目录
- 抛砖引玉
- 传统diff算法
- React diff原理
- tree diff
- component diff
- element diff
- 应用实践
- 页面指定区域刷新
- 更加方便地监听props改变
- react-router中Link问题
- 结语
抛砖引玉
React通过引入Virtual DOM的概念,极大地避免无效的Dom操作,已使我们的页面的构建效率提到了极大的提升。但是如何高效地通过对比新旧Virtual DOM来找出真正的Dom变化之处同样也决定着页面的性能,React用其特殊的diff算法解决这个问题。Virtual DOM+React diff的组合极大地保障了React的性能,使其在业界有着不错的性能口碑。diff算法并非React首创,React只是对diff算法做了一个优化,但却是因为这个优化,给React带来了极大的性能提升,不禁让人感叹React创造者们的智慧!接下来我们就探究一下React的diff算法。
传统diff算法
在文章开头我们提到React的diff算法给React带来了极大的性能提升,而之前的React diff算法是在传统diff算法上的优化。下面我们先看一下传统的diff算法是什么样子的。
传统diff算法通过循环递归对节点进行依次对比,效率低下,算法复杂度达到 O(n^3),其中 n 是树中节点的总数。
O(n^3) 到底有多可怕呢?这意味着如果要展示 1000 个节点,就要依次执行上十亿次 的比较,这种指数型的性能消耗对于前端渲染场景来说代价太高了。而React却这个diff算法时间复杂度从O(n3)降到O(n)。O(n3)到O(n)的提升有多大,我们通过一张图来看一下。
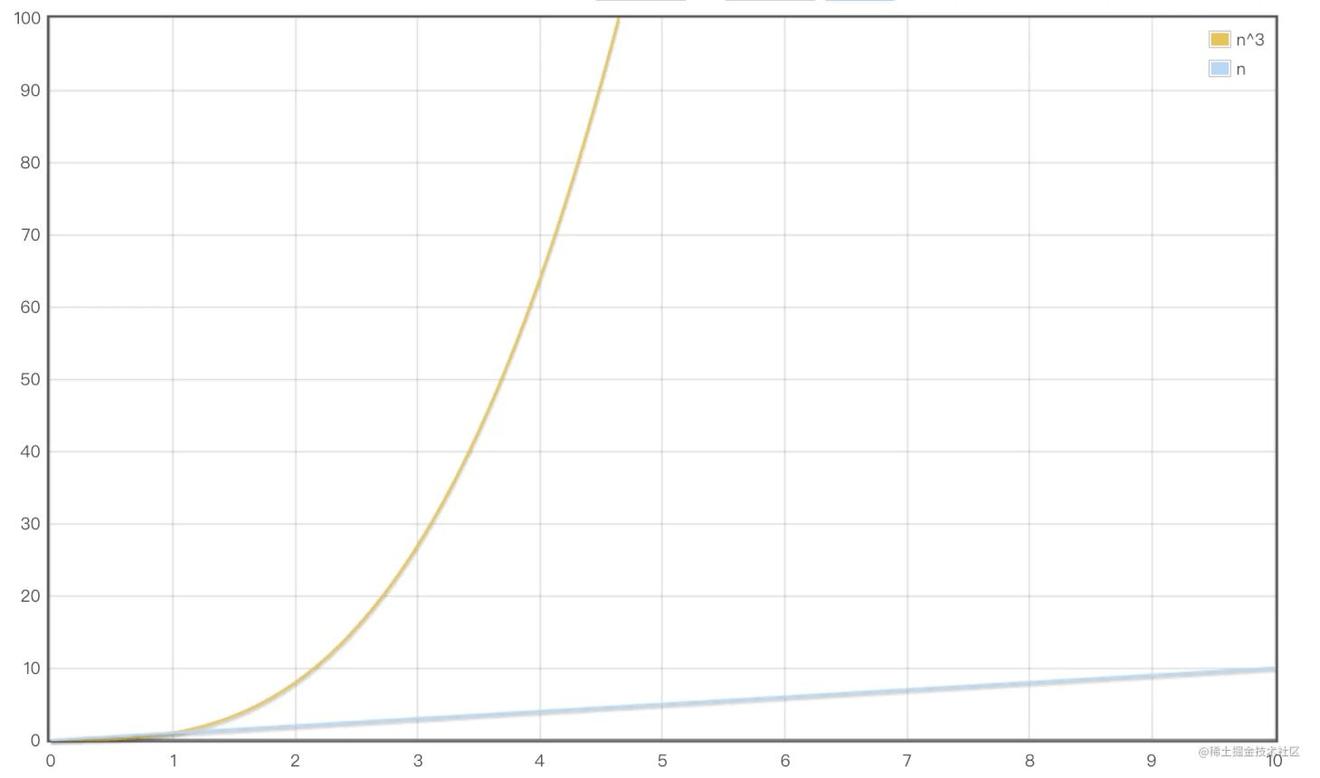
从上面这张图来看,React的diff算法所带来的提升无疑是巨大无比的。接下来我们再看一张图:

从1979到2011,30多年的时间,才将时间复杂度搞到O(n^3),而React从开源到现在不过区区几年的时间,却一下子干到O(n),到这里不禁再次膜拜一下React的创造者们。
那么React这个diff算法是如何做到的呢?
