🚀一.字符串基础

在Python中,字符串(str)可以被定义为一系列字符 (characters),这些字符可以是字母、数字或者其他任意字符。例如:
my_string = "Hello World!"
在上面的例子中,我们定义了一个名为 my_string 的字符串。它由 12 个字符组成,其中包括字母、空格和标点符号。请注意,字符串必须用双引号或单引号括起来。
| 字符串特征 |
| ' ' |
| " " |
| """ """ |
| 均为字符串 |
| |
| 例如: |
| |
| name1 = '张三' |
| print(type(name1)) |
| |
| name2 = "张三" |
| print(type(name2)) |
| |
| name3 = """张三""" |
| print(type(name3)) |
| |
| |
| """ """ |
🌈二.查看数据类型
| 可以通过 type函数 查看指定数据类型 |
| |
| type('张三') |
⭐三.转化
在Python中,可以使用 str() 内置函数将其他类型的数据转换为字符串。这个函数接受一个参数并返回一个表示该参数值的字符串。
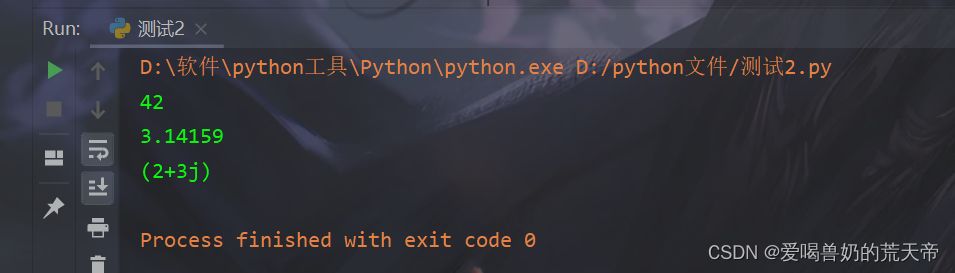
| num = 42 |
| result = str(num) |
| print(result) |
| |
| pi = 3.14159 |
| result = str(pi) |
| print(result) |
| |
| c = complex(2, 3) |
| result = str(c) |
| print(result) |
| |
| |
❤️四.字符串索引
字符串是扁平序列,不可变序列
我们可以使用索引来访问字符串中的特定字符。在Python中,字符串的第一个字符的索引是 0,第二个字符的索引是 1,依此类推。例如:
| my_string = "Hello World!" |
| print(my_string[0]) |
| print(my_string[6]) |
除了正向索引之外,还可以使用负数索引访问序列中的元素。在这种情况下,从右到左计数,最后一个元素的索引为-1,以此类推。例如:
| my_list = [1, 2, 3, 4, 5] |
| print(my_list[-1]) |
| print(my_list[-3]) |
🚲五.字符串切片
在Python中,切片允许我们从序列类型数据中选择一个子集并返回一个新的序列。切片语法由两个索引值和一个可选的步长组成,如下所示:
sequence[start:stop:step] # sequence 序列
其中 start 是切片开始的索引位置(默认为0),stop 是切片结束的索引位置(不包括该位置所在的元素,默认为序列长度),step 是切片中元素之间的步长(默认为1)。
例如,假设我们有以下字符串:
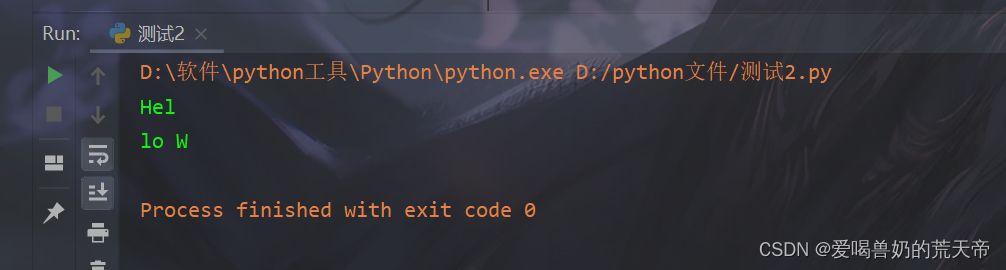
my_string = "Hello World"
要获取 ‘Hel’ 以及 ‘lo W’,我们可以分别使用以下两个切片操作:
| |
| |
| |
| print(my_string[0:3]) |
| |
| |
| print(my_string[3:7]) |
输出结果:
另外,如果要获取字符串的最后三个字符,可以使用负数索引和空的 start 来进行切片操作。例如:
输出结果:
rld
🎬六.字符串切片-步长
在切片中,还可以使用步长来控制返回的元素之间的距离。例如,要从一个列表中获取所有的偶数位置的元素,可以使用步长为2的切片操作。示例代码如下:
| my_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] |
| print(my_list[::2]) |
| |
输出结果:
[0, 2, 4, 6, 8]
在这个例子中,我们使用一个空的 start 和 stop 来表示从头到尾,并使用步长为2来获取所有偶数位置的元素。
☔七.反向切片注意事项
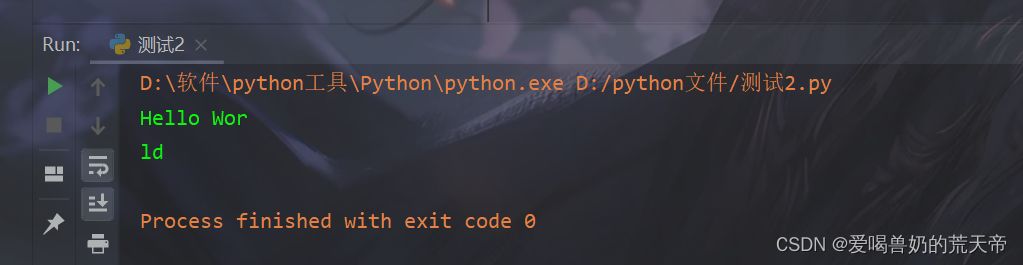
| my_string = "Hello World" |
| |
| |
| |
| |
| result = my_string[:-2] |
| print(result) |
| |
| |
| result = my_string[-2:] |
| print(result) |
接下来的操作注意观察, 观察后理解
| my_string = "Hello World" |
| |
| |
| result0 = my_string[::-1] |
| result1 = my_string[::-2] |
| |
| |
| result2 = my_string[-1:-3:-1] |
| |
| |
| result3 = my_string[-1:2:-1] |
| """ |
| 这里之所以能够成立是因为步长为负数,我们参考将从后往前 |
| 因此 切片方向将从后往前看 |
| """ |
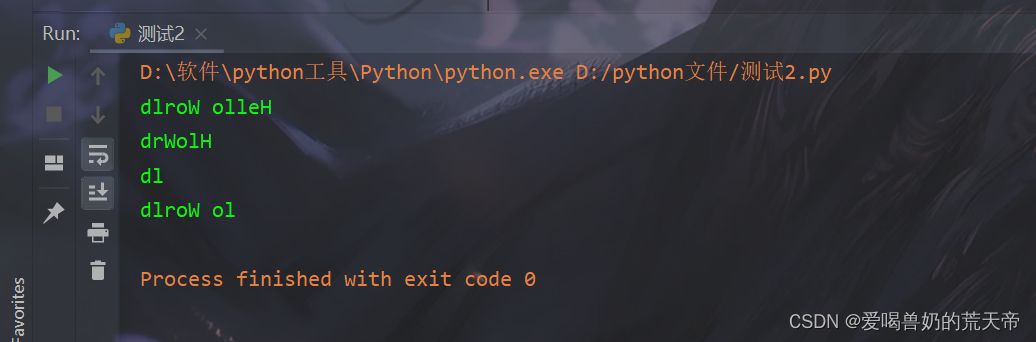

🚲八.字符串
