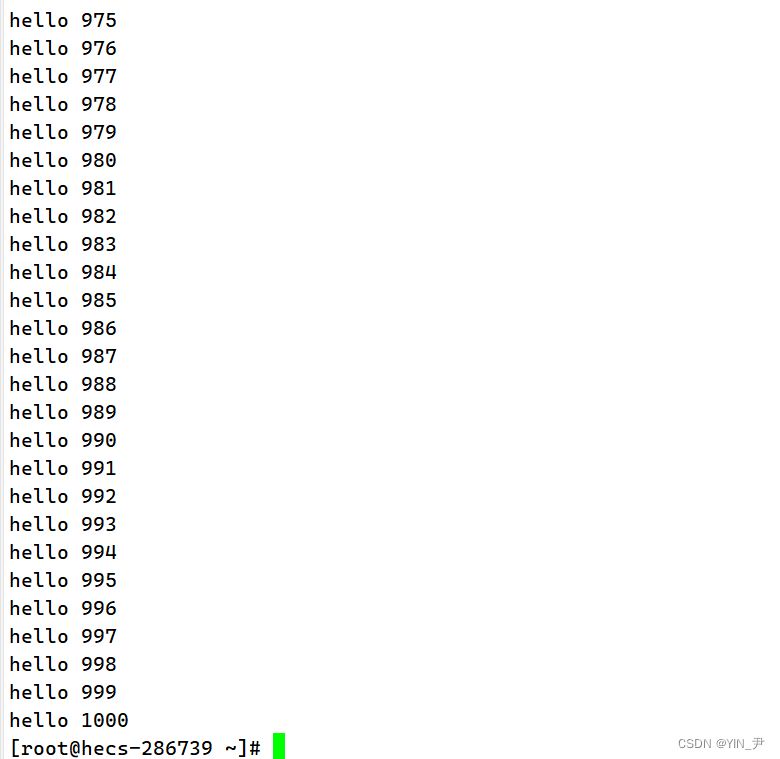
那现在有这么一条指令,也可以统计出行数

那条指令是什么意思呢?这里的|又是啥?
🆗,这就是接下来要给大家介绍的一个东西
这个|在Linux中我们把它叫做管道 那说到管道,大家应该并不陌生,我们现实生活中也有很多管道。 那管道呢一般都是用来传输资源的,它肯定有入口也有出口,比如说水管就是传输水资源的。 那在我们的计算机里面,最重要的资源就是数据。 所以计算机中的管道就可以理解成连接两条指令去传输数据的一个东西。 那现在再来看上面那条指令cat new.c | wc -l
该怎么理解它呢?
对于管道,我们也可以把它当作一个文件来看。 在|的两侧其实是两个命令,首先cat new.c,正常情况下它是把文件的内容直接显示到显示器上(可以理解成把文件内容写入到显示器这个“文件”中了),那现在它连接到了管道上,所以就把文件的内容写入到了管道里。 那后面的wc -l,它正常情况是后面跟一个文件,统计该文件的信息,但是现在它接收了管道里面输出的文件数据,所以就可以统计管道输出的文件的信息。

那对于管道,包括前面提到的重定向,我们后面都会进行详细的讲解,现在大家简单了解一下,会用就可以了。
那现在有这样一个问题:
对于我们上面创建的那个大文本new.c,现在有了head和tail,我们想拿到文本的前几行或者后几行都是很容易的。 那如果我现在想拿到中间的,比如500到520行的内容,可以怎么做呢? 大家可能会想到这样的方法: 你不是想拿到500到520行的吗,那我可以先拿到前520行的 我用head获取前520行的数据,但是head直接显示到显示器上了,所以,我可以把它重定向到一个文件里面

然后tmp.txt这个文件里面就是前520行的内容。

那然后呢,我们用tail获取tmp.txt的后20行是不是就行了
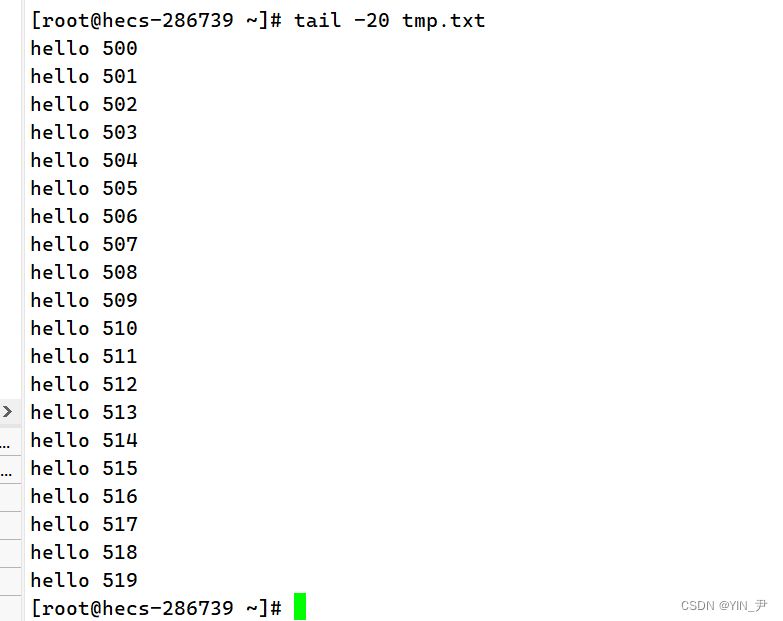
但是这个过程我们利用了一个临时文件tmp.txt,那如果不让你创建临时文件,能做到吗?
那当然是可以的,我们就可以通过管道来搞
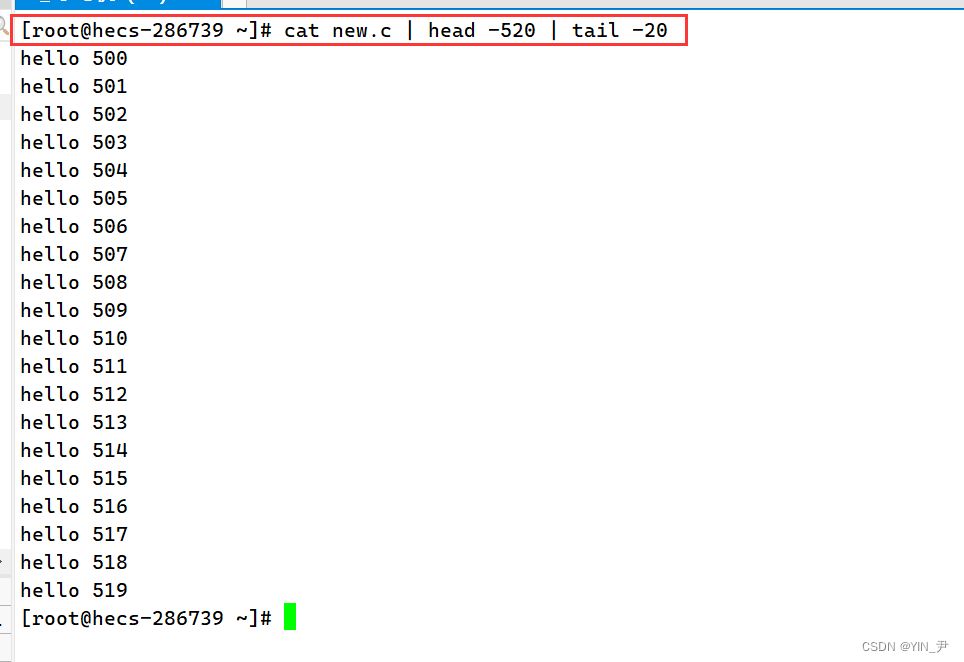
这样就可以了,简单解释一下: cat new.c正常是显示到显示器上,但现在我们通过管道传给head -520,只取前520行,然后再通过管道传给tail -20,就拿到了500到520行的内容。 那继续我想统计一下输出的结果的行数,怎么办