React diff原理
前面我们讲到传统diff算法的时间复杂度为O(n3),其中n为树中节点的总数,随着n的增加,diff所耗费的时间将呈现爆炸性的增长。react却利用其特殊的diff算法做到了O(n3)到O(n)的飞跃性的提升,而完成这一壮举的法宝就是下面这三条看似简单的diff策略:
- Web UI中DOM节点跨层级的移动操作特别少,可以忽略不计。
- 拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。
- 对于同一层级的一组子节点,它们可以通过唯一 id 进行区分。
在上面三个策略的基础上,React 分别将对应的tree diff、component diff 以及 element diff 进行算法优化,极大地提升了diff效率。
tree diff
基于策略一,React 对树的算法进行了简洁明了的优化,即对树进行分层比较,两棵树只会对同一层次的节点进行比较。
既然 DOM 节点跨层级的移动操作少到可以忽略不计,针对这一现象,React只会对相同层级的 DOM 节点进行比较,即同一个父节点下的所有子节点。当发现节点已经不存在时,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。这样只需要对树进行一次遍历,便能完成整个 DOM 树的比较。
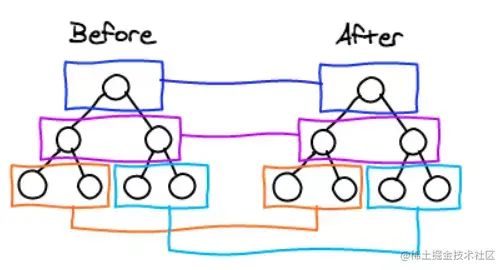
策略一的前提是Web UI中DOM节点跨层级的移动操作特别少,但并没有否定DOM节点跨层级的操作的存在,那么当遇到这种操作时,React是如何处理的呢?
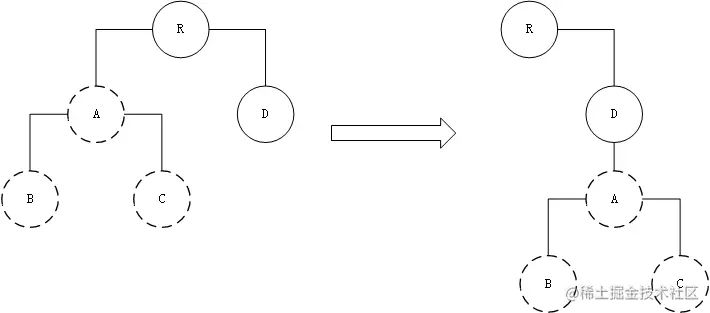
接下来我们通过一张图来展示整个处理过程:

A 节点(包括其子节点)整个被移动到 D 节点下,由于 React 只会简单地考虑同层级节点的位置变换,而对于不 同层级的节点,只有创建和删除操作。当根节点发现子节点中 A 消失了,就会直接销毁 A;当 D 发现多了一个子节点 A,则会创 建新的 A(包括子节点)作为其子节点。此时,diff 的执行情况:create A → create B → create C → delete A。
由此可以发现,当出现节点跨层级移动时,并不会出现想象中的移动操作,而是以 A 为根节点的整个树被重新创建。这是一种影响React性能的操作,因此官方建议不要进行 DOM 节点跨层级的操作。
