引言
Web 网站性能优化在社区中已经是老生常谈的话题了,社区内有非常多优秀的文章和大家分享关于 Css、Js 等静态资源的极限压缩、预加载以及拆包等等优化手段。
可是,大多数 Web 应用站点的性能瓶颈除了静态资源的加载外通常存在大量的数据交互请求。要想我们的 Web 站点拥有良好的用户体验,除了静态资源的优化外,对于数据交互方面的优化也一定是必不可少。
今天这篇文章让我们从另一个角度出发,从数据交互层面来聊聊如何让你的 Web 应用站点获得更好的用户体验。
背景
首先,在开始正文内容之前我们先来和大家聊聊什么是 “从数据请求层面来优化 Web 网站性能” 。
何谓“资源下载时间”
简单来说,传统 Web 网页对于发起一次请求时会存在多个不同的阶段:

如果你有兴趣了解每个字段的具体含义你可以参考Timing breakdown phases explained。
这里,我们重点来关注两个部分:
- Waiting for server response: 简称 TTFB,它代表浏览器正在等待响应时接收到服务器第一个字节的响应时间。
- Content download: 顾名思义,本次网络传输内容下载时间。
Waiting for server response(TTFB)代表服务器处理本次请求的时长,作为前端工程师往往对于这部分时长的优化是需要配合对应 Server 一起来处理。
而 Content download 正是我们在标题中强调的资源下载时间,它代表本次网络传输中浏览器下载服务响应数据的时长。
不难想象,无论是对于 TTFB 还是 Content download 只要我们在一次请求链路中尽可能的缩小这次请求传输耗时,对于依赖这部分数据的页面展示元素会更快的呈现在用户面前。
“资源下载“ 有必要优化吗?
往往在我们打开某个 Web 站点时,传统的 application/json 资源下载耗时通常都会在 100 ms 之内。
“我的接口响应非常快,就不需要优化了吗?”相信大多数同学都会在心里犯嘀咕,对于 100ms 的优化体验到底重要吗。
通常情况下,Web 传输的数据时间与用户的实际带宽呈反比关系。当用户的带宽越高,数据传输速度就越快,加载时间就会相应缩短。而在带宽较低的情况下,数据传输速度会变慢,导致页面加载时间延长。
这样就意味着,在用户网络良好的情况下对于资源下载的优化 IOI 显得并不是那么重要。不过我们永远无法去要求用户在带宽上对于我们的 Web 站点进行妥协。
更多时候,所谓优化的方式更多代表的是面对不同的终端用户群体访问我们的 Web 网站希望都可以得到快速的页面反馈,如果仅仅对于设备、网络良好的用户进行网站性能优化反倒是将网站访问速度慢的压力从开发者转移到了用户身上。
所以,并非是在顺畅网络情况下资源下载耗时短就意味着我们放弃对于它的优化,更何况熟悉前端的同学一定会遇到某些大量数据传输的接口以及移动端网络不佳的各个边界场景对吧。
Web Streaming
概念
熟悉 NodeJs 的同学对于 Streaming 的概念一定不陌生,在 Web 的执行环境下同样也提供了一组 Stream API 让 JavaScript 具有访问来自网络的数据流的能力。
在网络传输中,HTTP2 中通过二进制分帧层实现数据传输默认已经支持在面对网络数据传输时的 Streaming 方式读取响应,在 HTTP 1.1 中我们可以通过设置 Transfer-Encoding: chunked 响应头表明让传输数据以分块的方式来传输。

简单来说 Streams API 允许我们通过 JavaScript 以编程方式访问通过网络接收的数据流,同时根据我们自己的需求定制化处理返回的数据流。
- 即时数据处理:当数据以块的形式到达时,无需等待整个有效负载即可对其进行处理。这可以显著增强大数据的负载能力以及慢速网络连接的感知性能。
- 细粒度控制:Web Streaming 允许我们控制数据的读取和处理方式,以满足特定的需求和场景。
这里我们来主要聚焦到 ReadableStream 以及 WritableStream。
关于 Streaming 详细的概念和用法你可以参考 MDN - Web Streaming 或者 Vercel - An Introduction to Streaming on the Web。
ReadableStream/WritableStream 示例
- ReadableStream 提供了异步读取数据的能力。
- WritableStream 提供用于将 Streaming 数据写入目的地的能力。
我们来看一个关于 ReadableStream 以及 WritableStream 的简单例子:
const decoder = new TextDecoder();
const encoder = new TextEncoder();
// 创建一个可读流
const readableStream = new ReadableStream({
// 创建可读流时会立即执行,通过访问器为当前当前可读流入队 text
start(controller) {
const text = 'hello, Welcome to flow my Github: 19Qingfeng.';
controller.enqueue(encoder.encode(text));
controller.close();
}
});
// 创建一个可写流
const writableStream = new WritableStream({
// 每当有新的 chunk 准备好写入时,会调用可写流的 write 方法
write(chunk) {
console.log(decoder.decode(chunk));
}
});
readableStream.pipeTo(writableStream); // hello, Welcome to flow my Github: 19Qingfeng.
