一、安装sklearn
先安装Python环境。可以使用pip来安装sklearn库:
pip install scikit-learn
二、数据预处理
在使用sklearn进行机器学习之前,需要对数据进行预处理。sklearn提供了一系列的数据预处理工具,如StandardScaler用于特征缩放,OneHotEncoder用于处理类别特征等。
2.1 特征缩放
在数据预处理中,特征缩放是一个非常重要的步骤,它可以帮助提升机器学习算法的性能和稳定性。在sklearn库中,提供了多种特征缩放和预处理的工具:

1. StandardScaler
- 作用:用于特征的标准化,即将特征值缩放到均值为0,方差为1的分布。
- 栗子:
| from sklearn.preprocessing import StandardScaler | |
| import numpy as np | |
| # 创建一个数据集 | |
| X = np.array([[1, 2], [3, 4], [5, 6]]) | |
| # 初始化StandardScaler | |
| scaler = StandardScaler() | |
| # 使用fit_transform方法对数据进行缩放 | |
| X_scaled = scaler.fit_transform(X) | |
| print(X_scaled) |
2. MinMaxScaler
- 作用:将特征数据缩放到一个指定的范围(通常是0到1),或者也可以将每个特征的最大绝对值缩放到单位大小。
- 栗子:
| from sklearn.preprocessing import MinMaxScaler | |
| data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] | |
| scaler = MinMaxScaler() | |
| # 使用fit_transform方法对数据进行缩放 | |
| scaled_data = scaler.fit_transform(data) | |
| print(scaled_data) |
3. MaxAbsScaler
- 作用:将每个特征缩放到[-1, 1]的范围内,通过除以每个特征的最大绝对值来实现。
- 栗子:
| from sklearn.preprocessing import MaxAbsScaler | |
| X = np.array([[1, -1, 2], [2, 0, 0], [0, 1, -1]]) | |
| scaler = MaxAbsScaler() | |
| # 使用fit_transform方法对数据进行缩放 | |
| X_scaled = scaler.fit_transform(X) | |
| print(X_scaled) |
4. RobustScaler
- 作用:使用中位数和四分位数范围(IQR)来缩放特征。这对于有许多离群点的数据集特别有用。
- 栗子:
| from sklearn.preprocessing import RobustScaler | |
| X = np.array([[1, -2, 2], [2, -1, 0], [0, 1, -1]]) | |
| scaler = RobustScaler() | |
| # 使用fit_transform方法对数据进行缩放 | |
| X_scaled = scaler.fit_transform(X) | |
| print(X_scaled) |
5. Normalizer
- 作用:将每个样本缩放到单位范数,即使得每个样本的L1或L2范数为1。
- 栗子:
| from sklearn.preprocessing import Normalizer | |
| X = np.array([[1, 2], [3, 4], [5, 6]]) | |
| normalizer = Normalizer(norm='l2') # 可以选择'l1'或'l2'范数 | |
| # 使用fit_transform方法对数据进行缩放 | |
| X_normalized = normalizer.fit_transform(X) | |
| print(X_normalized) |

2.2 数据清洗
数据清洗包括处理缺失值、异常值、重复值等。
处理缺失值
- 栗子:使用
SimpleImputer填充缺失值。
| from sklearn.impute import SimpleImputer | |