在开发组件时,保持稳定的 DOM 结构会有助于性能的提升。例如,可以通过 CSS 隐藏或显示节点,而不是真正地移
除或添加 DOM 节点。
component diff
React 是基于组件构建应用的,对于组件间的比较所采取的策略也是非常简洁、高效的。
如果是同一类型的组件,按照原策略继续比较 Virtual DOM 树即可。
如果不是,则将该组件判断为 dirty component,从而替换整个组件下的所有子节点。
对于同一类型的组件,有可能其 Virtual DOM 没有任何变化,如果能够确切知道这点,那么就可以节省大量的 diff 运算时间。因此,React允许用户通过shouldComponentUpdate()来判断该组件是否需进行diff算法分析,但是如果调用了forceUpdate方法,shouldComponentUpdate则失效。
参考React实战视频讲解:进入学习
接下来我们看下面这个例子是如何实现转换的:
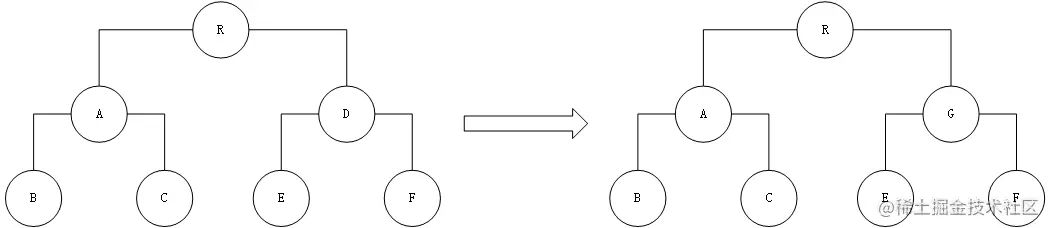
转换流程如下:

当组件D变为组件G时,即使这两个组件结构相似,一旦React判断D和G是不同类型的组件,就不会比较二 者的结构,而是直接删除组件D,重新创建组件G及其子节点。虽然当两个组件是不同类型但结构相似时,diff会影响性能,但正如React官方博客所言:不同类型的组件很少存在相似DOM树的情况,因此这种极端因素很难在实际开发过程中造成重大的影响。
element diff
当节点处于同一层级时,diff 提供了 3 种节点操作,分别为 INSERT_MARKUP (插入)、MOVE_EXISTING (移动)和 REMOVE_NODE (删除)。
INSERT_MARKUP :新的组件类型不在旧集合里,即全新的节点,需要对新节点执行插入操作。
MOVE_EXISTING :旧集合中有新组件类型,且 element 是可更新的类型,generateComponentChildren 已调用
receiveComponent ,这种情况下 prevChild=nextChild ,就需要做移动操作,可以复用以前的 DOM 节点。
REMOVE_NODE :旧组件类型,在新集合里也有,但对应的 element 不同则不能直接复用和更新,需要执行删除操作,或者旧组件不在新集合里的,也需要执行删除操作。
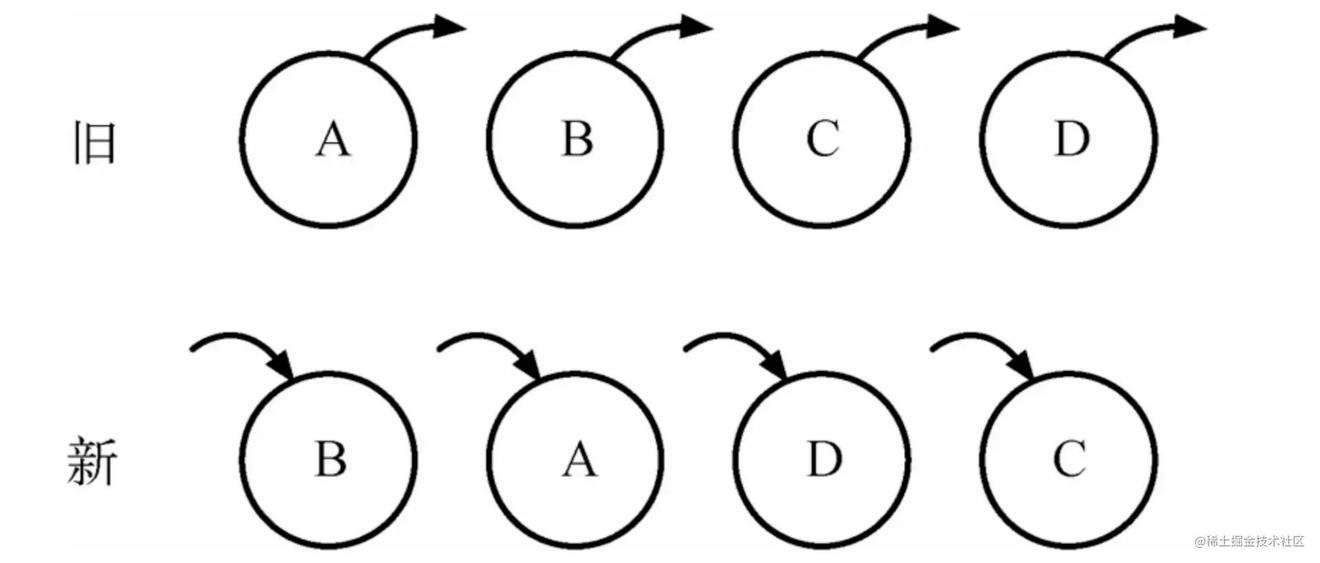