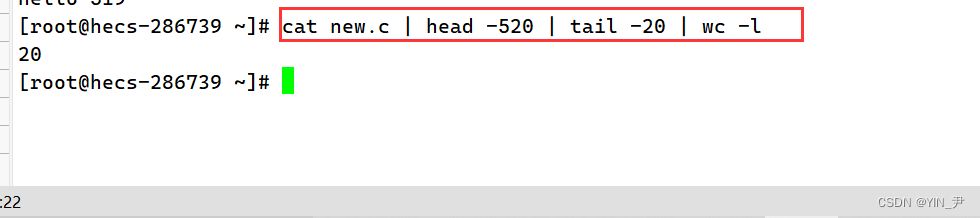
再添一条管道,输给wc统计就可以了。
管道的了解就先到这里。
9. 时间相关的指令
下面呢我们来学习一些时间相关的指令。
显示时间
首先如果我们想在Linux中获取时间信息
就可以用一个命令叫做date:

另外呢,我们还可以自己去指定时间显示的一个格式
%H : 小时(00…23) %M : 分钟(00…59) %S : 秒(00…61) %X : 相当于 %H:%M:%S %d : 日 (01…31) %m : 月份 (01…12) %Y : 完整年份 (0000…9999) %F : 相当于 %Y-%m-%d date 指定格式显示时间: date +%Y:%m:%d
演示一下:
假设我只想看年份

年份+月份
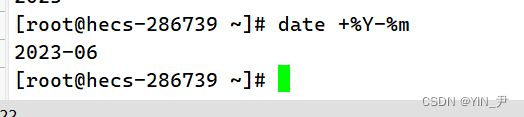
注意,中间这个-是我们自己随意指定的,可以任意更改

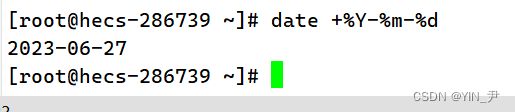
显示年月日
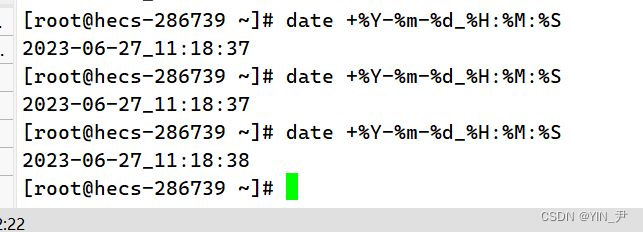
年月日时分秒全显示
其它的大家可以自己试一下,总结:
date显示 date 指定格式显示时间: date +%Y:%m:%d date 用法:date [OPTION]… [+FORMAT] 在显示方面,使用者可以设定欲显示的格式,格式设定为一个加号后接数个标记,其中常用的标记列表如下 %H : 小时(00…23) %M : 分钟(00…59) %S : 秒(00…61) %X : 相当于 %H:%M:%S %d : 日 (01…31) %m : 月份 (01…12) %Y : 完整年份 (0000…9999) %F : 相当于 %Y-%m-%d
时间戳
然后我们再来了解一个东西——时间戳
时间-》时间戳
如果我们直接date +%s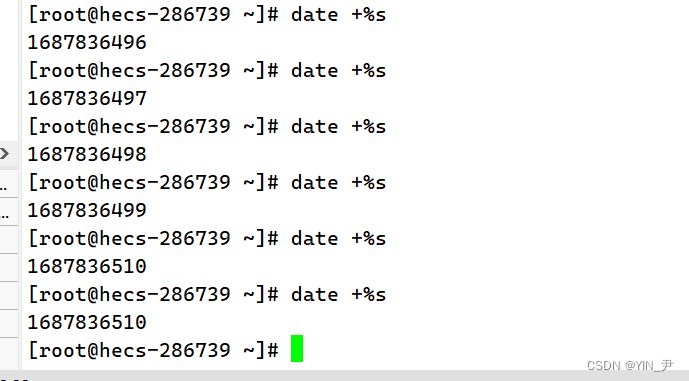
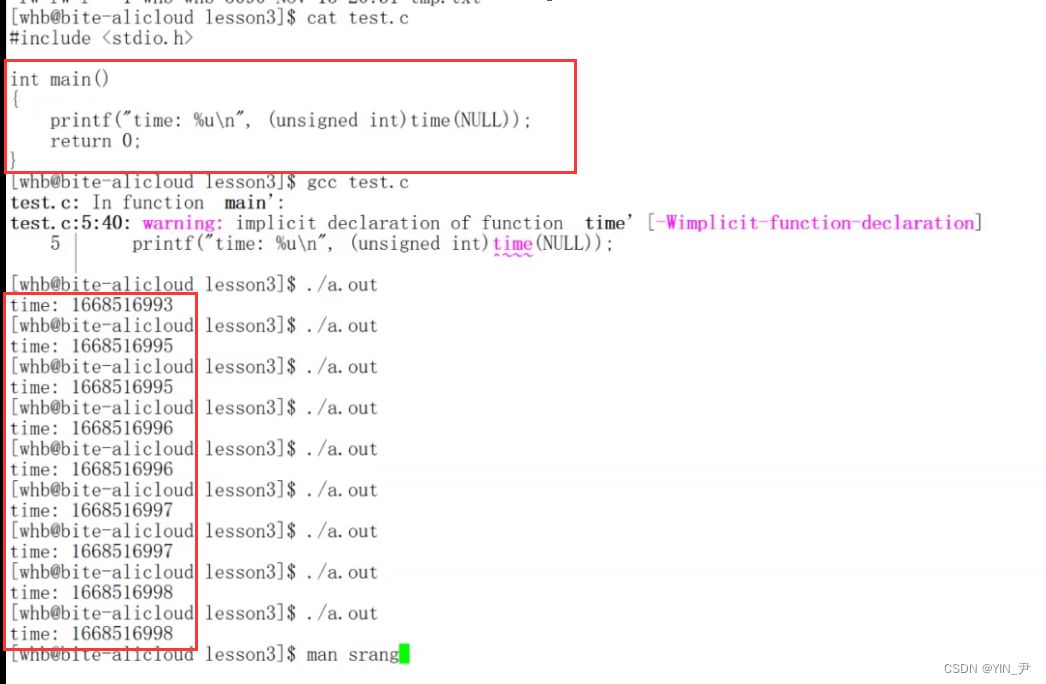
