基于经验累积分布的离群值检测(ECOD)是一种直观的方法,通过测量罕见事件在分布中的位置来识别异常值。
ECOD首先以非参数方式估计变量的分布,然后将所有维度的估计尾部概率相乘,得出观测值的异常得分。ECOD假设变量独立,并且可以估算出每个变量的经验累积分布。虽然变量独立的假设可能过于严格,但这并不是新的假设,因为前一章中的HBOS也做了同样的假设,并且已被证明是有效的。
ECOD 的优势是什么?
ECOD 作者证实了它优于其他流行的基线检测方法。由于 ECOD 无需调整超参数,因此在处理大量数据时速度很快。在一台标准的个人笔记本电脑上处理一个包含一百万个观测值和一万个特征的大型数据集只需要大约两个小时。
另一个 ECOD 的优点是易于解释。您可以通过它检查多个尾部概率对最终离群值的影响。
ECOD 如何工作?
许多读者熟悉参数分布,但不熟悉非参数分布。我将介绍什么是参数分布和非参数分布,并谈谈非参数分布的形成。然后,我将介绍 ECOD 算法,然后比较 ECOD 和 HBOS。
理解经验累积分布函数
为了解释 "非参数 "和 "参数 "这两个术语,我们需要澄清几个相关术语 "群体"、"样本 "和 "估计值"。统计学的目标是了解我们感兴趣的 "总体"。均值、标准差和比例等量被称为描述总体的 "参数"。通常无法获得整个群体的所有数据,因此无法计算描述群体的参数。一个实用的解决方案是收集随机 "样本 "来描述总体。通过样本的分布,我们可以 "估计 "出描述总体分布的参数。
非参数方法假设不对群体分布的形状和参数做任何假设,而是根据样本经验进行估计。相比之下,参数方法则对基本人口的分布形状做出假设,如正态分布。
让我来演示一下非参数方法,并根据经验估计一个分布。我任意汇总了三个伽马分布和一个正态分布来生成一个不遵循任何特定形状的分布(见图1)。右尾部存在一些极端值。
| # Create a distribution that is the combination of three other distributions | |
| from matplotlib import pyplot | |
| from numpy.random import normal, gamma | |
| from numpy import hstack | |
| shape, scale = 10, 2. | |
| s1 = gamma(shape, scale, 1000) | |
| s2 = gamma(shape * 2, scale * 2, 1000) | |
| s3 = normal(loc=0, scale=5, size=1000) | |
| sample = hstack((s1, s2, s3)) | |
| # plot the histogram | |
| pyplot.hist(sample, bins=50) | |
| pyplot.show() |

图(10)数据分布
为了根据经验估计分布情况,我使用 Python statmodels 模块中的 ECDF()来推导累积分布函数 (CDF),如图 (2) 所示。
| # fit a cdf | |
| from statsmodels.distributions.empirical_distribution import ECDF | |
| sample_ecdf = ECDF(sample) | |
| # plot the cdf | |
| pyplot.plot(sample_ecdf.x, sample_ecdf.y) | |
| pyplot.show() |
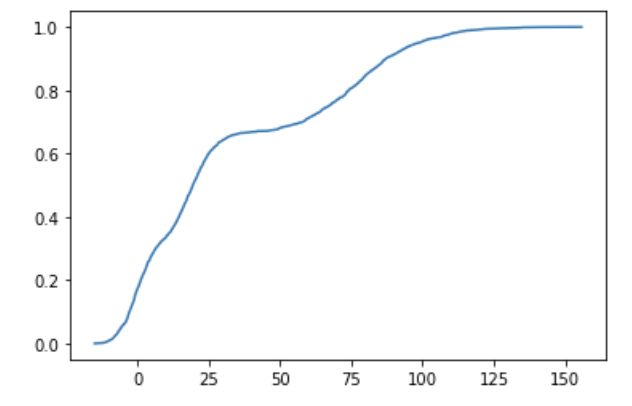
图(2)经验累积分布函数 (ECDF)
在图 (2) 中,我选择了一些位置来显示累积概率,例如,X<0 的累积概率为 0.173,X<125 的累积概率为 0.9967。或者我们可以简单地说 "0 "位于 17.3 百分位数,而 "125 "位于 99.67 百分位数。CDF 接近 1.0 的位置意味着该点接近极值,这一特性有助于我们找到极值。
| print('P(x<-20): %.4f' % sample_ecdf(-20)) | |
| print('P(x<-2): %.4f' % sample_ecdf(-2)) | |