上边的代码中我们通过 TextEncoder 将 hello, Welcome to flow my Github: 19Qingfeng. 转化为 stream 从而在创建可读流时将它压入流中。
同时,我们在随后创建了一个 writableStream 可写流对象,将可读流中的内容通过 pipeTo 方法传输给可写流。
writableStream 会在每次有新的 chunk 准备好写入时会触发 write 方法,在 write 方法中我们使用了 TextEncoder 去将 stream 进行解码,自然控制台也会输出 hello, Welcome to flow my Github: 19Qingfeng。
关于 WritableStream/ReadableStream 的概念以及深入用法,有兴趣了解的小伙伴可以自行查询 MDN 说明文档。
Web Fetch
概念
Fetch API 提供了一个获取资源的接口,Web Fetch 更多像是 XMLHttpRequest 的替代品而生。
Fetch 的核心在于对 HTTP 接口的抽象,包括 Request,Response,Headers,Body,以及用于初始化异步请求的 global fetch。
简单来说,Fetch Api 可以提供了一组非常强大的 Api 可以让我们通过 JavaScript 来操作这些抽象的 HTTP 模块。
基础用法
通常情况下,我们会使用 Fetch Api 配合 response.json 来获取远程服务接口响应的数据:
async function getUserJSON() {
let url = 'https://api.github.com/users/19Qingfeng';
try {
let response = await fetch(url);
return await response.json();
} catch (error) {
console.log('Request Failed', error);
}
}
fetch 方法的返回值是一个 Promise<Response> 对象,我们可以使用 fetch 返回的 response 对象中的 json 方法从 Response 中获取 json 格式的数据响应。
Streaming Fetch
实际上,Fetch Api 返回的 Response 上还有一个 body 属性。
我们可以通过返回的 response 的 body 属性获取一个响应的 ReadableStream 实例。
这也就意味上,我们可以在网络传输时完全不必等待下载完所有 Response 后通过 json 方法来一次性读取响应内容。
而是可以通过 response.body 以 ReadableStream 的方式来进行分批读取数据从而提升接口数据响应速度。
直接读取 res.body 数据
接下来我们先来看看如何使用 Fetch Response 的 body 属性。
首先,我们先使用 express 快速创建一个 NodeServer 用来承载服务端应用:
// express 服务度代码
const express = require('express');
const data = require('./data.json');
const path = require('path');
const app = express();
app.use(express.static(path.resolve(__dirname, '../public')));
app.post('/api/data', (req, res) => {
res.json(data);
});
app.listen(3000, () => {
console.log('start server on 3000;');
});
这里的 ./data.json 你可以放置任何一段 json 内容。同时,我们还需要在 public 下放置一个 html 文件从来承接页面的展示以及执行客户端的逻辑:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="root"></div>