显示的这个东西就是时间戳,那这个数值其实是从1970年1月1日0时0分0秒(格林威治时间,北京时间是1970年01月01日08时00分00秒)到现在这一时刻的累计的秒数。 之前C语言文章有实现过扫雷和三子棋的小游戏,里面生成随机数时设置随机数生成器其实传的就是时间戳
时间戳-》时间
那这个时间戳其实跟我们现实生活中用的这个时间是可以进行一个对应的转换的
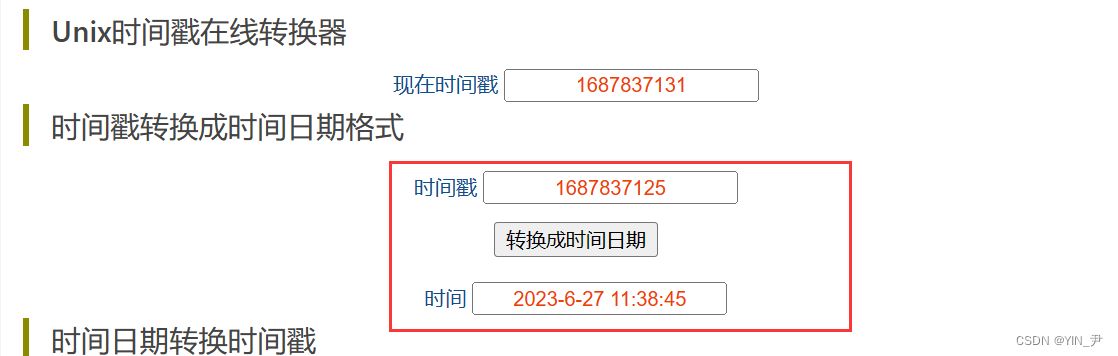
那在Linux上我们也可以通过相应的命令去转换
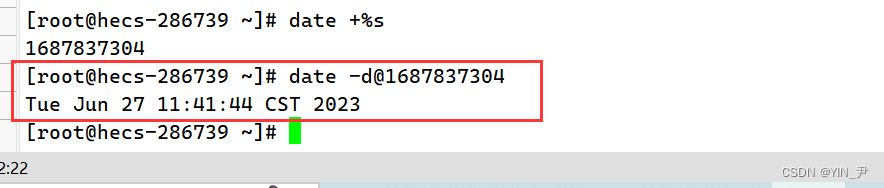
当然我们也可以指定格式去显示
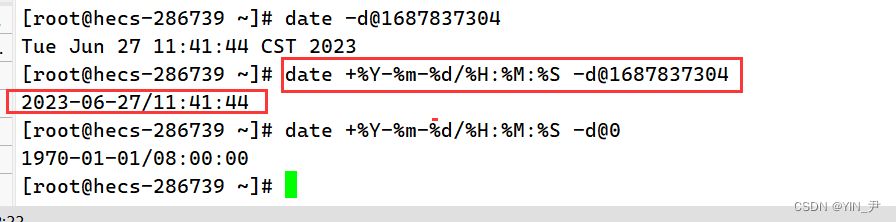
总结:
时间->时间戳:date +%s 时间戳->时间:date -d@1508749502 Unix时间戳(英文为Unix epoch, Unix time, POSIX time 或 Unix timestamp)是从1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒
设定时间
date -s //设置当前时间,只有root权限才能设置,其他只能查看 date -s 20080523 //设置成20080523,这样会把具体时间设置成空00:00:00 date -s 01:01:01 //设置具体时间,不会对日期做更改 date -s “01:01:01 2008-05-23″ //这样可以设置全部时间 date -s “01:01:01 20080523″ //这样可以设置全部时间 date -s “2008-05-23 01:01:01″ //这样可以设置全部时间 date -s “20080523 01:01:01″ //这样可以设置全部时间
10. cal指令
cal(calendar)命令可以查看日历
如果只敲一个cal,默认显示本月的日历
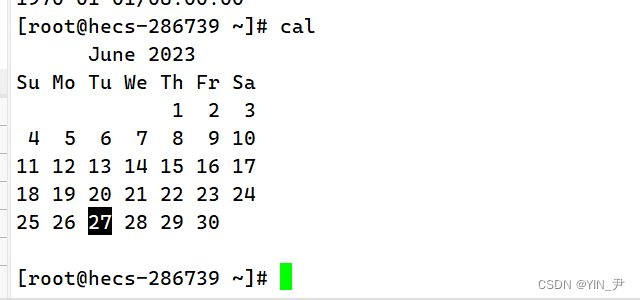
另外,还可以指定年份查看某一年的日历
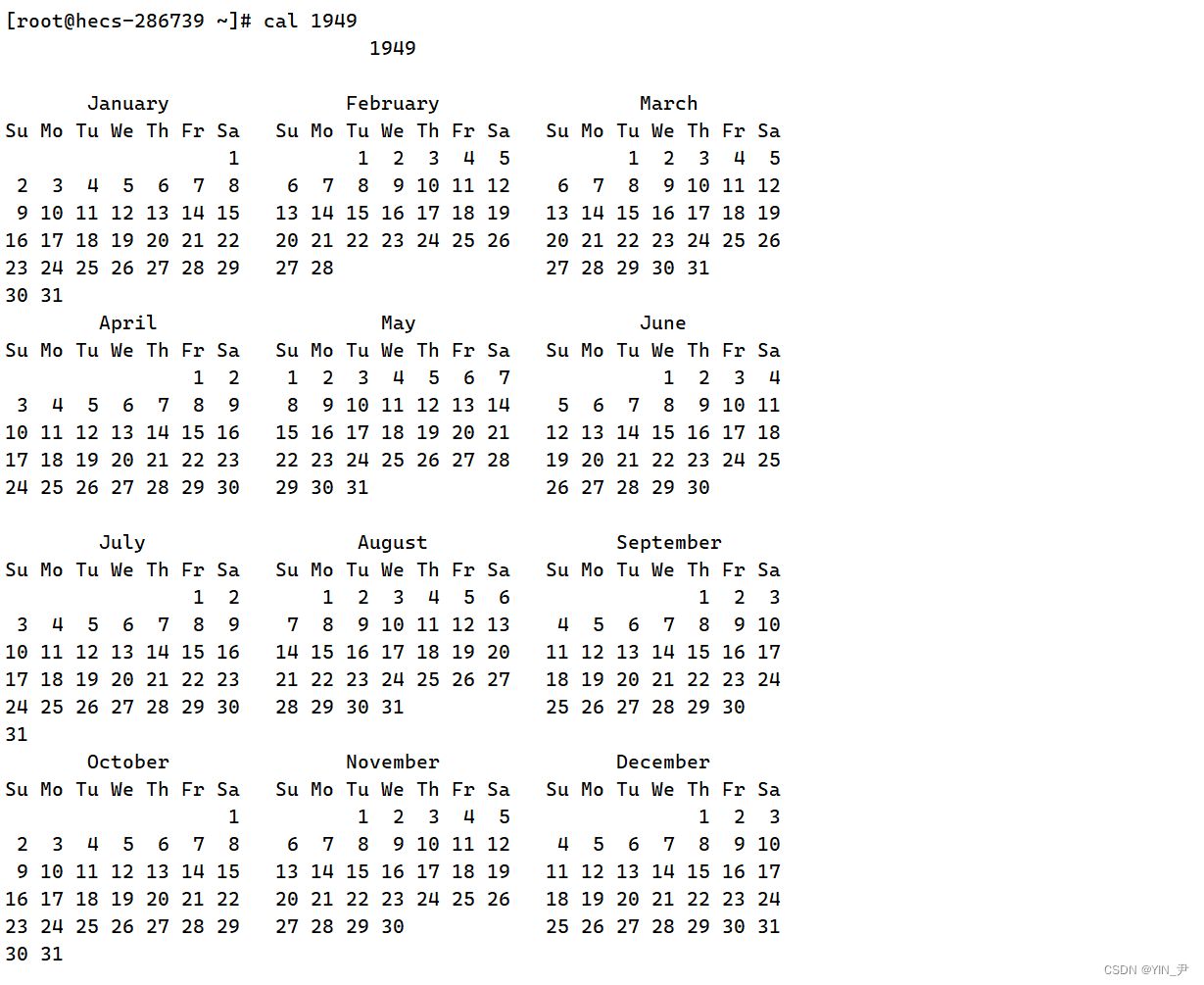
还有cal -3显示系统前一个月,当前月,下一个月的月历
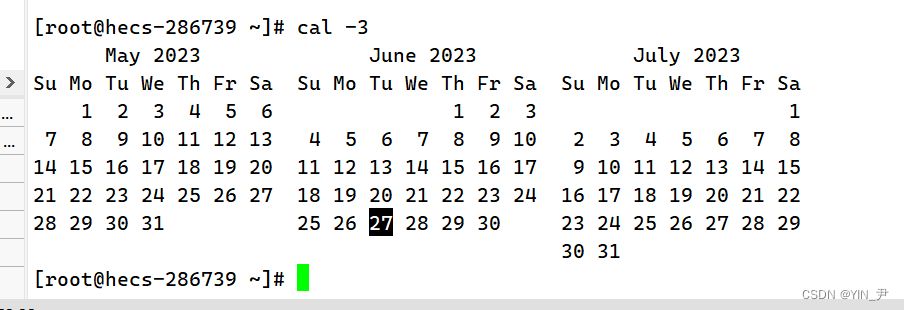
总结:
cal命令可以用来显示公历(阳历)日历。公历是现在国际通用的历法,又称格列历,通称阳历。“阳历”又名“太阳历”,系以地球绕行太阳一周为一年,为西方各国所通用,故又名“西历”。 命令格式: cal [参数][月份][年份] 功能: 用于查看日历等时间信息,如只有一个参数,则表示年份(1-9999),如有两个参数,则表示月份和年份 常用选项: -3 显示系统前一个月,当前月,下一个月的月历 -j 显示在当年中的第几天(一年日期按天算,从1月1号算起,默认显示当前月在一年中的天数) -y 显示当前年份的日历
11. 补充
在这里再给大家补充一点内容。
sort 指令
现在有一个文件,我给他里面写入一点内容
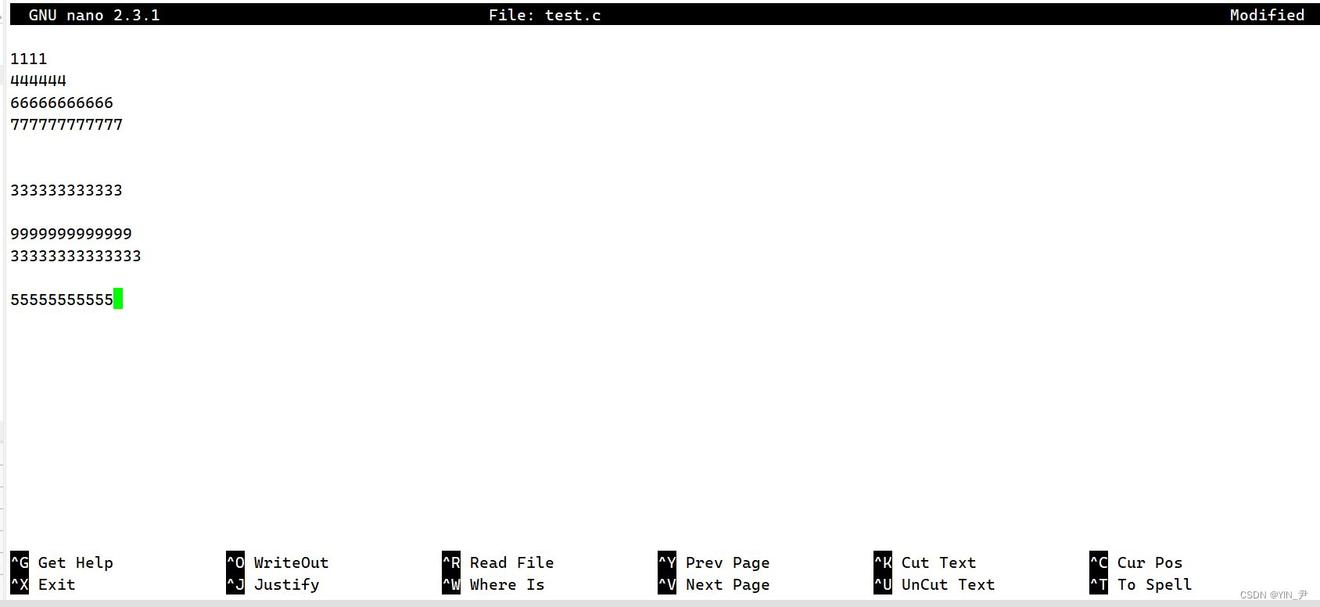
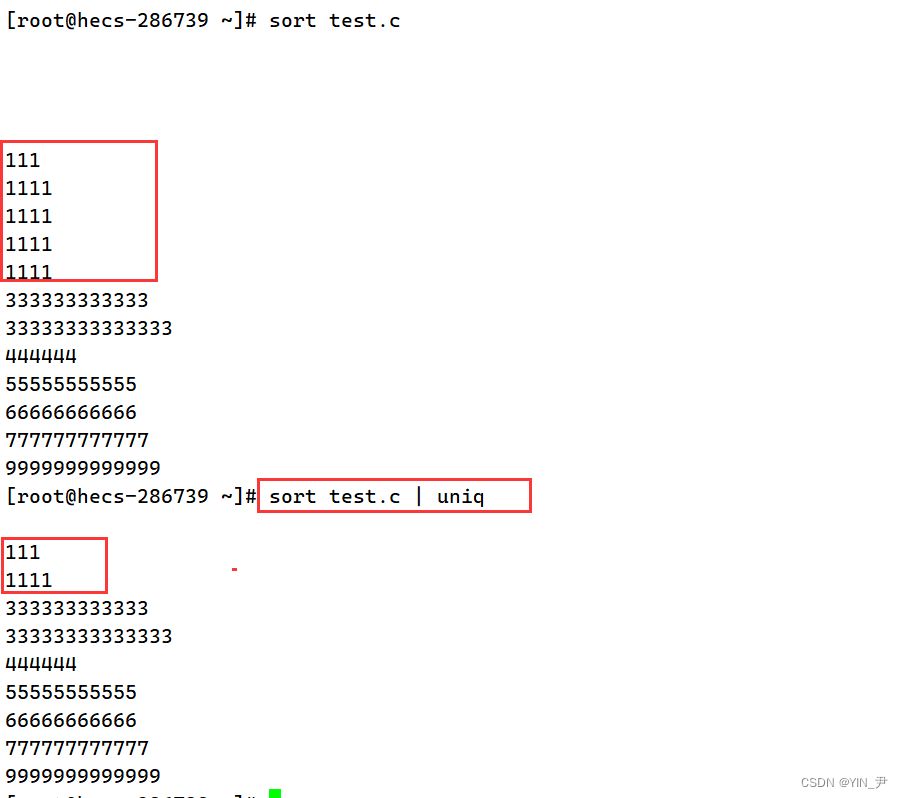
然后我执行 sort test.c
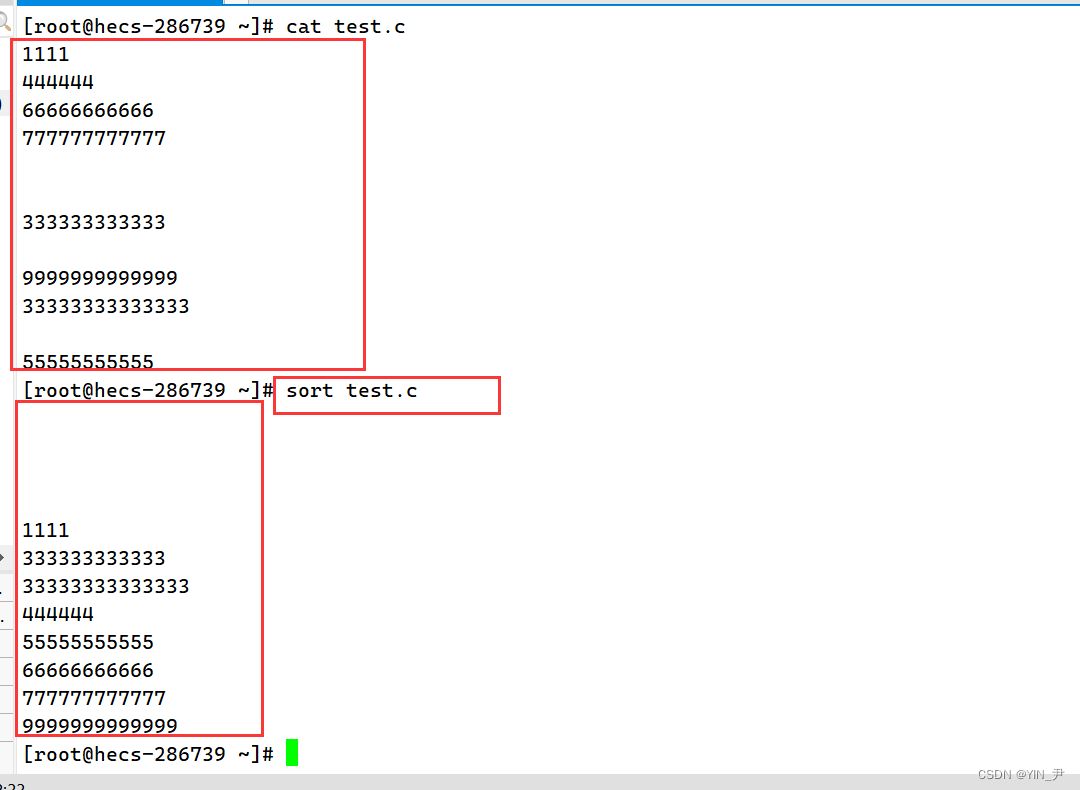
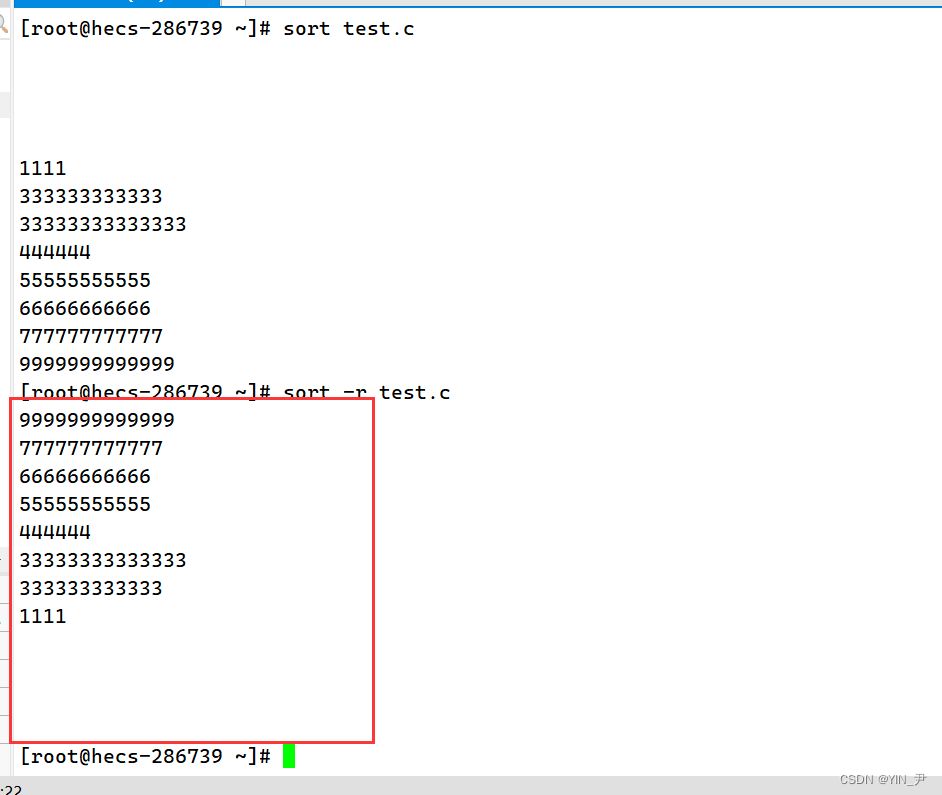
我们看到它可以对文本内容进行排序,排序规则其实是比较每行数据第一个字母的ASCII码值(相同比较后面的),默认升序。 那想降序呢? sort -r test.c ,r——reverse
uniq 指令
uniq 指令可以对文件内容进行去重
12. find指令:(灰常重要) -name
find呢,顾名思义就是查找,寻找。它可以帮助我们在Linux目录结构下查找文件
演示一下: find 指定路径 -name 文件名
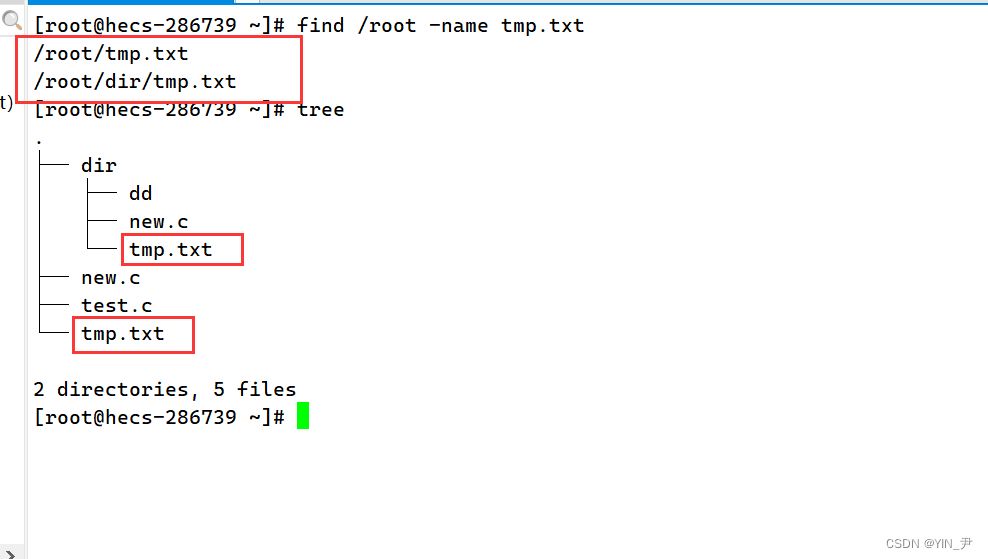
他就可以帮我们找到指定路径下所有名字为tmp.txt的文件。 就类似于Windows下的这个搜索
总结:
Linux下find命令在目录结构中搜索文件,并执行指定的操作。 Linux下find命令提供了相当多的查找条件,功能很强大。由于find具有强大的功能,所以它的选项也很多,其中大部分选项都值得我们花时间来了解一下。 即使系统中含有网络文件系统( NFS),find命令在该文件系统中同样有效,只你具有相应的权限。 在运行一个非常消耗资源的find命令时,很多人都倾向于把它放在后台执行,因为遍历一个大的文件系统可能会花费很长的时间(这里是指30G字节以上的文件系统)。 语法: find pathname -options 功能: 用于在文件树种查找文件,并作出相应的处理(可能访问磁盘) 常用选项: -name 按照文件名查找文件
