概述
这条sql是典型的在数据量增加的情况下,mysql数据库自动选择了另一个执行计划,这里只要通过改写sql来实现该sql的优化,仅供参考。
1、定位慢sql
至于怎么获取到该问题sql,实际上只需要跑一下慢查询查一下就可以看到了..
有兴趣的朋友也可以看下之前介绍的慢查询平台来获取慢sql...
pt-query-digest slow.log --since '2021-01-28 00:00:00' --until '2021-01-28 23:59:00' > /tmp/tms-slow.log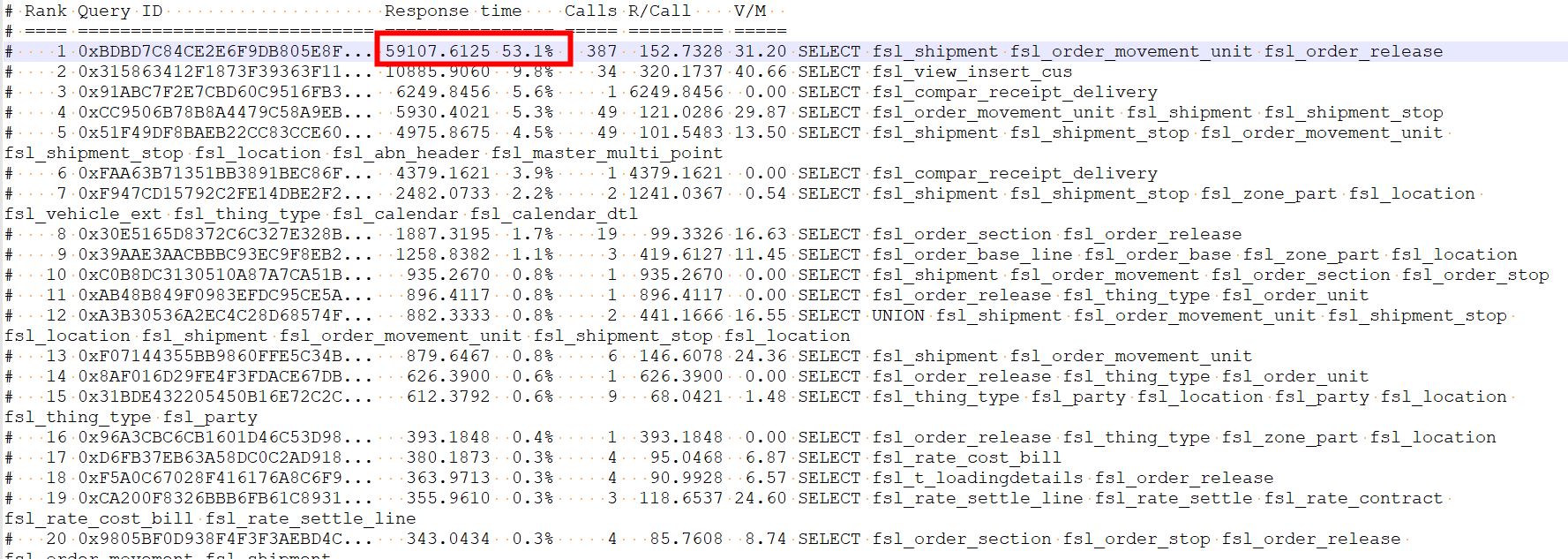
2、分析问题sql
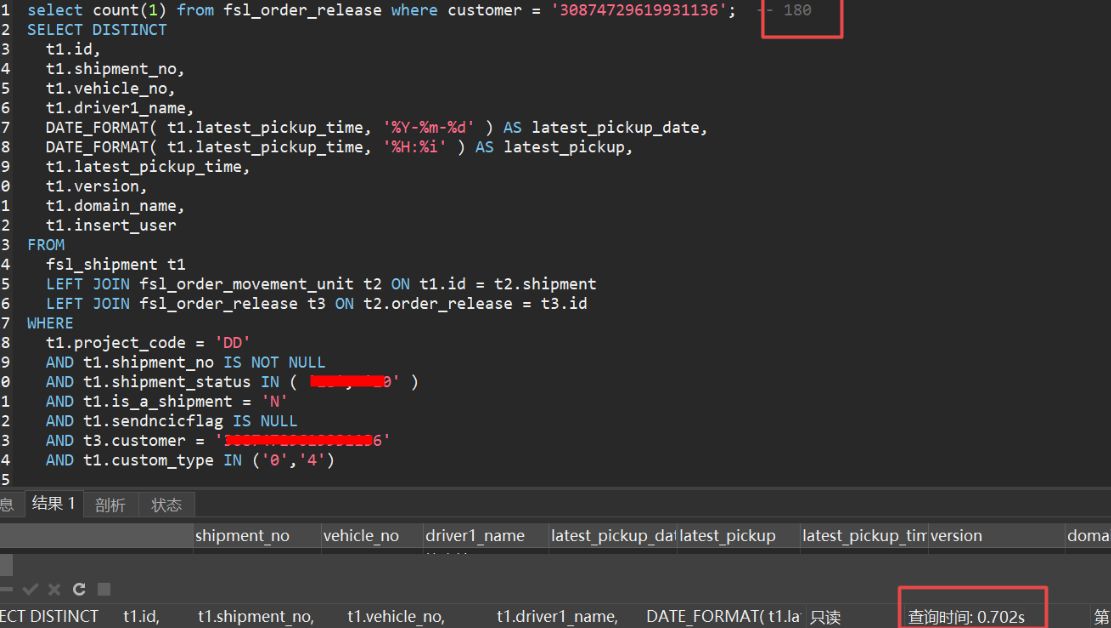
可以看出只是查询一条记录但耗时385秒
SELECT DISTINCT
t1.id,
t1.shipment_no,
t1.vehicle_no,
t1.driver1_name,
DATE_FORMAT( t1.latest_pickup_time, '%Y-%m-%d' ) AS latest_pickup_date,