| imputer = SimpleImputer(strategy='mean') # 可以选择'mean'、'median'、'most_frequent'等策略 | |
| X_train_imputed = imputer.fit_transform(X_train) |
2.3 编码分类特征
对于分类数据,需要将其转换为机器学习模型可以理解的数值形式。
独热编码(One-Hot Encoding)
- 栗子:使用
OneHotEncoder进行独热编码。
| from sklearn.preprocessing import OneHotEncoder | |
| encoder = OneHotEncoder() | |
| X_train_encoded = encoder.fit_transform(X_train) |
标签编码(Label Encoding)
- 虽然sklearn不直接提供标签编码的类,但可以使用
LabelEncoder对目标变量进行编码。
| from sklearn.preprocessing import LabelEncoder | |
| le = LabelEncoder() | |
| y_train_encoded = le.fit_transform(y_train) |
2.3. 特征选择和降维
选择重要的特征或降低数据的维度可以帮助提高模型的效率和准确性。
方差阈值
- 栗子:使用
VarianceThreshold删除方差低于阈值的特征。
| from sklearn.feature_selection import VarianceThreshold | |
| selector = VarianceThreshold(threshold=0.1) | |
| X_train_selected = selector.fit_transform(X_train) |
单变量特征选择
- 栗子:使用
SelectKBest选择与目标变量相关性最高的K个特征。
| from sklearn.feature_selection import SelectKBest, f_regression | |
| selector = SelectKBest(score_func=f_regression, k=5) | |
| X_train_selected = selector.fit_transform(X_train, y_train) |
主成分分析(PCA)
- PCA是一种常用的降维技术,虽然它不属于预处理步骤,但经常在数据预处理后使用。
| from sklearn.decomposition import PCA | |
| pca = PCA(n_components=2) # 指定要保留的主成分数量 | |
| X_train_reduced = pca.fit_transform(X_train) |
2.4. 数据拆分
在机器学习中,通常需要将数据集拆分为训练集和测试集。
- 栗子:使用
train_test_split拆分数据集。
| from sklearn.model_selection import train_test_split | |
| X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) |
2.5. 数据转换
数据转换包括将数据集转换为更适合机器学习模型的形式。
多项式特征
- 栗子:使用
PolynomialFeatures生成多项式特征。
| from sklearn.preprocessing import PolynomialFeatures | |
| poly = PolynomialFeatures(degree=2) # 指定多项式的度数 | |
| X_train_poly = poly.fit_transform(X_train) |
这些预处理工具和技术在sklearn库中都有提供,可以根据具体的数据集和机器学习任务来选择合适的预处理步骤。
三、分类算法
分类算法是机器学习领域的一个重要分支,旨在根据输入数据的特征将其划分为不同的类别。下面勒是一些常用的分类算法:
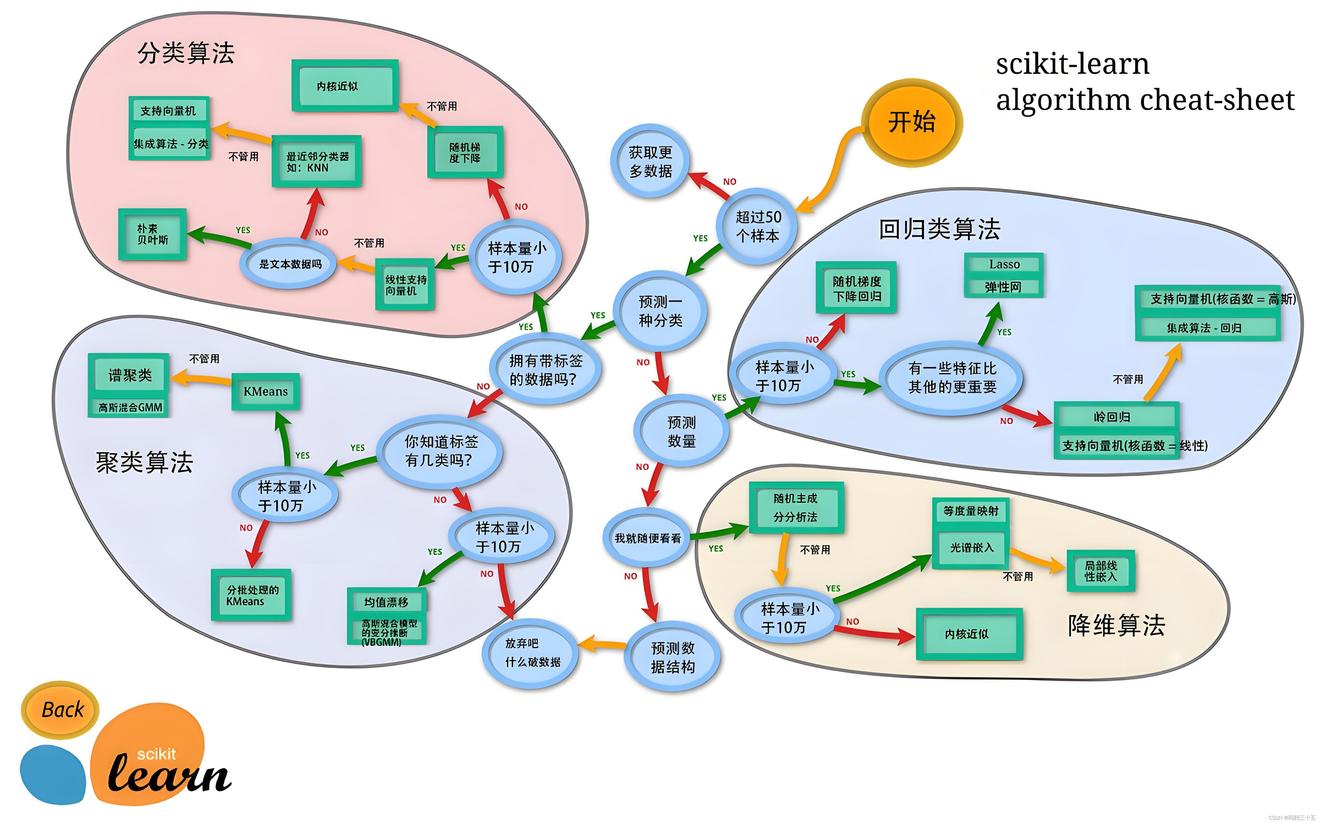
- 逻辑回归(Logistic Regression):
- 逻辑回归是一种线性分类算法,通过逻辑函数预测概率,根据概率决定分类的阈值。
- 适用于二分类问题,如预测邮件是否为垃圾邮件。
- 决策树(Decision Tree):
- 通过递归地选择最佳特征并对特征进行分割,构建树形结构进行分类。
- 易于理解和解释,能处理数值型和类别型数据。