那除了find,这里再给大家补充几个查找的命令
which 指令
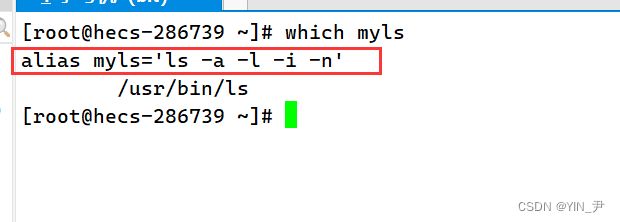
首先有一个指令叫做which,它可以帮我们查找一个指令(指令其实也是文件,.exe的可执行文件)存在于什么路径下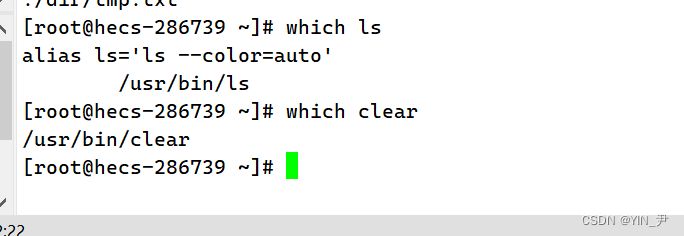
whereis 指令
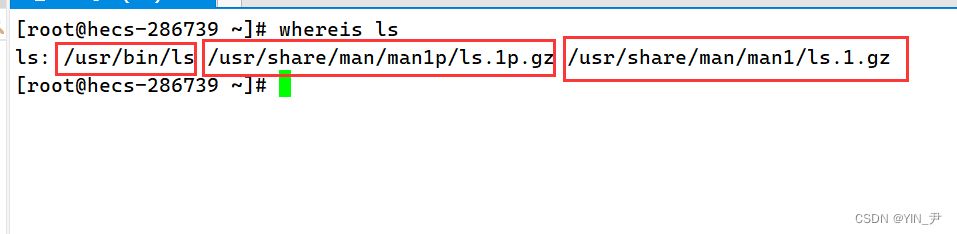
然后还有一个用于查找的命令叫做whereis
该指令会在特定目录中查找符合条件的文件。这些文件应属于原始代码、二进制文件,或是帮助文件。
alias 指令
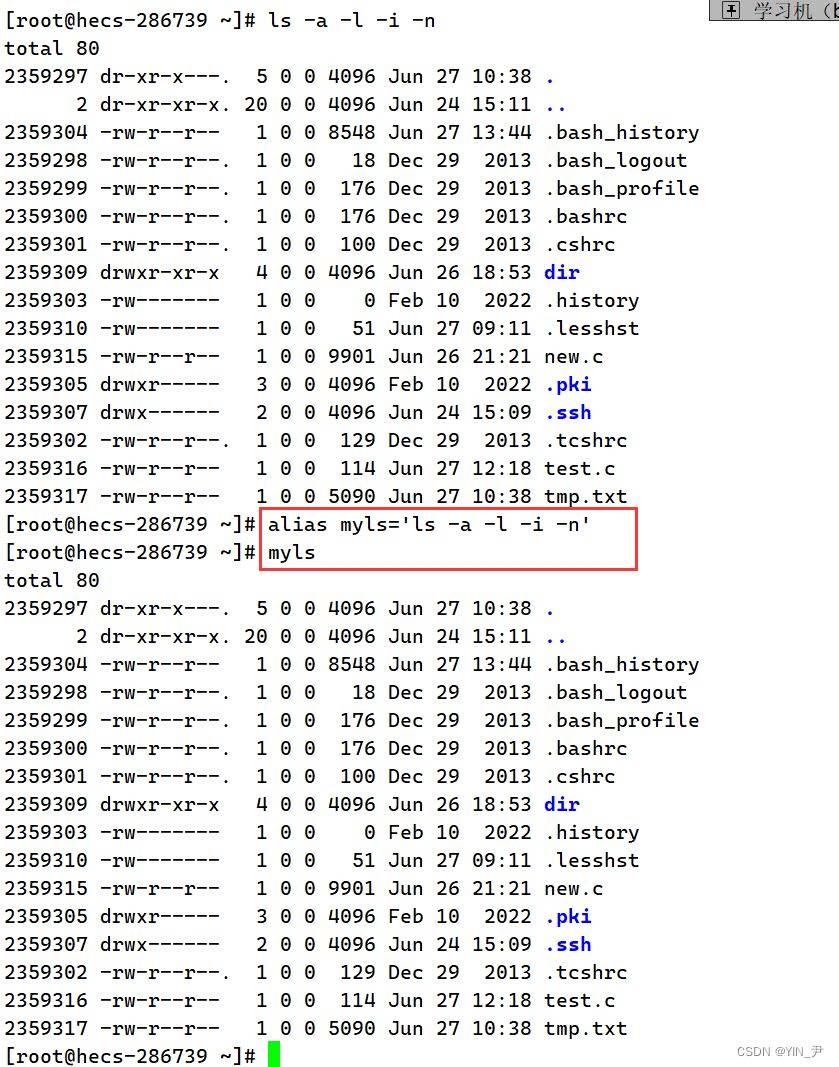
alias指令使得我们可以给指令起别名
比如我现在用到一条这样的指令。 那我觉得它带的选项太多了,太难记了,我想给它简化一下。 那这时候就可以使用alias给该命令起一个别名,比如myls 那就这样写alias myls='ls -a -l -i -n',这句指令执行之后,myls就等同于ls -a -l -i -n了
13. grep指令
grep是一个文本搜索工具,可以从文本文件或管道数据流中筛选匹配的行和数据
grep [选项] 搜寻字符串 文件

当它也可以加选项,-n :顺便输出行号
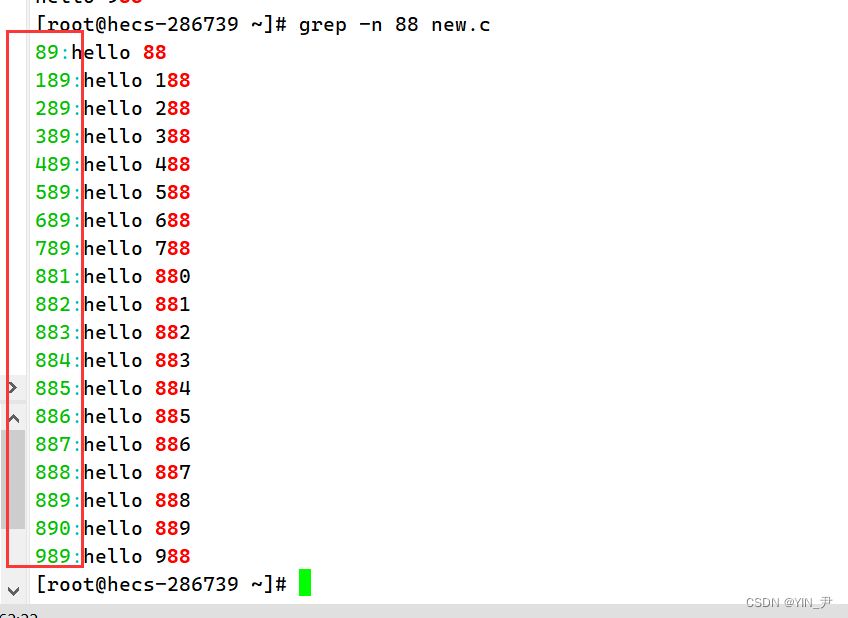
-v :反向选择,亦即显示出没有 ‘搜寻字符串’ 内容的那一行
先搞一个文件出来
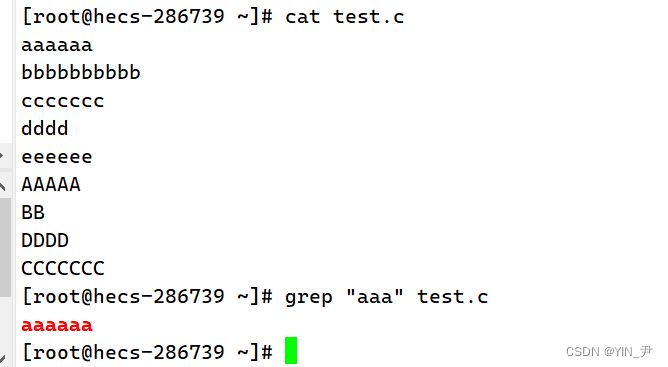
如果我们要匹配带"aaa"的内容
那我加一个-v
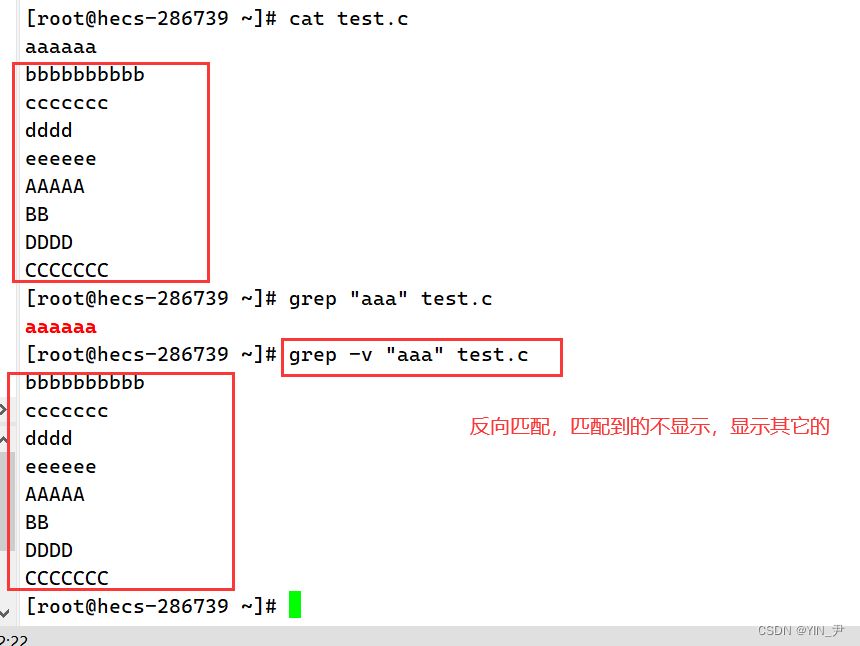
-i :忽略大小写的不同,所以大小写视为相同
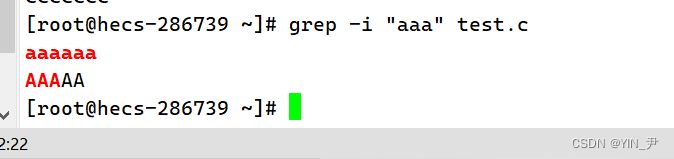
组合使用
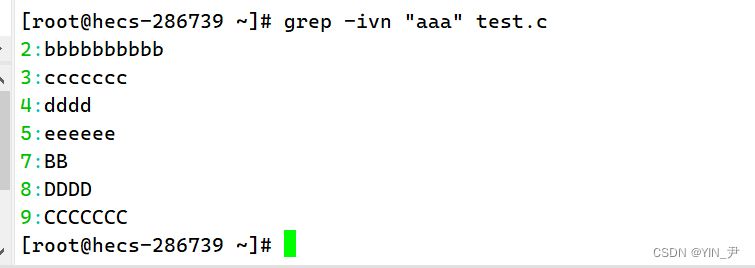
配合管道

总结