| print('P(x<0): %.4f' % sample_ecdf(0)) | |
| print('P(x<25): %.4f' % sample_ecdf(25)) | |
| print('P(x<50): %.4f' % sample_ecdf(50)) | |
| print('P(x<75): %.4f' % sample_ecdf(75)) | |
| print('P(x<100): %.4f' % sample_ecdf(100)) | |
| print('P(x<125): %.4f' % sample_ecdf(125)) | |
| print('P(x<140): %.4f' % sample_ecdf(140)) | |
| print('P(x<150): %.4f' % sample_ecdf(150)) | |
| P(x<-20): 0.0000 | |
| P(x<-2): 0.1190 | |
| P(x<0): 0.1723 | |
| P(x<25): 0.6000 | |
| P(x<50): 0.6810 | |
| P(x<75): 0.8067 | |
| P(x<100): 0.9540 | |
| P(x<125): 0.9943 | |
| P(x<140): 0.9993 | |
| P(x<150): 0.9997 |
由于 CDF 衡量的是变量的 "离群值",因此可以将其发展为变量的单变量离群值。
ECOD 算法
多维数据,或称为多元数据,指的是每个观测值包含多个值。有时观测值在某些维度上可能具有极端值,而在其他维度上则是正常值。ECOD会将单变量离群值分数综合起来,形成一个观测值的综合离群值分数。
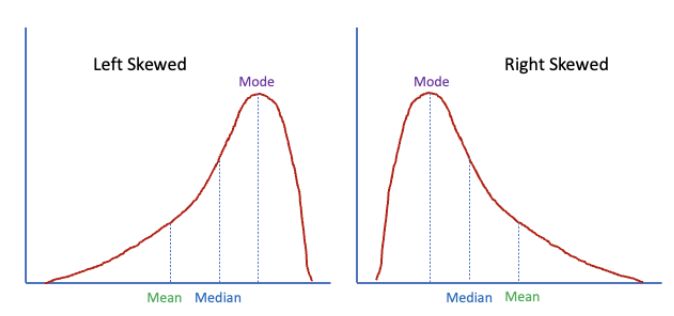
图(3)左偏和右偏分布
在汇总离群值的单变量得分时,出现了一个小的技术难题-维度的分布可能是左斜或右斜,如图(3)所示。假设离群值总是位于分布的左侧或右侧是不合理的。我们首先需要判断一个分布是左偏态还是右偏态。在左偏态分布中,平均值小于其模式,而在右偏态分布中,平均值大于其模式。ECOD 使用分布的倾斜度来分配维度的离群值,如果是右偏分布,离群值就是CDF;如果是左偏分布,离群值就是1减CDF或1-CDF。ECOD 然后将所有维度的单变量离群点得分汇总,得到观测值的总体离群点得分。
ECOD 与 HBOS 的比较
前面介绍的HBOS和本文中的ECOD概念非常相似,都是无监督学习方法,假定变量独立并得出变量的分布。HBOS利用直方图,而ECOD则利用经验得出变量的累积分布。这两种方法都无需调整超参数,同时都是基于分布的算法。基于分布的方法通常速度较快,因此在建模项目中建议首先考虑使用这两种方法。
建模流程
本文提出了异常检测的步骤 1、2、3 建模流程,包括模型开发、阈值确定和特征评估。在步骤 1 中建立模型并分配离群值后,步骤 2 建议绘制离群值直方图以选择阈值。如果直方图中没有自然的切点,通常需要修改特征,因为特征不能有效区分离群值。
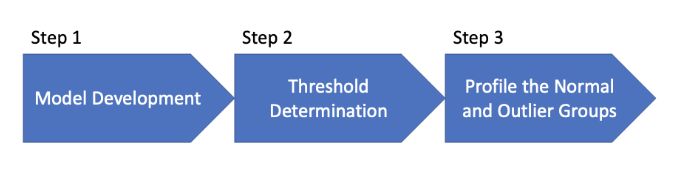
图(4)建模流程
步骤 1 - 建立模型
数据准备
我创建了一个包含 500 个观测值和 6 个变量的模拟数据集,其中异常值的百分比设定为 5%。同时,我还设立了一个目标变量 Y 作为基本事实,但无监督模型只使用 X 变量,Y 变量只是用于验证。
| import numpy as np | |
| import pandas as pd | |
| import matplotlib.pyplot as plt | |
| from pyod.utils.data import generate_data | |
| contamination = 0.05 # percentage of outliers | |
| n_train = 500 # number of training points | |
| n_test = 500 # number of testing points | |
| n_features = 6 # number of features | |
| X_train, X_test, y_train, y_test = generate_data( | |
| n_train=n_train, | |
| n_test=n_test, | |