| 字符串中的元素是指字符串中的每个字符,一个字符串是由一系列字符组成的。例如,字符串 "hello, world!" 是由 13 个字符组成的,分别是 'h'、'e'、'l'、'l'、'o'、','、' '、'w'、'o'、'r'、'l'、'd' 和 '!' 。可以使用索引和切片来访问和操作这些字符。在 Python 中,字符串是不可变序列,即它们的元素不能被更改,只能通过复制或拼接等方式来创建新的字符串。 |
| 字符串无法修改原数据 |
💥查
- count:查找指定元素在字符串中出现的次数,可指定范围
| |
| str1 = 'addfbcvfd' |
| print(str1.count('d')) |
- index: 查找指定元素第一次出现的位置下标 - 找不到报错 【可指定范围】
| |
| str2 = 'qwert帅哈yuil哈哈' |
| print(str2.index('哈')) |
| print(str2.index('放')) |
- find: 查找指定元素第一次出现的位置下标 - 找不到返回 (-1) 【可指定范围】
| |
| str2 = 'qwert帅哈yuil哈哈' |
| print(str2.find('哈')) |
| print(str2.find('放')) |
| |
| str3 = '12345' |
| str4 = '12345hasd' |
| str5 = 'drthasd' |
| print(str3.isdigit()) |
| print(str4.isdigit()) |
| print(str5.isdigit()) |
| |
| str3 = '12345' |
| str4 = '12345hasd' |
| str5 = 'drthasd' |
| print(str3.isalpha()) |
| print(str4.isalpha()) |
| print(str5.isalpha()) |
- endswith: 判断字符串结束位置字符是否是指定字符
| |
| str6 = 'axiba' |
| print(str6.endswith('ba')) |
| print(str6.endswith('aa')) |
- startswith: 判断字符串开始位置字符是否是指定字符
| |
| str6 = 'axiba' |
| print(str6.startswith('ax')) |
| print(str6.endswith('aa')) |
- islower: 判断字符串中(英文字符)是否为纯小写
| |
| str7 = 'qqwee哈哈' |
| str8 = 'qQwee哈哈' |