- 可用于银行决定是否给客户贷款等场景。
- 支持向量机(Support Vector Machine, SVM):
- SVM通过寻找最大边际超平面来分隔不同的类别。
- 在高维空间表现良好,适用于小样本数据集,但对大规模数据集的训练效率较低。
- 可应用于手写数字识别等任务。
- 朴素贝叶斯(Naive Bayes):
- 基于贝叶斯定理的分类算法,假设特征之间相互独立。
- 简单、高效,特别适用于文本分类,如新闻文章分类。
- K-近邻算法(K-Nearest Neighbors, KNN):
- 基于实例的学习方法,通过计算待分类样本与训练样本的距离来进行分类。
- 简单直观,但计算成本随数据集增大而增加。
- 可用于房地产价格评估等场景。
- 随机森林(Random Forest):
- 一种集成学习方法,通过构建多个决策树并进行投票来提高分类准确性。
- 能有效减少过拟合,提高模型的稳定性。
- 可应用于信用卡欺诈检测等任务。
- 梯度提升树(Gradient Boosting Trees, GBT):
- 另一种集成学习算法,通过逐步添加新的弱分类器来纠正前一个模型的错误。
- 在许多机器学习竞赛中表现优异,但训练时间可能较长。
- 可用于优化用户行为预测等场景。
- 神经网络(Neural Networks):
- 神经网络是通过模拟人脑神经元连接方式而建立的一种复杂网络模型。
- 适用于图像识别、语音识别、自然语言处理等复杂任务。
- 常见的神经网络类型包括前馈神经网络、反馈神经网络和图神经网络等。其中前馈神经网络(如多层感知机)是应用最广泛的类型之一。
这些分类算法各有特点和适用场景,下面整一个使用逻辑回归进行分类的例子吧:
逻辑回归分类
| from sklearn.datasets import load_iris | |
| from sklearn.linear_model import LogisticRegression | |
| from sklearn.model_selection import train_test_split | |
| from sklearn.metrics import accuracy_score | |
| # 加载iris数据集 | |
| iris = load_iris() | |
| X = iris.data | |
| y = iris.target | |
| # 划分训练集和测试集 | |
| X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) | |
| # 初始化逻辑回归模型 | |
| logreg = LogisticRegression() | |
| # 训练模型 | |
| logreg.fit(X_train, y_train) | |
| # 预测测试集 | |
| y_pred = logreg.predict(X_test) | |
| # 计算准确率 | |
| accuracy = accuracy_score(y_test, y_pred) | |
| print(f"Accuracy: {accuracy}") |
四、回归算法
回归算法是用于预测连续数值输出的监督学习算法。下面是一些常用的回归算法:
- 线性回归(Linear Regression):
- 线性回归用于建立连续数值输出与一个或多个输入特征之间的线性关系。
- 它假设输出与输入特征之间存在线性关系,即可以用一条直线或平面来拟合数据。
- 线性回归的目标是找到一条最佳拟合直线,以最小化预测值与真实值之间的误差。
- 多项式回归(Polynomial Regression):
- 多项式回归是线性回归的扩展,通过引入多项式特征来处理非线性关系。
- 它能够拟合更复杂的数据分布,特别是当数据呈现非线性趋势时。
- 岭回归(Ridge Regression):
- 岭回归是一种正则化的线性回归方法,用于处理共线性问题(即特征之间高度相关)。
- 通过在损失函数中加入L2正则化项,岭回归能够收缩回归系数,减少模型的复杂度,防止过拟合。
- Lasso回归(Lasso Regression):
- Lasso回归也是一种正则化的线性回归方法,与岭回归类似,但使用的是L1正则化。
- Lasso回归倾向于产生稀疏的回归系数,即某些系数会变为零,从而实现特征的自动选择。
- 弹性网络回归(Elastic Net Regression):
- 弹性网络回归是岭回归和Lasso回归的折中方法。
- 它同时使用了L1和L2正则化,通过调整两者的权重来平衡模型的稀疏性和稳定性。
- 支持向量回归(Support Vector Regression, SVR):