| n_features= n_features, | |
| contamination=contamination, | |
| random_state=123) | |
| X_train_pd = pd.DataFrame(X_train) | |
| X_train_pd.head() |

把前两个变量绘制成散点图,如图(5)所示。黄色点为异常值,紫色点为正常数据点。
| # Plot | |
| plt.scatter(X_train_pd[0], X_train_pd[1], c=y_train, alpha=0.8) | |
| plt.title('Scatter plot') | |
| plt.xlabel('x0') | |
| plt.ylabel('x1') | |
| plt.show() |

图(5)散点图
训练模型
下面拟合模型,然后使用函数 decision_functions() 生成训练数据和测试数据的离群值。
| from pyod.models.ecod import ECOD | |
| ecod = ECOD(contamination=0.05) | |
| ecod.fit(X_train) | |
| # Training data | |
| y_train_scores = ecod.decision_function(X_train) | |
| y_train_pred = ecod.predict(X_train) | |
| # Test data | |
| y_test_scores = ecod.decision_function(X_test) | |
| y_test_pred = ecod.predict(X_test) # outlier labels (0 or 1) | |
| def count_stat(vector): | |
| # Because it is '0' and '1', we can run a count statistic. | |
| unique, counts = np.unique(vector, return_counts=True) | |
| return dict(zip(unique, counts)) | |
| print("The training data:", count_stat(y_train_pred)) | |
| print("The training data:", count_stat(y_test_pred)) | |
| # Threshold for the defined comtanimation rate | |
| print("The threshold for the defined comtanimation rate:" , ecod.threshold_) | |
| The training data: {0: 450, 1: 50} | |
| The training data: {0: 444, 1: 56} | |
| The threshold for the defined comtanimation rate: | |
| 12.75035460032711 |
- 使用参数
contamination=0.05可以设定异常值的百分比为 5%。这个污染参数不会对离群值分数的计算产生影响。 - PyOD会利用给定的污染率来确定离群值的阈值,并使用函数
predict()来分配标签(1 或 0)。 - 我已经在下面的代码中编写了一个简短的函数
count_stat()来展示预测值 "1" 和 "0" 的计数。 - 语法
.threshold_用于显示指定污染率的阈值。任何高于这个阈值的离群值都会被视为离群值
解释观测值的离群值
由于 ECOD 离群点得分是单变量得分的总和,因此我们可以将单变量得分可视化,以了解离群点得分高的原因。这种对单个预测的可解释性在机器学习中非常重要。
| np.where(y_train_scores>22) | |
| (array([475, 477, 478, 479, 480, 483, 484, | |
| 486, 488, 489, 490, 492, 494, | |
| 495, 496, 497, 498, 499]),) |