旧集合中包含节点A、B、C和D,更新后的新集合中包含节点B、A、D和C,此时新旧集合进行diff差异化对比,发现B!=A,则创建并插入B至新集合,删除旧集合A;以此类推,创建并插入A、D和C,删除B、C和D。
我们发现这些都是相同的节点,仅仅是位置发生了变化,但却需要进行繁杂低效的删除、创建操作,其实只要对这些节点进行位置移动即可。React针对这一现象提出了一种优化策略:允许开发者对同一层级的同组子节点,添加唯一 key 进行区分。 虽然只是小小的改动,性能上却发生了翻天覆地的变化!我们再来看一下应用了这个策略之后,react diff是如何操作的。
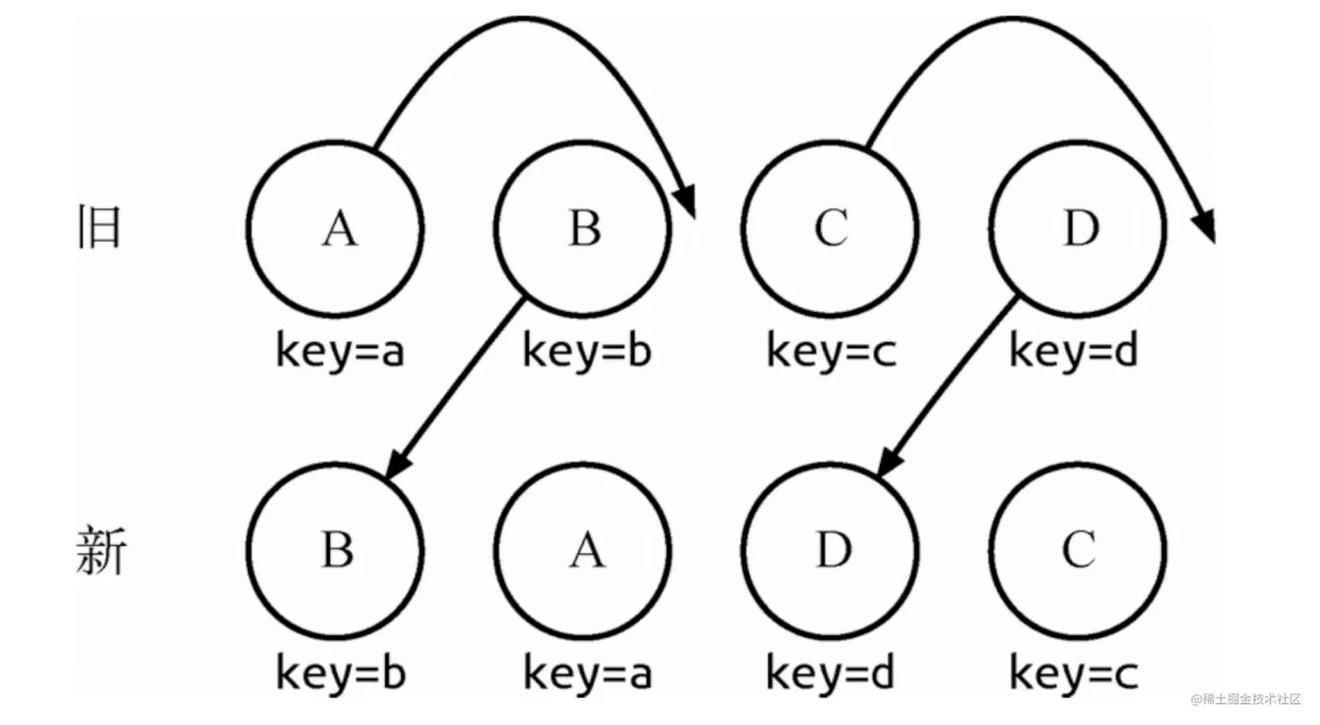
通过key可以准确地发现新旧集合中的节点都是相同的节点,因此无需进行节点删除和创建,只需要将旧集合中节点的位置进行移动,更新为新集合中节点的位置,此时React 给出的diff结果为:B、D不做任何操作,A、C进行移动操作即可。
具体的流程我们用一张表格来展现一下:
index | 节点 | oldIndex | maxIndex | 操作 |
0 | B | 1 | 0 | oldIndex(1)>maxIndex(0),maxIndex=oldIndex,maxIndex变为1 |
1 | A | 0 | 1 | oldIndex(0)<maxIndex(1),节点A移动至index(1)的位置 |
2 | D | 3 | 1 | oldIndex(3)>maxIndex(1),maxIndex=oldIndex,maxIndex变为3 |
3 | C | 2 | 3 | oldIndex(2)<maxIndex(3),节点C移动至index(3)的位置 |
- index: 新集合的遍历下标。
- oldIndex:当前节点在老集合中的下标。
- maxIndex:在新集合访问过的节点中,其在老集合的最大下标值。
操作一栏中只比较oldIndex和maxIndex:
- 当oldIndex>maxIndex时,将oldIndex的值赋值给maxIndex
- 当oldIndex=maxIndex时,不操作
- 当oldIndex<maxIndex时,将当前节点移动到index的位置
上面的例子仅仅是在新旧集合中的节点都是相同的节点的情况下,那如果新集合中有新加入的节点且旧集合存在 需要删除的节点,那么 diff 又是如何对比运作的呢?
