本文为《Deep Learning for LiDAR Point Clouds in Autonomous Driving: A Review》译文,在原文的基础上译者会稍作修改提炼,方便大家学习理解。

目录
引言
Section 1:自动驾驶中LiDAR点云的基本背景
Section 2:自动驾驶的任务和使用LiDAR点云数据的深度学习架构所面临的挑战
Section 3:现有的LiDAR点云数据集和评价指标的总结
Section 4:四种使用不同LiDAR点云表达形式的3D深度学习模型
Section 5:在语义分割、目标检测(定位)和分类(识别)中的应用
Section 6:未来研究的挑战
Section 7:结论
引言
近年来3D LiDAR(激光雷达)数据判别特征方面的深度研究进一步引领了自动驾驶领域的快速发展。然而,自动处理不均匀、非结构化、噪声和海量的3D点云仍是一项具有挑战性和乏味的任务。本文对现有的应用于LiDAR点云的深度学习研究架构进行了系统的回顾,详细介绍了自动驾驶中的特定任务,例如分割、检测和分类。
目前已发表的一些论文侧重于自动驾驶汽车计算机视觉的特定主题,但迄今为止,还没有关于应用于LiDAR点云的深度学习综述性研究。本文旨在缩小该主题的差距。研究总结了近五年来的 140 多项关键贡献,包括具有里程碑意义的3D深度架构、在3D语义分割、目标检测和分类中的卓越深度学习应用;特定的数据集、评估指标和最先进的性能。最后,文章总结了未解决的挑战和未来的研究。
Section 1 背景
准确的环境感知和精确的定位是复杂动态环境中自动驾驶汽车的可靠导航、信息决策和安全驾驶的关键要求。这两项任务需要获取和处理现实世界环境中高度准确且信息丰富的数据。为了获取此类数据,自动驾驶汽车或测绘车辆上往往会配备多个传感器,例如 LiDAR 和数码相机,用于收集和提取目标语境。传统意义上,相机捕获的图像数据具有基于外观的二维表示、低成本和高效率的特点,是感知任务中最常用的数据。但图像数据缺乏3D地理参照信息,因此LiDAR采集的密集的、具有地理参照性的和准确的3D点云数据是有必要的。此外LiDAR对光照条件的变化不敏感,可以在白天和黑夜(即使有眩光和阴影)下工作。
LiDAR点云在汽车中的应用可以分为两个方面:
(1)用于场景理解和目标检测的实时环境感知和处理;
(2)用于可靠定位和参考的高精地图和城市模型生成和构建。
这些应用也有一些类似的任务,大致可分为三类:3D点云分割、3D目标检测与定位、3D目标分类与识别。这些技术导致人们对自动驾驶汽车的点云自动分析的要求越来越迫切。