- 支持向量回归是支持向量机在回归问题上的应用。
- 它试图找到一个超平面,使得所有数据点到该超平面的距离之和最小。
- SVR对异常值具有一定的鲁棒性,并且适用于高维数据。
- 决策树回归(Decision Tree Regression):
- 决策树回归使用树形结构来表示输入特征与输出值之间的关系。
- 通过递归地将数据划分为不同的子集,并基于某些准则(如信息增益)选择最佳划分点。
- 决策树易于理解和解释,但可能容易过拟合。
- 随机森林回归(Random Forest Regression):
- 随机森林回归是一种集成学习方法,通过构建多个决策树并对它们的预测结果进行平均来提高预测精度。
- 随机森林能够减少模型的方差,提高泛化能力,并且相对不容易过拟合。
- 梯度提升回归树(Gradient Boosting Regression Trees, GBRT):
- 梯度提升回归树是一种迭代的决策树算法,通过逐步添加新的树来修正前面树的预测错误。
- 每棵新树都尝试预测前面所有树的残差(真实值与当前预测值之间的差)。
- GBRT通常具有较高的预测精度,但也可能容易过拟合。
这些回归算法各有优势和适用场景,以下是一个使用线性回归进行预测的简单例子:
线性回归预测
| from sklearn.datasets import make_regression | |
| from sklearn.linear_model import LinearRegression | |
| from sklearn.metrics import mean_squared_error | |
| # 生成一个简单的回归数据集 | |
| X, y = make_regression(n_samples=100, n_features=1, noise=0.1) | |
| # 划分训练集和测试集(略) | |
| # ... | |
| # 初始化线性回归模型 | |
| linreg = LinearRegression() | |
| # 训练模型 | |
| linreg.fit(X_train, y_train) | |
| # 预测测试集 | |
| y_pred = linreg.predict(X_test) | |
| # 计算均方误差 | |
| mse = mean_squared_error(y_test, y_pred) | |
| print(f"Mean Squared Error: {mse}") |
五、模型评估与调优
sklearn还提供了丰富的模型评估工具和调优方法。可以使用交叉验证来评估模型的性能,使用网格搜索来找到最佳的模型参数。
交叉验证和网格搜索
| from sklearn.model_selection import cross_val_score, GridSearchCV | |
| from sklearn.svm import SVC | |
| from sklearn.datasets import load_iris | |
| # 加载iris数据集(略) | |
| # ... | |
| # 初始化SVC模型 | |
| svc = SVC() | |
| # 使用5折交叉验证评估模型性能 | |
| scores = cross_val_score(svc, X, y, cv=5) | |
| print(f"Cross-validation scores: {scores}") | |
| print(f"Mean cross-validation score: {scores.mean()}") | |
| # 使用网格搜索找到最佳参数 | |
| parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]} | |
| clf = GridSearchCV(svc, parameters, cv=5) | |
| clf.fit(X_train, y_train) | |
| print(f"Best parameters: {clf.best_params_}") | |
| print(f"Best score: {clf.best_score_}") |
结语
这篇博客,介绍了解了sklearn库的基础知识,通过几个简单的例子展示了如何使用它进行数据处理、分类、回归以及模型评估与调优。当然,sklearn还提供了更多高级的功能和算法,如聚类、降维、异常检测等,这些都有待我们去探索和学习。希望这篇博客能作为学习sklearn的起点,助你在机器学习的道路上越走越远!