index | 节点 | oldIndex | maxIndex | 操作 |
0 | B | 1 | 0 | oldIndex(1)>maxIndex(0),maxIndex=oldIndex,maxIndex变为1 |
1 | E | - | 1 | oldIndex不存在,添加节点E至index(1)的位置 |
2 | C | 2 | 1 | oldIndex(2)>maxIndex(1),maxIndex=oldIndex,maxIndex变为2 |
3 | A | 0 | 2 | oldIndex(0)<maxIndex(2),节点A移动至index(3)的位置 |
注:最后还需要对旧集合进行循环遍历,找出新集合中没有的节点,此时发现存在这样的节点D,因此删除节点D,到此 diff 操作全部完成。
同样操作一栏中只比较oldIndex和maxIndex,但是oldIndex可能有不存在的情况:
oldIndex存在
- 当oldIndex>maxIndex时,将oldIndex的值赋值给maxIndex
- 当oldIndex=maxIndex时,不操作
- 当oldIndex<maxIndex时,将当前节点移动到index的位置
oldIndex不存在
新增当前节点至index的位置
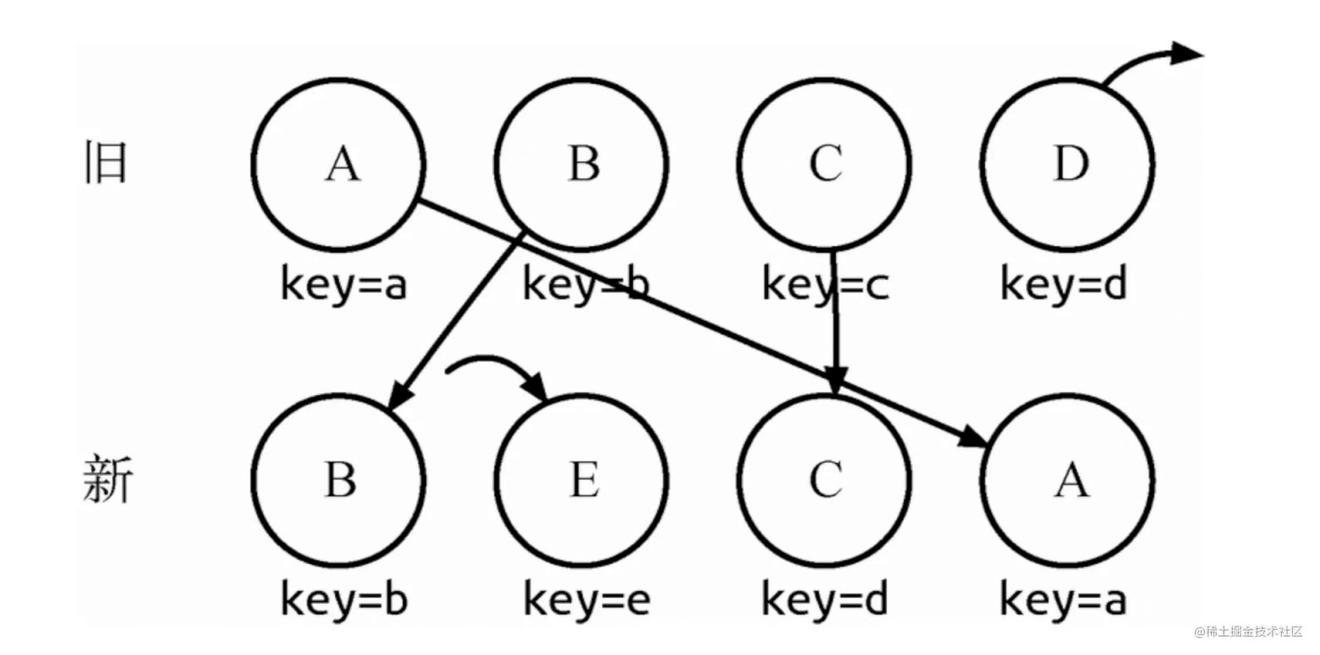
当然这种diff并非完美无缺的,我们来看这么一种情况:
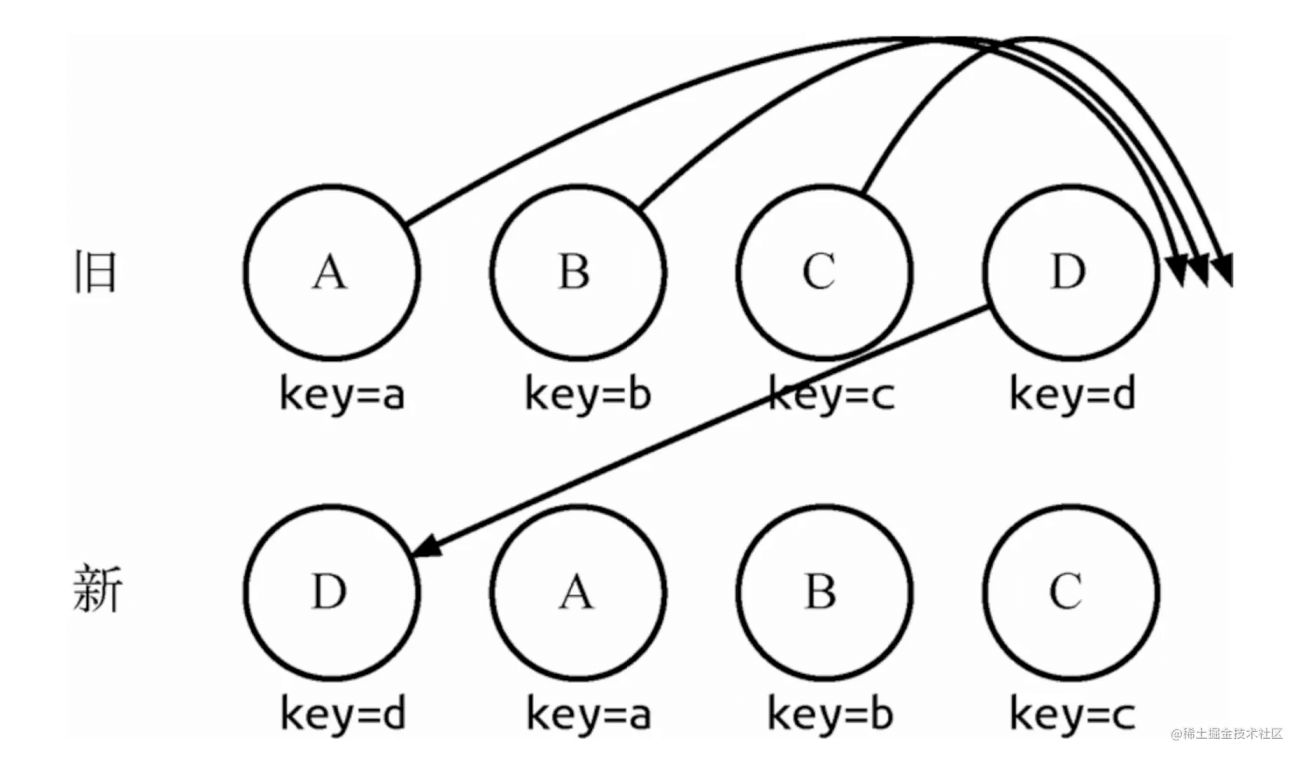
实际我们只需对D执行移动操作,然而由于D在旧集合中的位置是最大的,导致其他节点的oldIndex < maxIndex,造成D没有执行移动操作,而是A、B、C全部移动到D节点后面的现象。针对这种情况,官方建议:
在开发过程中,尽量减少类似将最后一个节点移动到列表首部的操作。当节点数量过大或更新操作过于频繁时,这在一定程度上会影响React的渲染性能。
由于key的存在,react可以准确地判断出该节点在新集合中是否存在,这极大地提高了diff效率。我们在开发过中进行列表渲染的时候,若没有加key,react会抛出警告要求开发者加上key,就是为了提高diff效率。但是加了key一定要比没加key的性能更高吗?我们再来看一个例子:
现在有一集合[1,2,3,4,5],渲染成如下的样子:
<div>1</div>
<div>2</div>
<div>3</div>
<div>4</div>
<div>5</div>
---------------
现在我们将这个集合的顺序打乱变成[1,3,2,5,4]。
1.加key
<div key='1'>1</div> <div key='1'>1</div>
<div key='2'>2</div> <div key='3'>3</div>
<div key='3'>3</div> ========> <div key='2'>2</div>
<div key='4'>4</div> <div key='5'>5</div>
<div key='5'>5</div> <div key='4'>4</div>
操作:节点2移动至下标为2的位置,节点4移动至下标为4的位置。
2.不加key
<div>1</div> <div>1</div>
<div>2</div> <div>3</div>
<div>3</div> ========> <div>2</div>
<div>4</div> <div>5</div>
<div>5</div> <div>4</div>
操作:修改第1个到第5个节点的innerText
---------------
如果我们对这个集合进行增删的操作改成[1,3,2,5,6]。
1.加key
<div key='1'>1</div> <div key='1'>1</div>
<div key='2'>2</div> <div key='3'>3</div>
<div key='3'>3</div> ========> <div key='2'>2</div>
<div key='4'>4</div> <div key='5'>5</div>
<div key='5'>5</div> <div key='6'>6</div>
操作:节点2移动至下标为2的位置,新增节点6至下标为4的位置,删除节点4。
2.不加key
<div>1</div> <div>1</div>
<div>2</div> <div>3</div>