语法: grep [选项] 搜寻字符串 文件 功能: 在文件中搜索字符串,将找到的行打印出来 常用选项: -i :忽略大小写的不同,所以大小写视为相同 -n :顺便输出行号 -v :反向选择,亦即显示出没有 ‘搜寻字符串’ 内容的那一行
14. zip/unzip指令
那zip和unzip指令其实对应的就是对文件进行压缩和解压缩(zip后缀)的操作 演示一下,先来个压缩
当前路径下有一个目录dir ,现在我们相对它进行压缩 语法: zip 压缩文件.zip 目录或文件 如果用不了大家可以安装一下 yum -y install zipyum -y install unzip
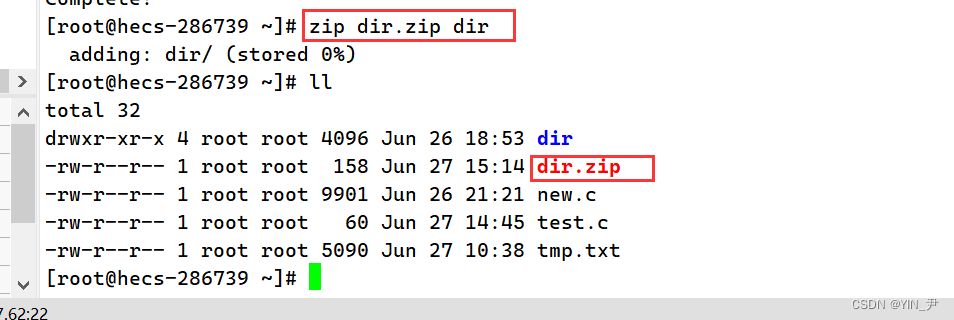
我们看到现在就多了一个压缩包。
那我现在想对这个压缩包解压:
那当前目录已经有dir目录了,所以我把dir.zip移动到别处进行解压
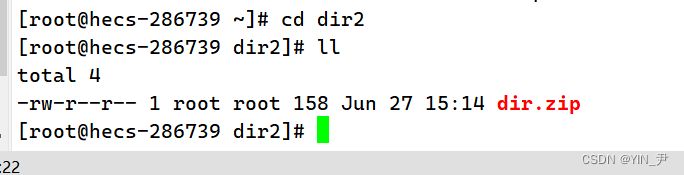
我把它放到dir2这个目录下,在这里解压 怎么解压呢,很简单:unzip 压缩包名
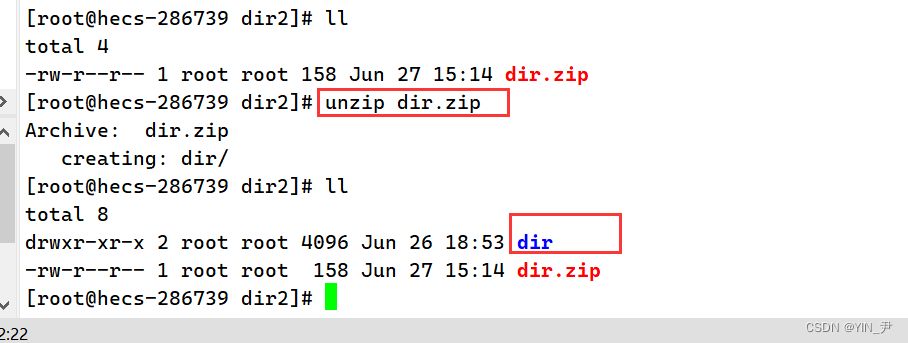
🆗,就好了。 但是呢?
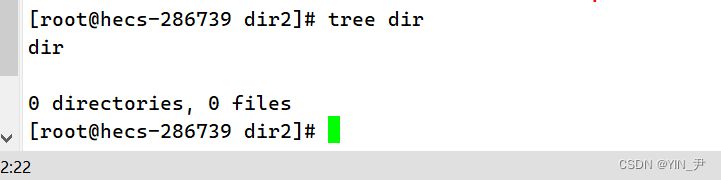
我们发现dir里面啥也没有 可是我们原来的dir里面是有东西的啊
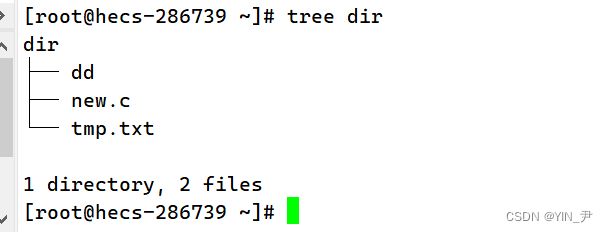
怎么回事?
因为我们刚才只是打包压缩了一个空目录,并没有对里面的内容打包压缩,那怎么办呢? -r 递 归处理,将指定目录下的所有文件和子目录一并处理 那我们现在重新对dir打包压缩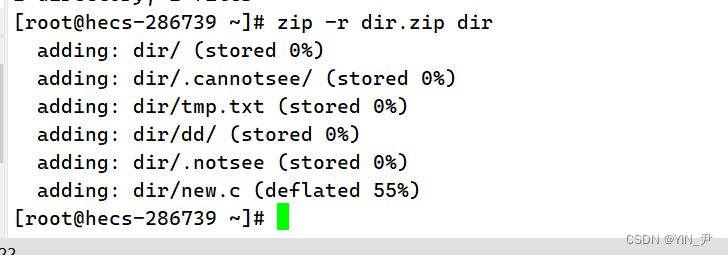
这下就可以了。
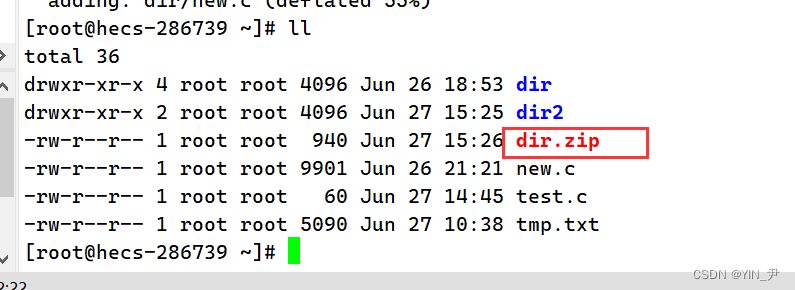
然后我们还把它移到dir2里面解压
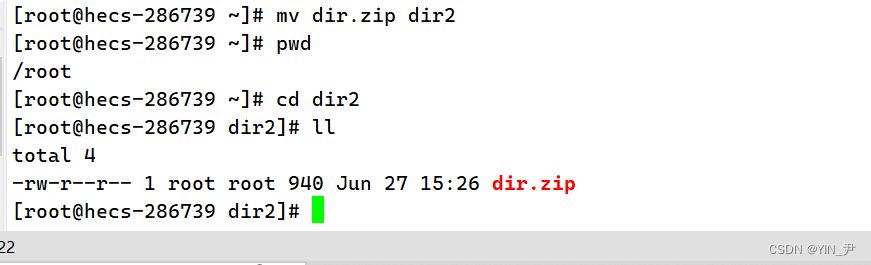
解压
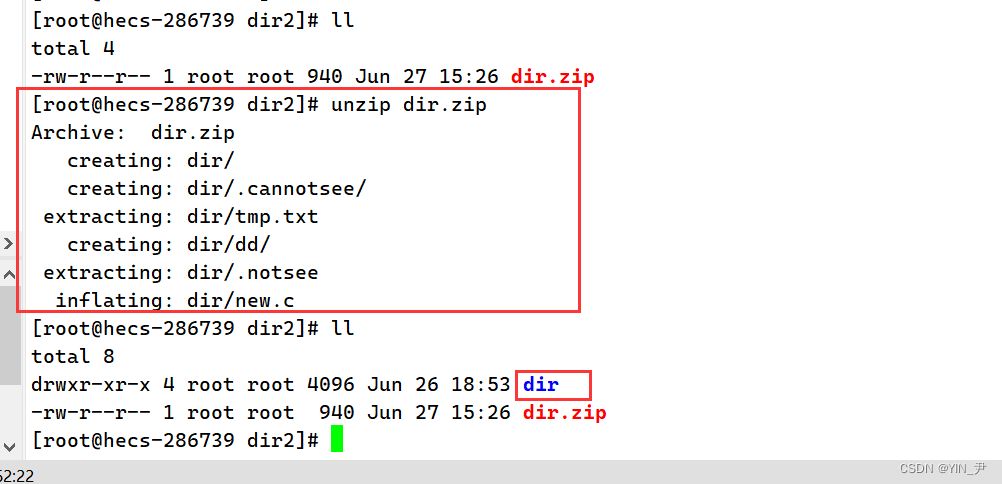
然后再来看
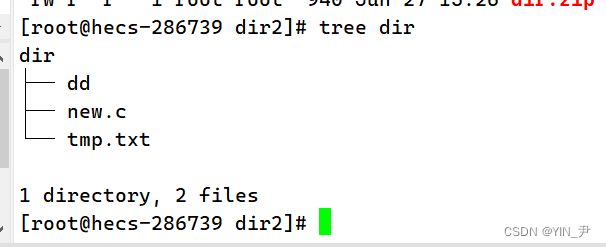
就可以了。
但是呢,我们刚才解压的时候,unzip后面没有跟任何选项,那它默认其实就解压到了当前所处的目录下。那如果我们想把它解压到指定路径下,可以吗?