DATE_FORMAT( t1.latest_pickup_time, '%H:%i' ) AS latest_pickup,
t1.latest_pickup_time,
t1.version,
t1.domain_name,
t1.insert_user
FROM
fsl_shipment t1
LEFT JOIN fsl_order_movement_unit t2 ON t1.id = t2.shipment
LEFT JOIN fsl_order_release t3 ON t2.order_release = t3.id
WHERE
t1.project_code = 'xx'
AND t1.shipment_no IS NOT NULL
AND t1.shipment_status IN ( 'xx', 'xx' )
AND t1.is_a_shipment = 'N'
AND t1.sendncicflag IS NULL
AND t3.customer = '3xxx6'
AND t1.custom_type IN ( 'xx','xx')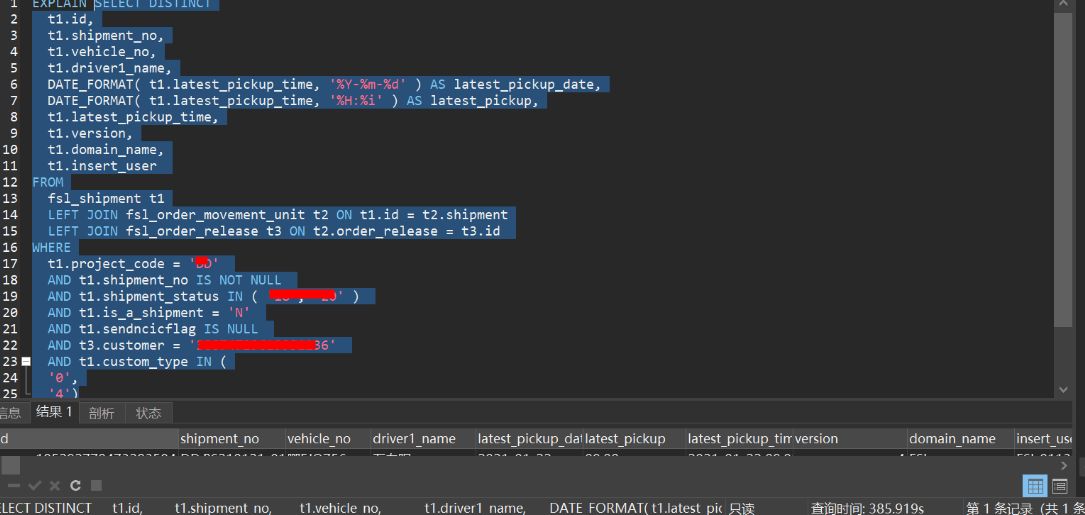