<script src="./index.js"></script>
</body>
</html>
// index.js
setTimeout(() => {
fetchUserDataByStreaming();
}, 100);
async function fetchUserDataByStreaming() {
const response = await fetch('/api/data', {
method: 'post'
});
const body = response.body;
// 获取可读流对象读取器
const reader = body.getReader();
// 创建 TextDecoder 解码
const textReader = new TextDecoder();
function getValueFromReader() {
reader.read().then((res) => {
if (res.done) {
console.log('reader done');
return;
}
if (res.value) {
const text = textReader.decode(res.value);
const element = document.getElementById('root');
element.innerHTML = element.innerHTML + text;
console.log(textReader.decode(res.value));
// 未结束时,继续调用 getValueFromReader 递归读取 fetch 内容
getValueFromReader();
}
});
}
getValueFromReader();
}
上边的逻辑中,我们在通过 Express 创建了一个 NodeServer,同时创建了一个 /api/data 的 post 接口。
启动应用后访问 localhost:3000 后会加载 html 文件,同时执行 ./index.js 中的客户端逻辑。
客户端会在 100ms 后调用 fetchUserDataByStreaming 方法。
fetchUserDataByStreaming 主要有以下几个步骤:
- 首先使用 Fetch Api 调用 NodeServer 的
/api/data接口。 - 当
/api/data响应时(HTTP Status Code 为 200 时),我们会使用response.body获取本次响应内容的可读流。 - 之后,我们通过 body.getReader 以及 new TextDecoder 获取了响应可读流对象的读取器和解码器。
- 最后,在 fetchUserDataByStreaming 中我们递归调用 getValueFromReader 来将响应返回的数据更新到页面上。
getReader() 方法会创建一个 reader,并将 Stream 锁定。只有当前 reader 将流释放后,其他 reader 才能使用。同时,getReader() 方法的返回值和生成器函数返回的用法一模一样。
- ReadableStream 中如果有 chuck 可用,调用 reader.read() 返回的 promise 会使用
{ value: chunk, done: false }done 表示 stream 未结束,而 value 则是本次读取的内容。 - ReadableStream 如果已经结束(关闭),调用 reader.read() 返回的 promise 会使用
{ value: undefined, done: true },自然 done 表示可读取已经关闭。
这里,我们直接使用 res.body 将返回的数据无脑通过 innerHTML 添加到页面中。

上图为将 network 调整为 slow 3g 情况下的 performance frames。
细心的同学可能已经发现不一样了,和以往的 XMLHTTPRequest 的等待接口内容全部下载完成后才可以获取数据不同。