<div>3</div> ========> <div>2</div>
<div>4</div> <div>5</div>
<div>5</div> <div>6</div>
操作:修改第1个到第5个节点的innerText
---------------
通过上面这两个例子我们发现:
由于dom节点的移动操作开销是比较昂贵的,没有key的情况下要比有key的性能更好。
通过上面的例子我们发现,虽然加了key提高了diff效率,但是未必一定提升了页面的性能。因此我们要注意这么一点:
对于简单列表页渲染来说,不加key要比加了key的性能更好
根据上面的情况,最后我们总结一下key的作用:
- 准确判断出当前节点是否在旧集合中
- 极大地减少遍历次数
应用实践
页面指定区域刷新
现在有这么一个需求,当用户身份变化时,当前页面重新加载数据。猛一看过去觉得非常简单,没啥难度的,只要在componentDidUpdate这个生命周期里去判断用户身份是否发生改变,如果发生改变就重新请求数据,于是就有了以下这一段代码:
import React from 'react';
import {connect} from 'react-redux';
let oldAuthType = '';//用来存储旧的用户身份
@connect(
state=>state.user
)
class Page extends React.PureComponent{
state={
loading:true
}
loadMainData(){
//这里采用了定时器去模拟数据请求
this.setState({
loading:true
});
const timer = setTimeout(()=>{
this.setState({
loading:false
});
clearTimeout(timer);
},);
}
componentDidUpdate(){
const {authType} = this.props;
//判断当前用户身份是否发生了改变
if(authType!==oldAuthType){
//存储新的用户身份
oldAuthType=authType;
//重新加载数据
this.loadMainData();
}
}
componentDidMount(){
oldAuthType=this.props.authType;
this.loadMainData();
}
render(){
const {loading} = this.state;
return (
<h>{`页面1${loading?'加载中...':'加载完成'}`}</h2>
)
}
}
export default Page;
看上去我们仅仅通过加上一段代码就完成了这一需求,但是当我们页面是几十个的时候,那这种方法就显得捉襟见肘了。哪有没有一个很好的方法来实现这个需求呢?其实很简单,利用react diff的特性就可以实现它。对于这个需求,实际上就是希望当前组件可以销毁在重新生成,那怎么才能让其销毁并重新生成呢?通过上面的总结我发现两种情况,可以实现组件的销毁并重新生成。
当组件类型发生改变当key值发生变化
接下来我们就结合这两个特点,用两种方法去实现。
第一种:引入一个loading组件。切换身份时设置loading为true,此时loading组件显示;切换身份完成,loading变为false,其子节点children显示。
<div className="g-main">{<!--{cke_protected}{C}%C!%2D%2D%20%2D%2D%3E-->loading?<Loading/>:children}</div>
第二种:在刷新区域加上一个key值就可以了,用户身份一改变,key值就发生改变。
<div className="g-main" key={authType}>{children}</div>
第一种和第二种取舍上,个人建议的是这样子的:
如果需要请求服务器的,用第一种,因为请求服务器会有一定等待时间,加入loading组件可以让用户有感知,体验更好。如果是不需要请求服务器的情况下,选用第二种,因为第二种更简单实用。
更加方便地监听props改变
针对这个需求,我们喜欢将搜索条件封装成一个组件,查询列表封装成一个组件。其中查询列表会接收一个查询参数的属性,如下所示:
import React from 'react';
import {Card} from 'antd';
import Filter from './components/filter';