| print(str7.islower()) |
| print(str8.islower()) |
- isupper: 判断字符串中(英文字符)是否为纯大写
| |
| str7 = 'qqwee哈哈' |
| str8 = 'qQwee哈哈' |
| str9 = 'QWERT哈哈' |
| print(str7.isupper()) |
| print(str8.isupper()) |
| print(str9.isupper()) |
注意字符串的不可变性质:无法改变原数据
💥改
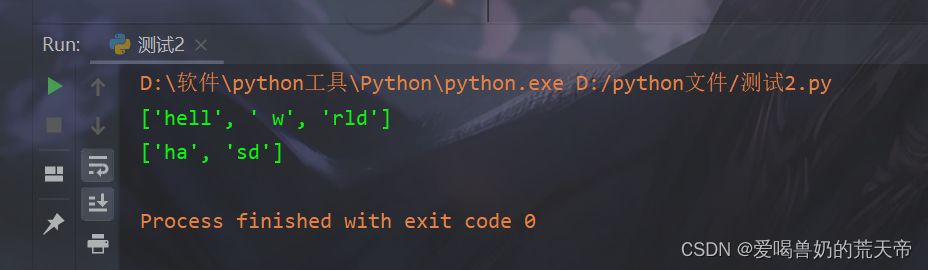
| # split: 切割字符串 |
| str10 = 'hello world' |
| data_1 = str10.split('o') |
| print(data_1) # ['hell', ' w', 'rld'] |
| |
| # 注意: 默认去去空格 |
| str11 = 'ha sd ' |
| data_2 = str11.split() |
| print(data_2) # ['ha', 'sd'] |
| |
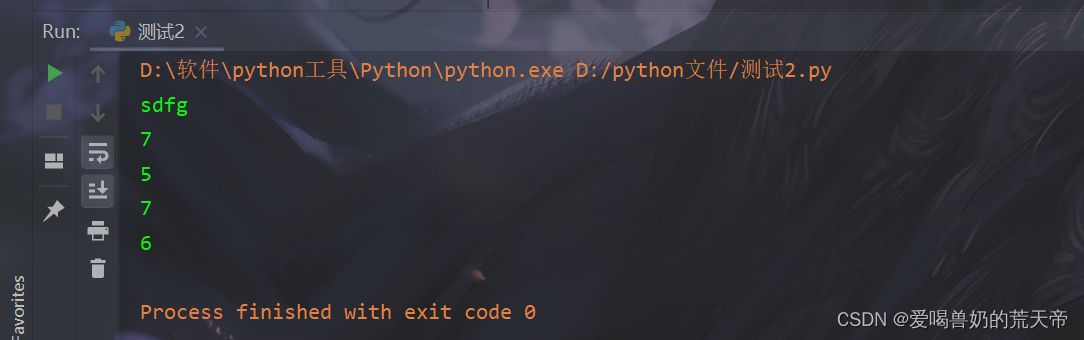
| str12 = ' sdfg ' |
| data_3 = str12.strip() |
| print(data_3) |
| |
| |
| str13 = ' shuai' |
| print(len(str13)) |
| data_4 = str13.lstrip() |
| print(len(data_4)) |
| |
| |
| str14 = 'shushu ' |
| print(len(str14)) |
| data_5 = str14.rstrip() |
| print(len(data_5)) |
| |
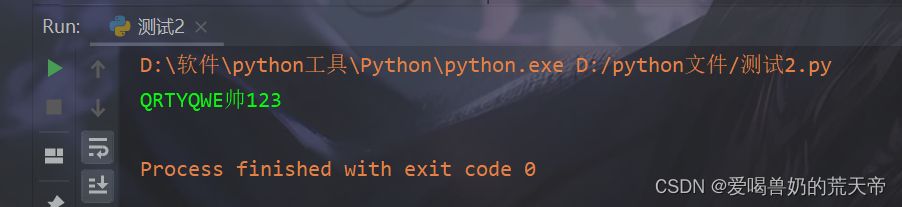
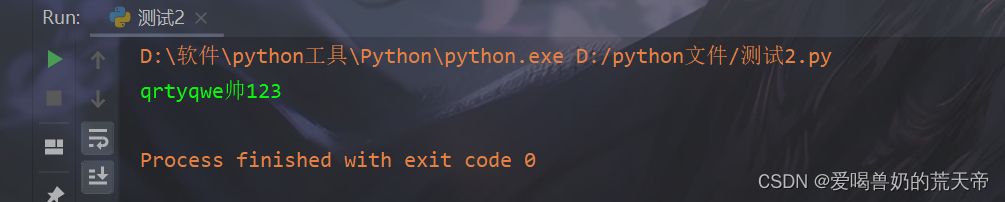
| str15 = 'qrtyQWE帅123' |
| data_6 = str15.upper() |
| print(data_6) |
| |
| str16 = 'qrtyQWE帅123' |
| data_7 = str16.lower() |
| print(data_7) |
| |
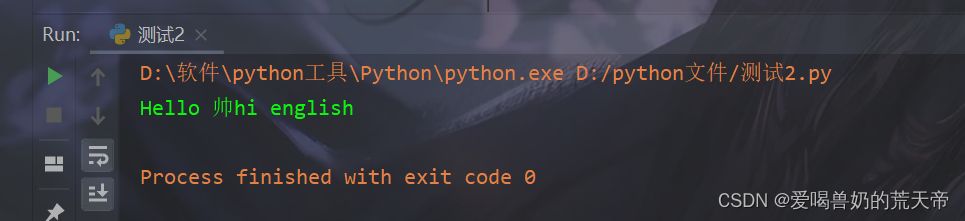
| str17 = 'hello 帅hi english' |
| data_8 = str17.capitalize() |