当然是可以的,unzip后面加一个选项-d,并指定具体的路径就行了
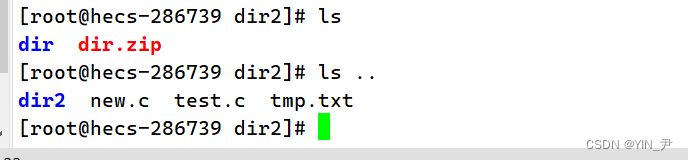
来看,当前我所处的目录dir2下面有dir.zip这个压缩包,现在我想把它解压到上级目录里面
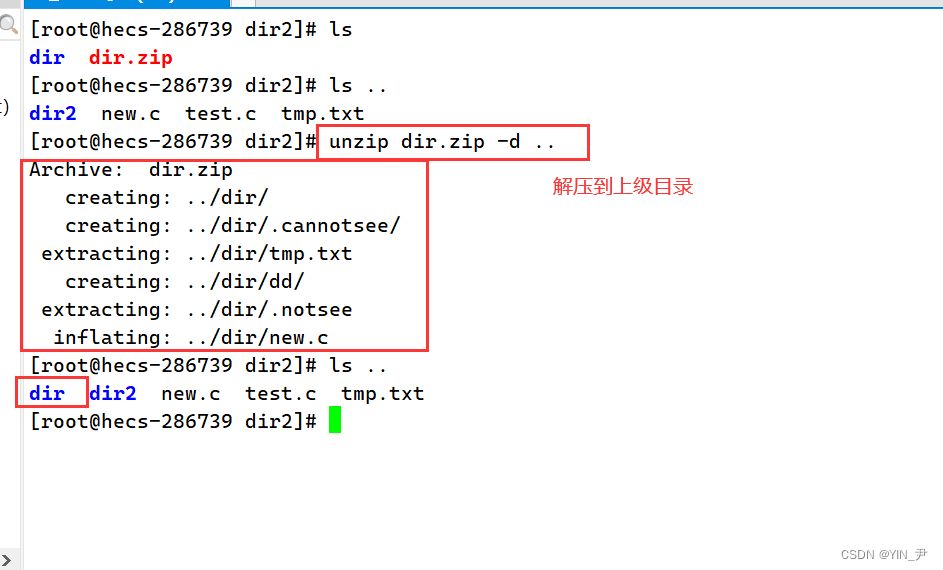
就可以了。
总结:
语法: zip 压缩文件.zip 目录或文件 功能: 将目录或文件压缩成zip格式 常用选项: -r 递 归处理,将指定目录下的所有文件和子目录一并处理 举例: 将test2目录压缩:zip -r test2.zip test2 解压到tmp目录:unzip test2.zip -d /tmp
15. tar指令(重要)
那tar呢也是一个用来打包和压缩的命令,我们来介绍一下,可以先来看它对应的一些选项
语法:tar [-cxtzjvf] 文件与目录
-c :建立一个压缩文件的参数指令(create 的意思); -x :解开一个压缩文件的参数指令! -t :查看 tarfile 里面的文件! -z :是否同时具有 gzip 的属性?亦即是否需要用 gzip 压缩? -j :是否同时具有 bzip2 的属性?亦即是否需要用 bzip2 压缩? -v :列出列出压缩和解压缩过程处理涉及的详细的文件的信息 -f :使用档名,请留意,在 f 之后要立即接档名喔!不要再加参数!(所以使用f选项的话,一般放在最后面) -C : 解压到指定目录
那我们来简单练习一下
那还是这个dir目录
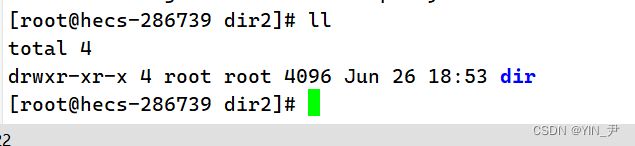
我们现在用tar对它打包压缩一下: 首先思考一下要用那些参数: 我们要打包压缩,-c(建立一个压缩文件)选项肯定要加,使用什么属性压缩呢,那我们这里以 gzip 压缩压缩为例,那就是-z,最后加个-f,给压缩之后的压缩包起个新名字。 使用czf压缩的包我们一般用tgz后缀 所以就是这样的:
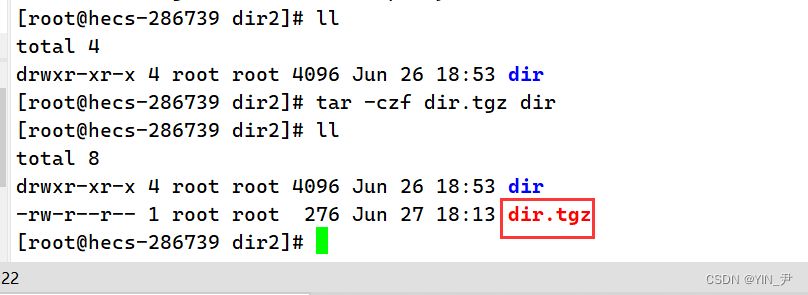
🆗,那这样就压缩成功了。 那原目录我们其实就可以不用要了,因为有了压缩包,一解压我就又可以拿到它了。
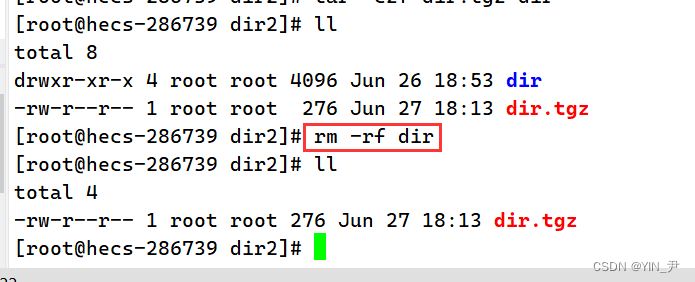
然后我们来进行解压:
解压要用那些选项呢? 🆗,其实我们把打包压缩时的选项czf中的c换成x就行了。
z还要加上,并且不要换成其它的,因为我们压缩和解压的属性要一致,然后f也加上,因为我们还要使用档名。 所以这样就行了:
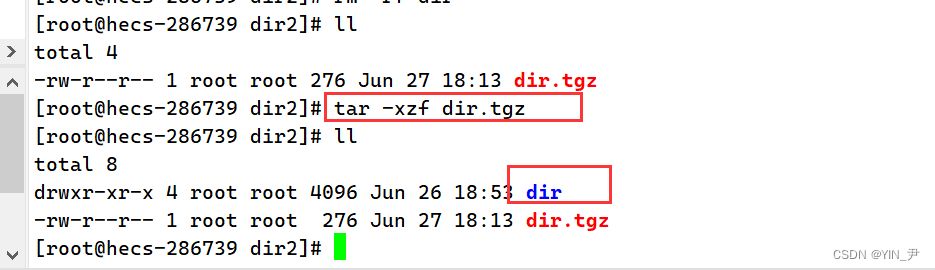
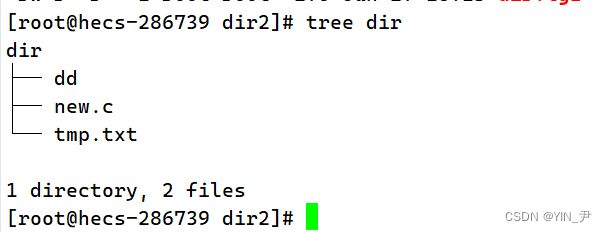
就解压好了。
另外有时候我们拿到一个这样一个压缩包,可能不想解压它,但想看一下它里面有哪些文件
那就可以这样

那我们看到他就把里面的文件和目录列出来了,包括隐藏的。 那这里其实就用到了-t这个选项:查看 tarfile 里面的文件 z和f呢我们还是要加上。 另外还可以加上这个选项-v:列出列出压缩和解压缩过程处理涉及的详细的文件的信息
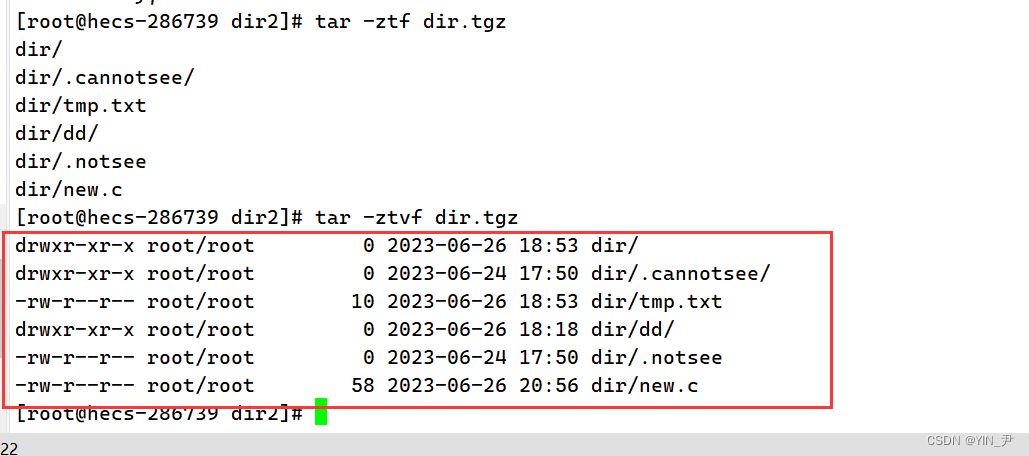