import Teacher from './components/teacher';
export default class Demo extends React.PureComponent{
state={
filters:{
name:undefined,
height:undefined,
age:undefined
}
}
handleFilterChange=(filters)=>{
this.setState({
filters
});
}
render(){
const {filters} = this.state;
return <Card>
{/* 过滤器 */} <Filter onChange={this.handleFilterChange}/> {/* 查询列表 */} <Teacher filters={filters}/>
</Card>
}
}
现在我们面临一个问题,如何在组件Teacher中监听filters的变化,由于filters是一个引用类型,想监听其变化变得有些复杂,好在lodash提供了比较两个对象的工具方法,使其简单了。但是如果后期给Teacher加了额外的props,此时你要监听多个props的变化时,你的代码将变得比较难以维护。针对这个问题,我们依旧可以通过key值去实现,当每次搜索时,重新生成一个key,那么Teacher组件就会重新加载了。代码如下:
import React from 'react';
import {Card} from 'antd';
import Filter from './components/filter';
import Teacher from './components/teacher';
export default class Demo extends React.PureComponent{
state={
filters:{
name:undefined,
height:undefined,
age:undefined
},
tableKey:this.createTableKey()
}
createTableKey(){
return Math.random().toString().substring(7);
}
handleFilterChange=(filters)=>{
this.setState({
filters,
//重新生成tableKey
tableKey:this.createTableKey()
});
}
render(){
const {filters,tableKey} = this.state;
return <Card>
{/* 过滤器 */} <Filter onChange={this.handleFilterChange}/> {/* 查询列表 */} <Teacher key={tableKey} filters={filters}/>
</Card>
}
}
即使后期给Teacher加入新的props,也没有问题,只需拼接一下key即可:
<Teacher key={`${tableKey}-${prop1}-${prop2}`} filters={filters} prop1={prop1} prop2={prop2}/>
react-router中Link问题
先看一下demo代码:
import React from 'react';
import {Card,Spin,Divider,Row,Col} from 'antd';
import {Link} from 'react-router-dom';
const bookList = [{
bookId:'',
bookName:'三国演义',
author:'罗贯中'
},{
bookId:'',
bookName:'水浒传',
author:'施耐庵'
}]
export default class Demo extends React.PureComponent{
state={
bookList:[],
bookId:'',
loading:true
}
loadBookList(bookId){
this.setState({
loading:true
});
const timer = setTimeout(()=>{
this.setState({
loading:false,
bookId,
bookList
});
clearTimeout(timer);