ECOD的特殊功能explain_outlier()用于解释单变量的离群值。图(C.1)中的左右两幅图显示了两个观测值的单变量离群值得分,x轴表示维度,y轴表示单变量离群值得分。蓝色和橙色虚线分别表示离群值的95%和99%百分位数。左图显示,除了变量1外,单变量离群点得分均在95%临界区间附近;而右图显示,单变量离群点得分均高于95%临界区间。ECOD的离群分数可解释性是一个合理属性。
| ecod.explain_outlier(475) | |
| ecod.explain_outlier(477) |

图(6) ECOD 解释异常值
步骤 2 - 确定合理的阈值
ECOD的特殊功能explain_outlier()用于解释单变量的离群值。图(C.1)中的左右两幅图显示了两个观测值的单变量离群值得分,x轴表示维度,y轴表示单变量离群值得分。蓝色和橙色虚线分别表示离群值的95%和99%百分位数。左图显示,除了变量1外,单变量离群点得分均在95%临界区间附近;而右图显示,单变量离群点得分均高于95%临界区间。ECOD的离群分数可解释性是一个合理属性。
| import matplotlib.pyplot as plt | |
| plt.hist(y_train_scores, bins='auto') # arguments are passed to np.histogram | |
| plt.title("Outlier score") | |
| plt.show() |
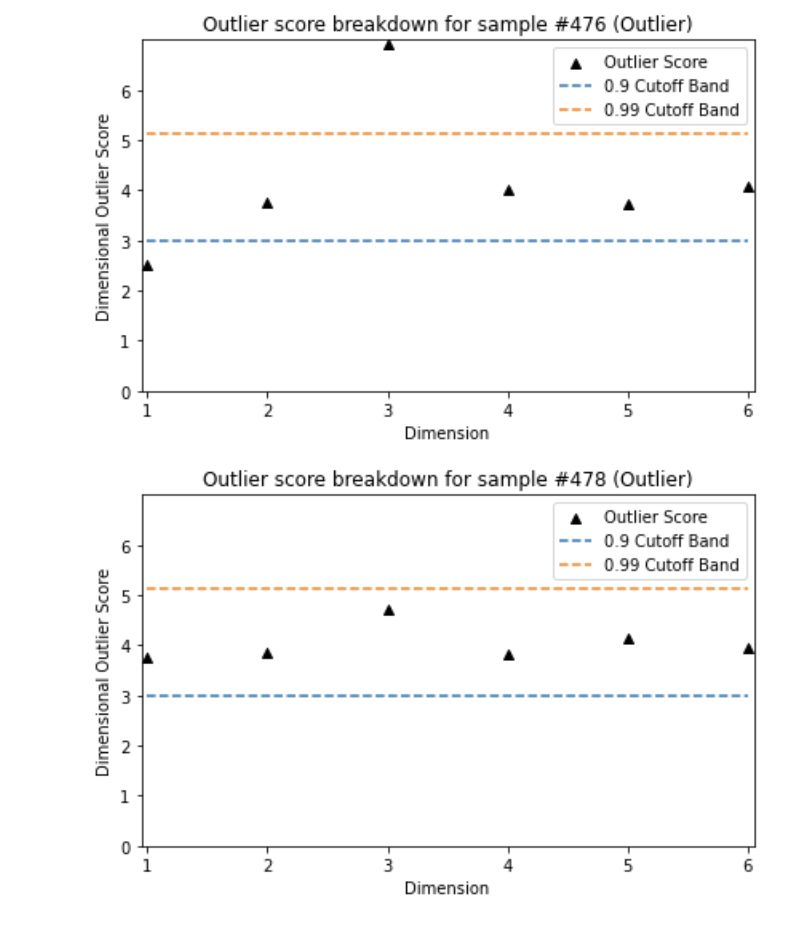
图(C.2):ECOD 离群值直方图
步骤 3--展示正常组和异常组的描述性统计
如第 1 章所述,两组之间特征的描述性统计(如均值和标准差)对于证明模型的合理性非常重要。我创建了一个简短的函数 "descriptive_stat_threshold() "来显示基于阈值的正常组和异常组特征的大小和描述性统计。下面我简单地将阈值设为 5%。您可以测试一系列阈值,以确定离群值组的合理大小。
| threshold = ecod.threshold_ # Or other value from the above histogram | |
| def descriptive_stat_threshold(df,pred_score, threshold): | |
| # Let's see how many '0's and '1's. | |
| df = pd.DataFrame(df) | |
| df['Anomaly_Score'] = pred_score | |
| df['Group'] = np.where(df['Anomaly_Score']< threshold, 'Normal', 'Outlier') | |
| # Now let's show the summary statistics: | |
| cnt = df.groupby('Group')['Anomaly_Score'].count().reset_index().rename(columns={'Anomaly_Score':'Count'}) | |
| cnt['Count %'] = (cnt['Count'] / cnt['Count'].sum()) * 100 # The count and count % | |
| stat = df.groupby('Group').mean().round(2).reset_index() # The avg. | |
| stat = cnt.merge(stat, left_on='Group',right_on='Group') # Put the count and the avg. together | |
| return (stat) | |
| descriptive_stat_threshold(X_train,y_train_scores, threshold) |

表格显示了正常组和异常组的特征计数和百分比。异常分数是平均异常分数。重要的结果包括... 提醒用特征名称标注特征以有效展示。
- 异常值组的大小约为 5%,由阈值确定。阈值越大,异常值越少。
- 异常值组的平均异常值远高于正常组(22.86 > 9.40),不需要过多解释HBO分数。