还有就是如果tar压缩的时候我们也想压缩到指定目录
可以用这个参数-C(大写) : 解压到指定目录
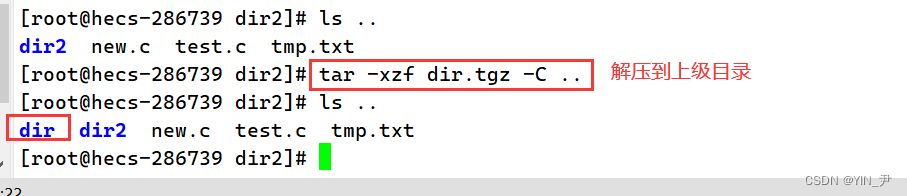
然后想告诉大家的是
其实在Linux中,不同后缀的压缩包种类还是挺多的,我们这里讲了两个比较常见的,如果后续大家遇到其它的不会的话,可以直接去网上搜索或查阅相关的资料学习对应的命令就可以。
16. bc指令
bc其实就是Linux中的计算器,怎么用呢?
我们直接敲bc回车,发现它卡在这里等待我们输入,然后我们输出表达式,它就可以返回结果
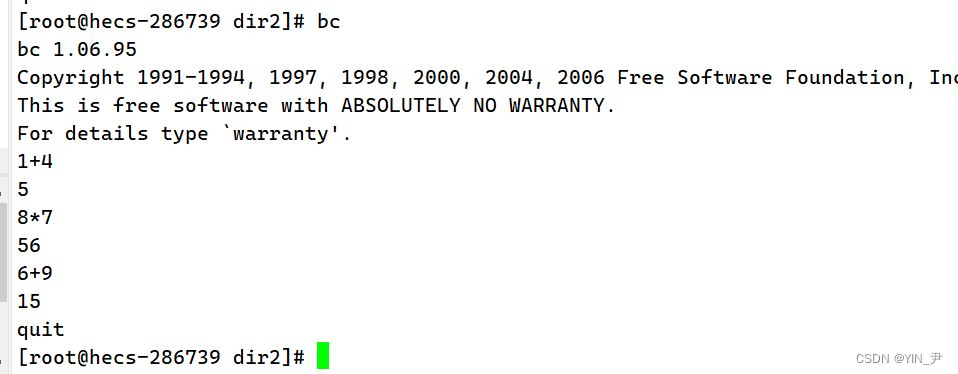
输入quit或者按ctrl+c可以退出程序。
另外我们还可以这样玩:

17. uname 指令
语法:uname [选项] 功能: uname用来获取电脑和操作系统的相关信息。 补充说明:uname可显示linux主机所用的操作系统的版本、硬件的名称等基本信息。 常用选项: -a或–all 详细输出所有信息,依次为内核名称,主机名,内核版本号,内核版本,硬件名,处理器类型,硬件平台类型,操作系统名称 -r或–release 显示操作系统的发行编号
演示一下:

补充,查看Linux发行版本信息:
cat /etc/redhat-release
18. 几个重要的热键
[Tab]按键—具有『命令补全』和『档案补齐』的功能 [Ctrl]-c按键—让当前的程序『停掉』 [Ctrl]-d按键—可以用来取代exit,连续按[Ctrl]-d就可以退出xshell
然后再补充几个:
[Ctrl]-r:可以搜索历史指令
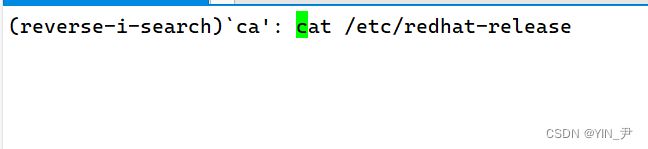
搜出来想要的命令按左键或右键可以选中。
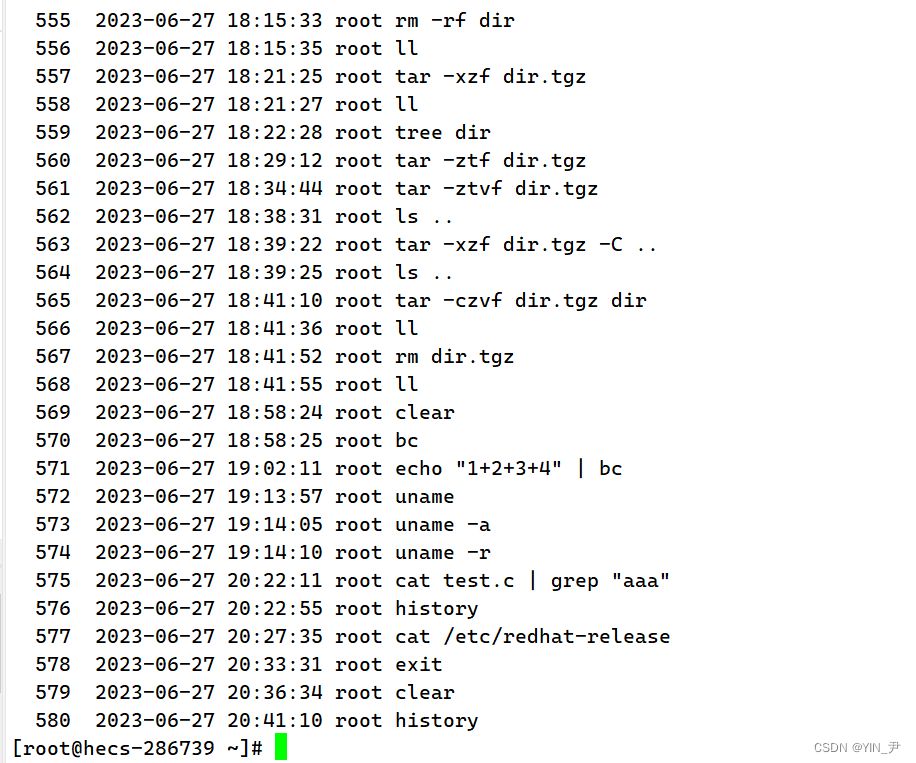
history:显示输入过的历史指令
19. 关机
语法:shutdown [选项] 常见选项:
-h : 将系统的服务停掉后,立即关机。 -r : 在将系统的服务停掉之后就重新启动 -t sec : -t 后面加秒数,亦即『过几秒后关机』的意思
如果你用的是云服务器的话,就没必要关机。
20. 以下命令作为扩展
◆ 安装和登录命令:login、shutdown、halt、reboot、install、mount、umount、chsh、exit、last; ◆ 文件处理命令:file、mkdir、grep、dd、find、mv、ls、diff、cat、ln; ◆ 系统管理相关命令:df、top、free、quota、at、lp、adduser、groupadd、kill、crontab; ◆ 网络操作命令:ifconfig、ip、ping、netstat、telnet、ftp、route、rlogin、rcp、finger、mail、 nslookup; ◆ 系统安全相关命令:passwd、su、umask、chgrp、chmod、chown、chattr、sudo ps、who; ◆ 其它命令:tar、unzip、gunzip、unarj、mtools、man、unendcode、uudecode