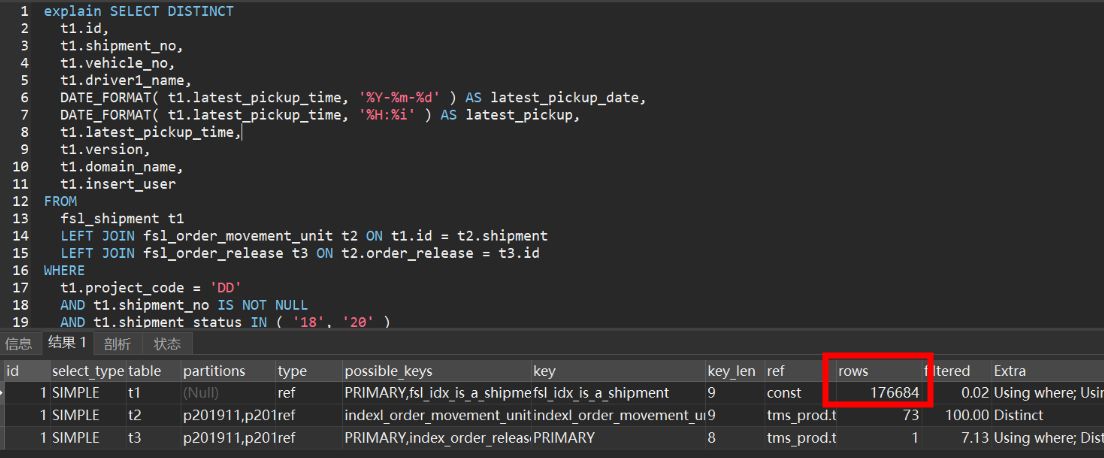
对应的执行计划如下:
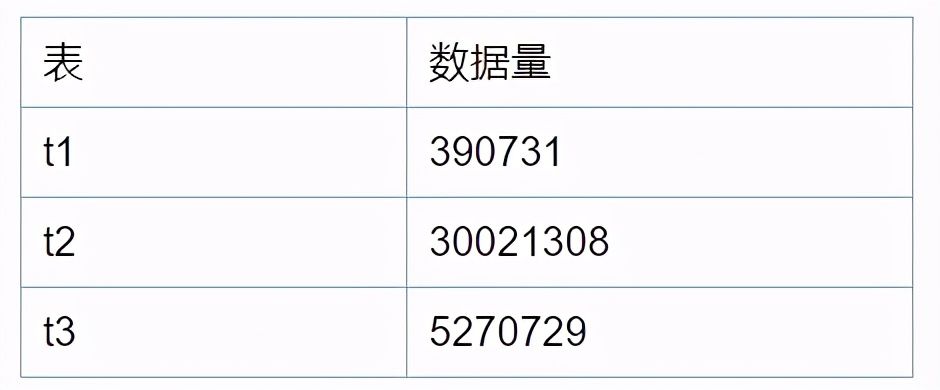
对应的表数据量情况如下:
3、业测环境测试
这里要说一下为什么在业测环境之所以只需要0.7s,其实是因为生产环境的t3表customer结果集比较大,导致先筛选t1表,在筛选t2表,最后筛选t3表,导致耗时接近400s;而UAT环境的t3表customer结果集小时则先筛选t3表,最后再筛选t1表,速度在1秒内。
4、改写sql优化
这里耗时16s。
SELECT DISTINCT
t1.id,
t1.shipment_no,
t1.vehicle_no,
t1.driver1_name,
DATE_FORMAT( t1.latest_pickup_time, '%Y-%m-%d' ) AS latest_pickup_date,
DATE_FORMAT( t1.latest_pickup_time, '%H:%i' ) AS latest_pickup,
t1.latest_pickup_time,
t1.version,