- 从上表可见,离群组特征的均值小于正常组。离群组中特征的均值与业务应用有关,需与领域知识保持一致。
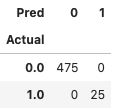
因为数据生成中包含了 "y_test" 这一基本事实,所以我们可以利用混淆矩阵来评估模型的性能。该模型能够准确识别所有 25 个异常值。
| def confusion_matrix(actual,pred): | |
| Actual_pred = pd.DataFrame({'Actual': actual, 'Pred': pred}) | |
| cm = pd.crosstab(Actual_pred['Actual'],Actual_pred['Pred']) | |
| return (cm) | |
| confusion_matrix(y_train,y_train_pred) |
通过多种模型识别异常值
我们已学习了HBOS和ECOD两种模型。如果一个离群值被多个模型识别出来,那么它是离群值的几率就会大大提高。在本节中,我将对两个模型的预测结果进行交叉分析,以识别离群值。首先我将复制HBOS和ECOD模型并生成它们的临界值。
| ######## | |
| # HBOS # | |
| ######## | |
| from pyod.models.hbos import HBOS | |
| n_bins = 50 | |
| hbos = HBOS(n_bins=n_bins, contamination=0.05) | |
| hbos.fit(X_train) | |
| y_train_hbos_pred = hbos.labels_ | |
| y_test_hbos_pred = hbos.predict(X_test) | |
| y_train_hbos_scores = hbos.decision_function(X_train) | |
| y_test_hbos_scores = hbos.decision_function(X_test) | |
| ######## | |
| # ECOD # | |
| ######## | |
| from pyod.models.ecod import ECOD | |
| clf_name = 'ECOD' | |
| ecod = ECOD(contamination=0.05) | |
| ecod.fit(X_train) | |
| y_train_ecod_pred = ecod.labels_ | |
| y_test_ecod_pred = ecod.predict(X_test) | |
| y_train_ecod_scores = ecod.decision_scores_ # raw outlier scores | |
| y_test_ecod_scores = ecod.decision_function(X_test) | |
| # Thresholds | |
| [ecod.threshold_, hbos.threshold_] | |
| [16.320821760780653, 5.563712646460526] |
我将实际的Y值和HBOS以及ECOD预测的"1"和"0"值放在一个数据框中。在对HBOS和ECOD预测值进行交叉分析时,发现两个模型都发现有26个异常值。ECOD和HBOS的结果一致。
| # Put the actual, the HBO score and the ECOD score together | |
| Actual_pred = pd.DataFrame({'Actual': y_test, 'HBOS_pred': y_test_hbos_pred, 'ECOD_pred': y_test_ecod_pred}) | |
| Actual_pred.head() | |
| pd.crosstab(Actual_pred['HBOS_pred'],Actual_pred['ECOD_pred']) |

HBOS 算法总结
- 如果一个观测值在大多数变量中都达到离群值水平,那么很可能该观测值也是离群值。
- HBOS根据直方图来定义每个变量的离群值,然后将所有变量的离群值相加,得到观测值的多元离群值。
- HBOS作为一种高效的无监督异常点检测方法,因为直方图易于构建。