Fetch Api 的 Response.body 返回的 readableStream 为我们提供了可以分步获取数据而无需等待所有的内容下载完成。
结合 Freames 来看,页面上的内容是一部分一部分进行渲染完成而非是一屏内直接将内容进行粗暴的替换。
在细心一些的同学们可能还是会发现,返回的页面上零散的多了许多乱码的文字:
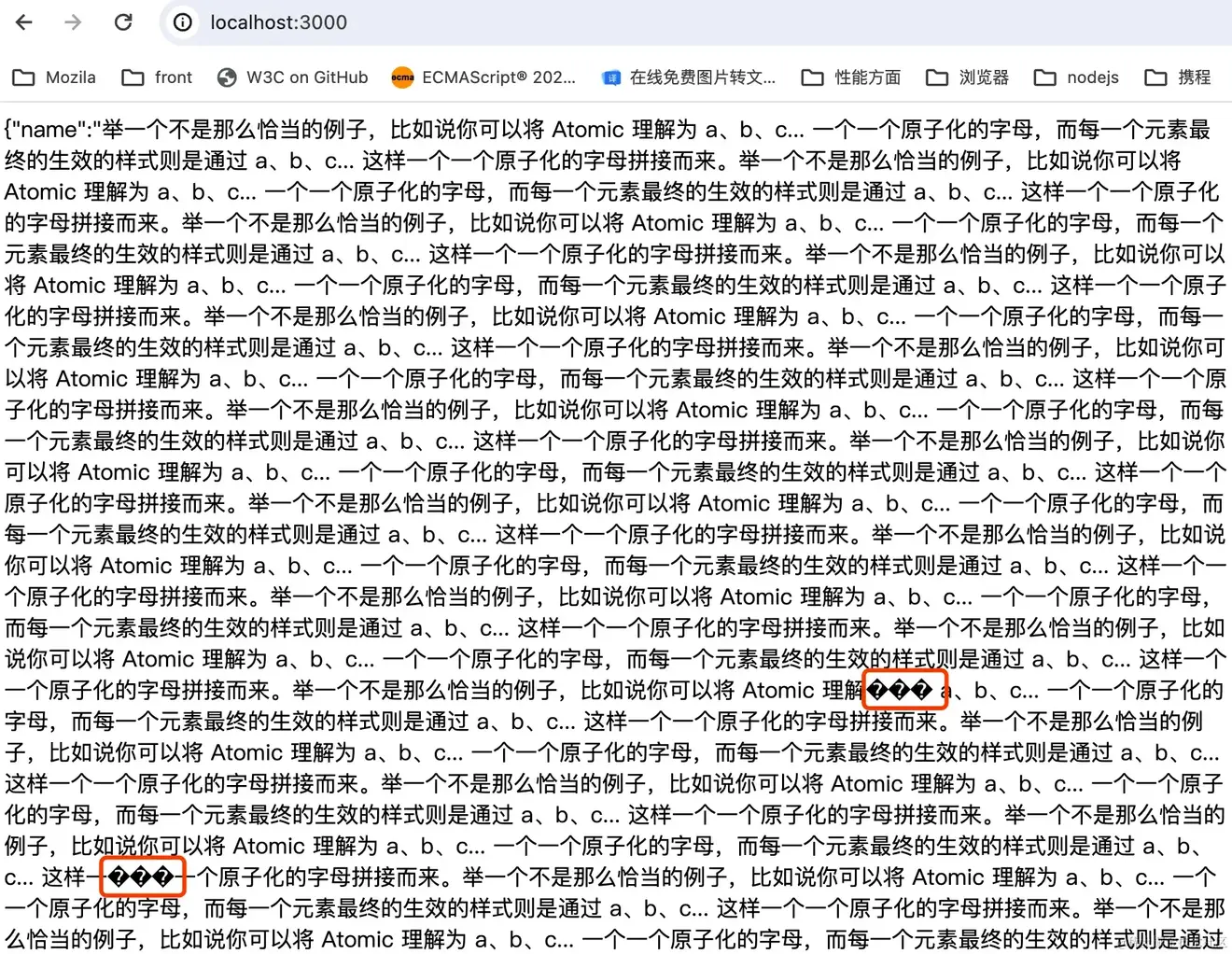
实际上这是因为默认情况下 TextDecoder 是按照 utf-8 编码(一个字节代表 8 个 bit)格式去解析 Response.body。
在 ReadableStream 中会按照最小单位为字节来分割数据,调用 body.getReader() 返回的 res.value 为 Uint8Array 类型,Uint8Array 中是一个由 8 位无符号整数(即一个字节)组成的数组。
页面为纯英文情况下(utf-8 编码下一个英文为一个字节)自然可以直接通过 TextDecoder 直接读取不会有任何乱码。
但是在中文场景下,通常在 UTF-8 下一个中文会占用 3 个字节,粗暴的使用 TextDecoder 去解码返回的 Uint8Array 可能会造成将一个中文字符的多字节被部分截断,uft-8 编码无法识别部分的中文字节,自然也会产生乱码。
要解决这个问题,我们需要了解 utf-8 编码下对于不同文字的解析规则:
简单来说 utf-8 是一种变长字节编码方式。
- 对于某一个字符的 utf-8 编码,如果只有一个字节则其最高二进制位为 0。
- 如果是多字节,其第一个字节从最高位开始,连续的二进制位值为 1 的个数决定了其编码的位数,其余各字节均以 10 开头,当然 utf-8 最多可用到 6 个字节。
字节 | 示例 |
1字节 | 0xxxxxxx |
2字节 | 110xxxxx 10xxxxxx |
3字节 | 1110xxxx 10xxxxxx 10xxxxxx |
4字节 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
5字节 | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
6字节 | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
这样就意味着在每次读取 stream 中我们需要根据 Uint8Array 的尾部自己往前判断尾部字节是否可以组成一个完整的 utf-8 编码,如果可以那么我们调用 TextDecoder 进行解码,如果不可以我们需要在本次的 stream 中舍弃不完整的字节再进行解码防止浏览器乱码。
简单来说我们可以根据 uft-8 的编码规则,将 Uint8Array 类型转化为二进制从而判断尾部字节是否满足单个字符。
setTimeout(() => {
fetchUserDataByStreaming();
}, 100);
async function fetchUserDataByStreaming() {
const response = await fetch('/api/data', {
method: 'post'
});
const body = response.body;
// 获取可读流对象
const reader = body.getReader();
// 创建 TextDecoder 解码
const textReader = new TextDecoder();
// 创建一个本次响应的全局 buffer 用于保存已经收到的数据
// 类型为 Uint8Array[]
let buffer = [];
function getValueFromReader() {
reader.read().then((res) => {
if (res.done) {
console.log('reader done');
return;
}
if (res.value) {
const chunk = res.value;