t1.domain_name,
t1.insert_user
FROM
fsl_shipment t1
LEFT JOIN fsl_order_movement_unit t2 ON t1.id = t2.shipment
LEFT JOIN (select id from fsl_order_release where customer = 'xxx') t3 ON t2.order_release = t3.id
WHERE
t1.project_code = 'DD'
AND t1.shipment_no IS NOT NULL
AND t1.shipment_status IN ( '18', '20' )
AND t1.is_a_shipment = 'N'
AND t1.sendncicflag IS NULL
AND t1.custom_type IN ('0','4');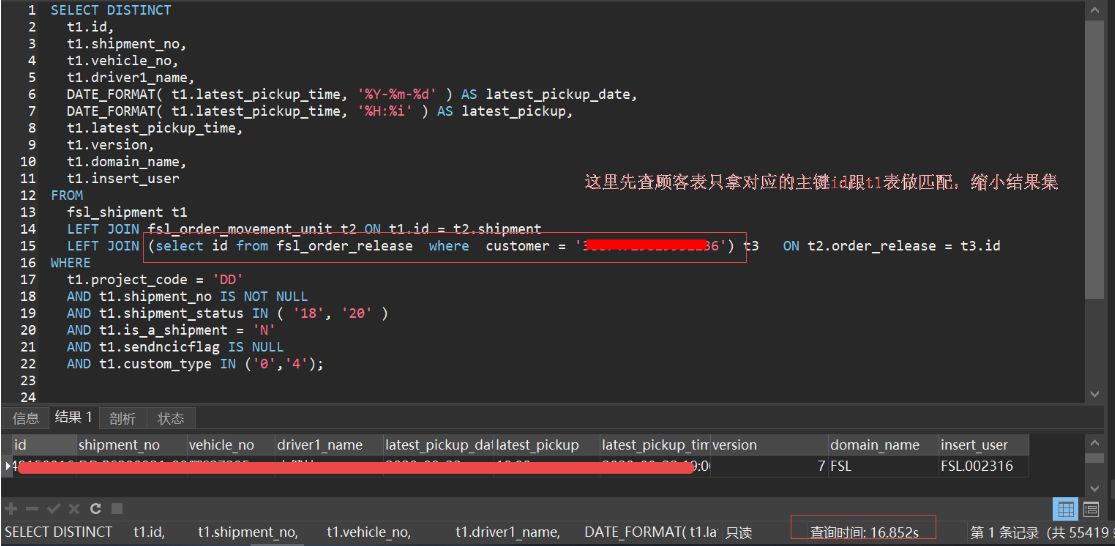
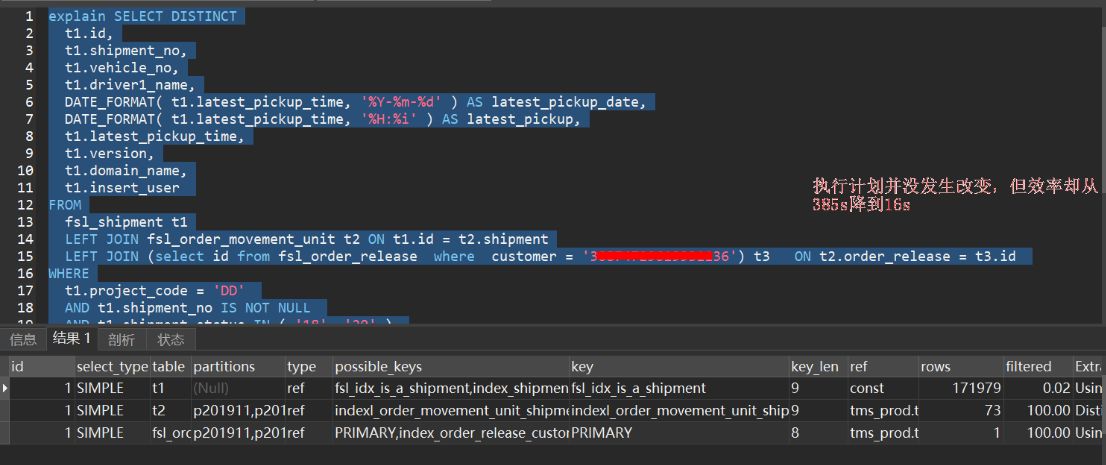
对应的执行计划如下;
后面会分享更多devops和DBA方面内容,感兴趣的朋友可以关注下!