| print(data_8) |
| |
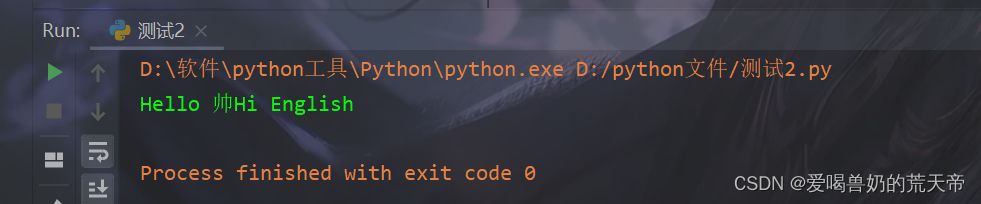
| str18 = 'hello 帅hi english' |
| data_9 = str18.title() |
| print(data_9) |
💥删
| |
| str19 = 'shuju真的很帅哈!学习的快乐 哈哈哈哈' |
| data_10 = str19.replace('哈', '-') |
| print(data_10) |
| |
| |
| |
| str20 = 'shuju真的很帅哈!学习的快乐 哈哈哈哈' |
| data_11 = str20.replace('哈', '-', 2) |
| print(data_11) |
| |
| |
| |
| |
| str21 = 'sh 真的很 帅哈!学习的 快乐 ' |
| data_12 = str21.replace(' ', '') |
| print(data_12) |
- replace(old, new [, count])
- old:被替换的元素
- new:替换成什么
- count:可传可不传,可指定替换次数;默认所有
❤️九.字符串拼接
💥拼接符: +
| str_1 = '你很' |
| str_2 = '帅' |
| splicing = str_1 + str_2 |
| print(splicing) |
💥占位符:%s
| str_3 = '18' |
| |
| placeholder = '%s今年%s岁' % ('小明', str_3) |
| print(placeholder) |
💥join方法
| str_4 = '帅' |
| str_5 = '真的' |
| str_6 = '他' |
| |
| join_merge = '-'.join([str_6, str_5, str_4]) |
| print(join_merge) |
| |
| |
| |
| |
💥format
| str_4 = '帅吗?' |
| str_5 = '真的' |
| str_6 = '他' |
| |
| |
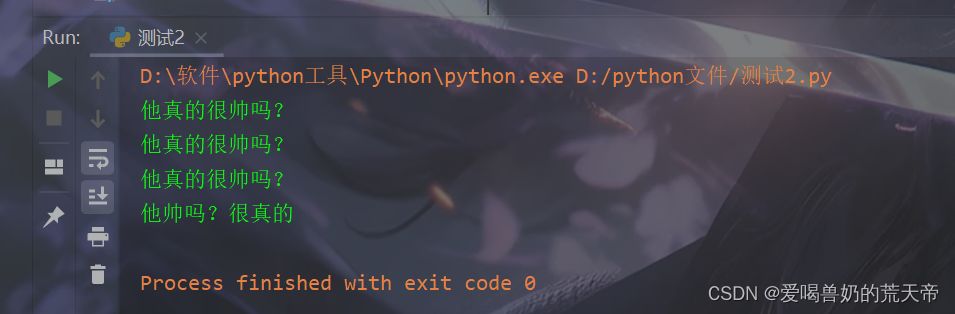
| format_merge_1 = '{}{}很{}'.format(str_6, str_5, str_4) |
| print(format_merge_1) |
| |
| |
| format_merge_2 = '{0}{2}很{1}'.format(str_6, str_4, str_5) |
| print(format_merge_2) |