// 将本次返回数据添加到已返回数据中
buffer.push(chunk);
// 格式化已返回的 Uint8Array[] 获得完整的数据
const completeBuffer = mergeArrays(...buffer);
// 判断是否需要舍弃乱码字节,获得本次可完整解码的数据
const finallyBuffer = splitValidBuffer(completeBuffer);
// 解码
const textBufferString = textReader.decode(finallyBuffer);
const element = document.getElementById('root');
// 全量进行替换
element.innerHTML = textBufferString;
// 未结束时,继续调用 getValueFromReader 递归读取 fetch 内容
getValueFromReader();
}
});
}
getValueFromReader();
}
function splitValidBuffer(buffer) {
const reg = /^1*/;
let count = 0;
let shouldCount = 0;
for (let i = buffer.length - 1; i >= 0; i--) {
const byte = buffer[i];
// 将字节转化为二进制
const value = byte.toString(2).padStart(8, '0');
// 判断本字节是否为部分
if (!`${value}`.startsWith('10')) {
// 不为部分
shouldCount = `${value}`.match(reg)[0].length;
break;
} else {
// 开头字节
count++;
}
}
if (shouldCount === count) {
return buffer;
} else {
return buffer.slice(0, buffer.length - (count + 1));
}
}
function mergeArrays(...arrays) {
let out = new Uint8Array(
arrays.reduce((total, arr) => total + arr.length, 0)
);
let offset = 0;
for (let arr of arrays) {
out.set(arr, offset);
offset += arr.length;
}
return out;
}
上述的代码中我们在 Fetch Response 返回后创建一个数组来保存所有返回的 buffer 内容,然后在每次 reader.read() 方法中调用 decode 将从 response.body 已获得的全部内容进行 decode。
同时,我们在每次进行 decode 方法时对于尾部字节进行了有效性判断,去掉了会造成乱码的不完整字节。
这样就可以保证最终返回数据的连贯性从而解决最终数据的乱码问题。
此时,重新查看页面每一帧,页面上的已经乱码文字已经消失了:

文章中的代码你可以在这里看到。
将 res.body 进行数据分片渲染
当然,往往在传统的应用程序中后台返回给前端的数据是具有一定格式含义的数据。所以,简单的通过 res.body 来获取分段数据显示是无法满足大多数数据格式的业务场景的。
一个简单的例子,通常我们会在客户端和服务端约定。返回的数据会存放在顶级 data 下,同时具有一个 error 的顶级属性表示是否存在错误,于是返回的数据格式可能就会发生变化:
{
"data": "real response Data",
"error": null,
}
面对这部分格式,我们并不能无脑将 fetch response 的 readableStream 通过上边的方式无脑读取塞入。
同时,一个场景的业务场景:服务端返回的真实数据为一个数组类型的格式,前端页面需要根据数据中每一个元素来进行一个元素的渲染,比如:
{
"data": [
{
"title": "title1",
"desc": "desc"
},
{
"title": "title2",
"desc": "desc2"
},
{
"title": "title3",
"desc": "desc3"
}
],
"error": null
}
上面数据格式中 data 数组的每一项我们可能需要在页面上渲染为一个 Card,自然无脑通过 TextDecoder rea 方法获取数据是一种错误的方式。
要满足上述的业务场景,如果我们一股脑的将 ResponseBody 进行分批读取返回给客户端实际上是错误的方式。
一个比较粗暴的方式是我们使用 TextEncoder/TextDecoder 对于返回的 json 数据格式按照特定的规则进行粗暴的截取。
通过将 stream 中返回的字节转化为 json 字符串截取部分内容的方式的确是可以满足我们的需求,但是实际并不具备任何通用性。
我们可以尝试另一种更加具有通用性的方式:
- 在每次服务端(NodeServer)返回响应时,我们可以在客户端通过特殊的请求/响应头来判断本次返回的数据。
如果本次请求携带特殊的请求头,那么服务端会返回前后端约定的特殊结构的数据。如果本次请求未携带特殊的请求头,自然返回通用的 appliction/json 格式即可。
比如,同样是上述的数据。我们可以将它返回为一个非 JSON 的数据格式,比如我们可以将上面的数据在服务端处理成为:
"error": null
"data": [
{
"title": "title1",
"desc": "desc"
},
{
"title": "title2",
"desc": "desc2"
},
{
"title": "title3",
"desc": "desc3"
}
]
在服务端可以通过简单的 \n (个数)规则和客户端约定如何解析这份数据结构。- 之后,在客户端进行数据处理时根据约定的 ResponseHeader 来识别这份数据格式,从而在读取 ReadableStream 时按照前后端一致的标准去分割即可满足特定数据格式的约定。
这样的实现方式虽然听上去稍微有些天马行空,实际上社区内已经有部分成熟开源框架已经用这种方式大大提升了页面的数据响应速度。
比如在 Remix 中的 Defer 正是按照这种思路实现的 SPA 模式跳转下的 LoaderData 数据获取,从而大幅度缩小了页面的响应速度。
不过这种实现思路需要服务端同学配合一起进行更改,有兴趣的同学可以自行按照这种思路进行尝试,这里我就不在文章中进行演示了。
我会在后续的文章中详细介绍 Remix 是如何使用 fetch 来实现页面跳转速度优化的,有兴趣的小伙伴可以关注后续的文章。
当然,你也可以自行阅读 Remix readStreamSections 方法。
Fetch Steam & Content download
往往在 XMLHttpRequest 中,对于 Content download 前端同学很少有办法去有效缩短这部分时间。
而 WebFetch Api 的出现配合 chunk 的网络传输方式,为我们的 Web 应用在网络请求上 Content download 优化提供了一种更为有效的方式可以分批次的给予用户反馈。
当然除了弱网情况下的 Content download 优化空间,Fetch Api 还在其他地方为我们带来了更多可能。
如果整个后台的数据都可以切换为 streaming 的方式(类似于大文件传输),那么理论上你的应用站点都可以使用 Web Fetch 来优化接口响应带来的展示延迟 Any data request does not need to wait for the interface to fully respond before it can be displayed !。
结尾
文章中从一个角度来为大家讲述 Web 性能优化,希望可以帮助到大家。
尽管文章提到的观点相对激进,但总体而言,Web Stream 的方式确实为我们的页面提供了一种快速响应数据的可能性。