},);
}
componentDidMount(){
const {match} = this.props;
const {params} = match;
const {bookId} = params;
this.loadBookList(bookId);
}
render(){
const {bookList,bookId,loading} = this.state;
const selectedBook = bookList.find((book)=>book.bookId===bookId);
return <Card>
<Spin spinning={loading}>
{ selectedBook&&(<div>
<img width="" src={`/static/images/book_cover_${bookId}.jpeg`}/>
<h>书名:{selectedBook?selectedBook.bookName:'--'}</h4>
<div>作者:{selectedBook?selectedBook.author:'--'}</div>
</div>) } <Divider orientation="left">关联图书</Divider>
<Row>
{ bookList.filter((book)=>book.bookId!==bookId).map((book)=>{ const {bookId,bookName} = book; return <Col span={}>
<img width="" src={`/static/images/book_cover_${bookId}.jpeg`}/>
<h><Link to={`/demo3/${bookId}`}>{bookName}</Link></h4>
</Col>
}) } </Row>
</Spin>
</Card>
}
}
通过演示gif,我们看到了地址栏的地址已经发生改变,但是并没有我们想象中那样从新走一遍componentDidMount去请求数据,这说明我们的组件并没有实现销毁并重新生成这么一个过程。解决这个问题你可以在componentDidUpdate去监听其改变:
componentDidUpdate(){
const {match} = this.props;
const {params} = match;
const {bookId} = params;
if(bookId!==this.state.bookId){
this.loadBookList(bookId);
}
}
前面我们说过如果是后期需要监听多个props的话,这样子后期维护比较麻烦.同样我们还是利用key去解决这个问题,首页我们可以将页面封装成一个组件BookDetail,并且在其外层再包裹一层,再去给BookDetail加key,代码如下:
import React from 'react';
import BookDetail from './bookDetail';
export default class Demo extends React.PureComponent{
render(){
const {match} = this.props;
const {params} = match;
const {bookId} = params;
return <BookDetail key={bookId} bookId={bookId}/>
}
}
这样的好处是我们代码结构更加清晰,后续拓展新功能比较简单。
结语
React的高效得益于其Virtual DOM+React diff的体系。diff算法并非react独创,react只是在传统diff算法做了优化。但因为其优化,将diff算法的时间复杂度一下子从O(n^3)降到O(n)。
React diff的三大策略:
- Web UI中DOM节点跨层级的移动操作特别少,可以忽略不计。
- 拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。
- 对于同一层级的一组子节点,它们可以通过唯一 id 进行区分。
在开发组件时,保持稳定的 DOM 结构会有助于性能的提升。
在开发过程中,尽量减少类似将最后一个节点移动到列表首部的操作。key的存在是为了提升diff效率,但未必一定就可以提升性能,记住简单列表渲染情况下,不加key要比加key的性能更好。
懂得借助react diff的特性去解决我们实际开发中的一系列问题。