| |
| |
| format_merge_3 = '{n1}{n3}很{n2}'.format(n1=str_6, n2=str_4, n3=str_5) |
| print(format_merge_3) |
| |
| |
| format_merge_4 = f'{str_6}{str_4}很{str_5}' |
| print(format_merge_4) |
⭐十.字符串格式化
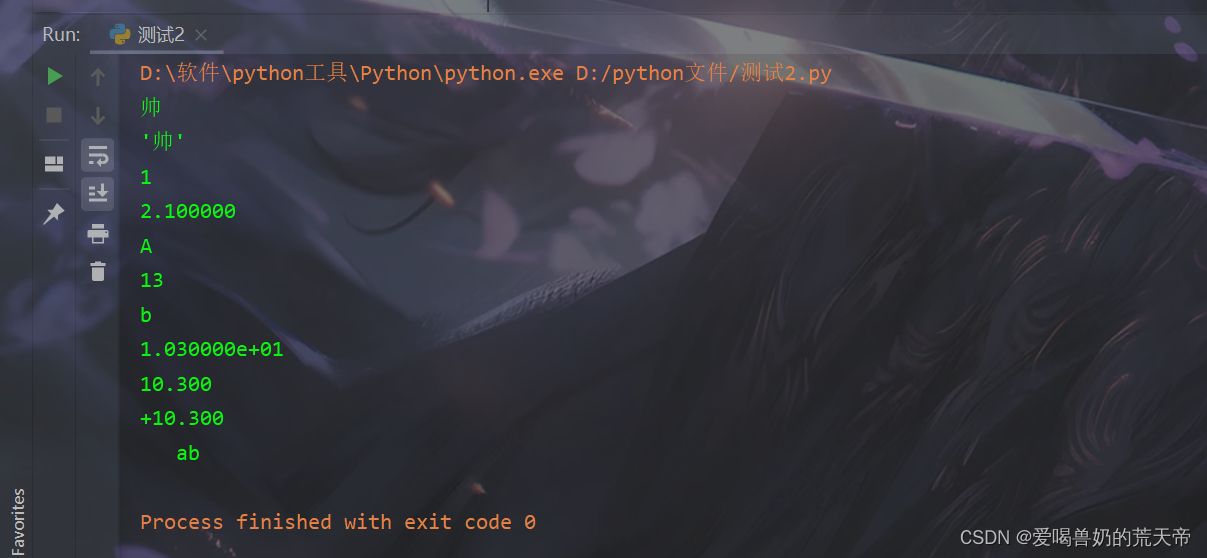
| |
| print('%s' % '帅') |
| |
| |
| print('%r' % '帅') |
| |
| |
| print('%d' % 1) |
| |
| |
| print('%f' % 2.1) |
| |
| |
| print('%c' % 65) |
| |
| |
| print('%o' % 11) |
| |
| |
| print('%x' % 11) |
| |
| |
| print('%e' % 10.3) |
| |
| |
| |
| print('%-6.3f' % 10.3) |
| |
| |
| print('%+6.3f' % 10.3) |
| |
| |
| print('%5s' % 'ab') |
format扩展
| |
| |
| |
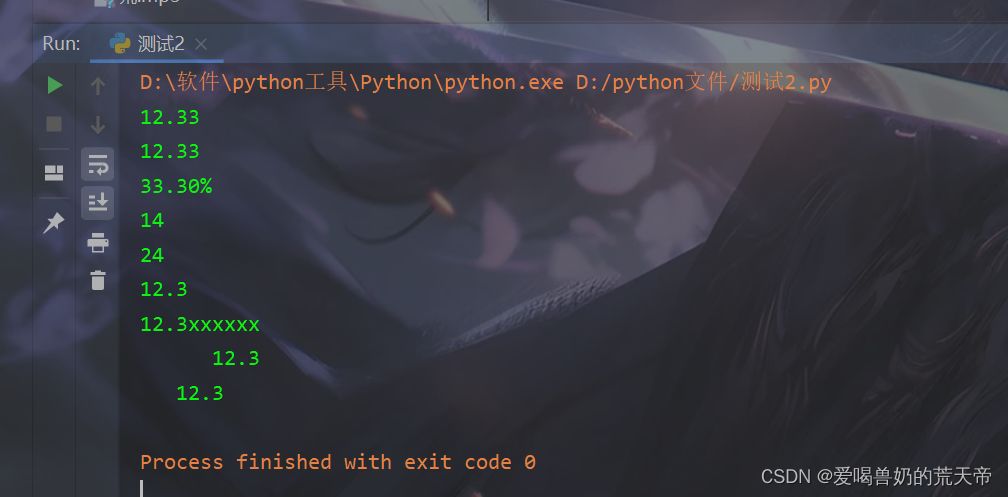
| a1 = '{:.2f}'.format(12.333) |
| print(a1) |
| |
| |
| a2 = '{s:.2f}'.format(s=12.333) |
| |
| print(a2) |
| |
| a3 = '{:.2%}'.format(0.333) |
| print(a3) |
| |
| |
| |
| a4 = '{:x}'.format(20) |
| print(a4) |
| |
| a6 = '{:o}'.format(20) |
| print(a6) |
| |
| |
| |
| a7 = '{a:<10}'.format(a=12.3, b=13.44) |
| print(a7) |
| |
| a8 = '{a:x<10}'.format(a=12.3, b=13.44) |
| print(a8) |
| |
| a9 = '{a:>10}'.format(a=12.3, b=13.44) |
| print(a9) |
| |
| a10 = '{a:^10}'.format(a=12.3, b=13.44) |
| print(a10) |