在深度学习技术带来的突破和3D点云的可访问性的推动下,研究者们将2D深度学习架构扩展到3D数据,对3D深度学习框架进行了研究,并取得了一系列显著的成功经验。本文提供了一个系统的综述,聚焦于使用深度学习技术对自动驾驶构建LiDAR点云的分割、检测和分类框架。
近年来已有几篇基于深度学习的相关研究发表,其中详细描述了深度学习基础和全面的知识。通常关注于深度学习在视觉数据和遥感图像中的应用,有些则针对更具体的任务,如目标检测、语义分割、识别等。也有文章调查了3D数据中的深度学习,但主要是3D CAD模型。《Computer vision for autonomous vehicles: Problems, datasets and state-of-the-art》一文中回顾了自动驾驶汽车在计算机视觉中所面临的挑战、数据集和方法。然而,深度学习在LiDAR点云中的应用尚未得到全面的综述和分析。图1中总结了与深度学习相关的调查。
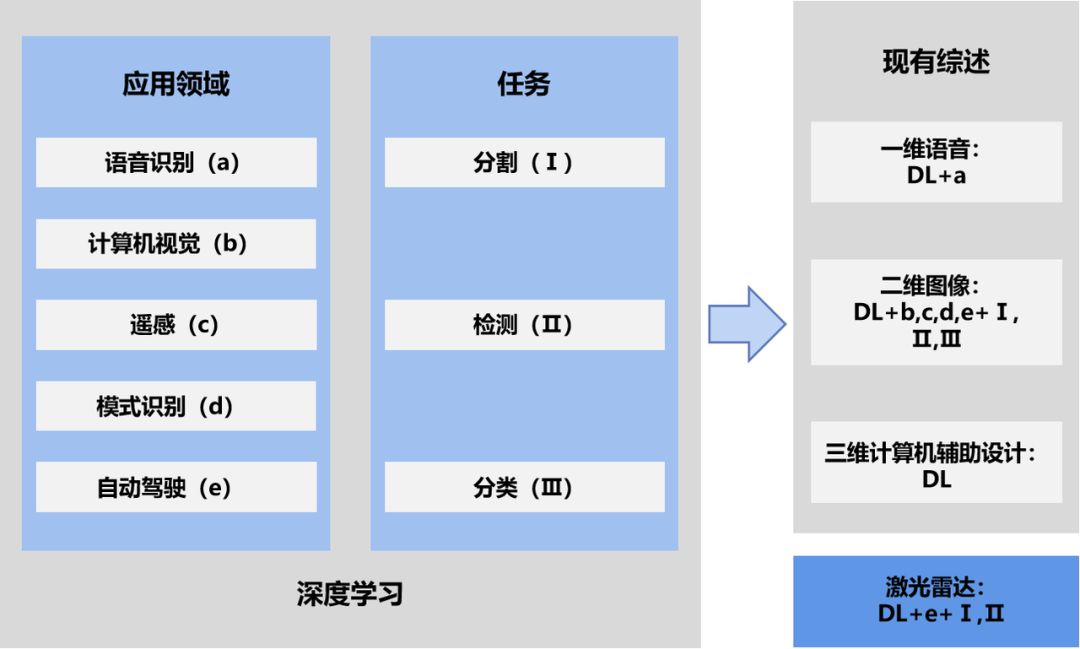
图1 现有的深度学习相关综述论文及其对不同任务的应用
总而言之,本文是第一篇调查LiDAR点云在使用深度学习技术的自动驾驶的分割、检测和分类任务中的应用。
当然,之前也发表过一些关于LiDAR点云的调查。有部分文章介绍了来自移动LiDAR点云的3D道路目标分割、检测和分类,但它们关注的是通用方法,而非特定于深度学习模型。本文分析了全面的3D点云表达形式、总结了应用于自动驾驶的3D目标检测方法。然而,在这些任务中应用的深度学习模型还没有得到全面的分析。因此,本文目的是对在自动驾驶领域针对特定任务(分割、检测、分类)使用 LiDAR 点云进行深度学习的系统回顾。
本文的主要贡献主要为:
1.全面且深入调查了里程碑式的3D深度模型、深度学习指标。例如自动驾驶中的分割、目标检测/定位和分类/识别、以及它们的起源和贡献。
2.全面调查了现有的、可用于训练自动驾驶中深度学习模型的LiDAR数据集。
3.详细介绍了分割、检测和分类的定量评估指标和性能比较。
4.有助于推进自动驾驶领域深度学习发展的剩余挑战和未来的研究。
Section 2 任务和挑战
/ 2.1 任务 /
在自动驾驶车辆的感知模块中,语义分割、目标检测、目标定位、目标分类(识别)是可靠导航和准确决策的基础。这些任务详细描述如下:
3D点云语义分割:点云语义分割是将输入数据聚类到多个同质区域的过程,同一区域中的点具有相同属性。每个输入点都用一个语义标签进行预测,如地面、树、建筑。该任务大致为:给定一组有序的3D点X={x1,x2,xi,···,xn},xi ϵ R3以及一个候选标签集Y={y1,y2,···,yk},用k个语义标签中的其中一个来分配每个输入点xi。分割结果可进一步支持目标检测和分类,如图2(a)所示。
3D目标检测(定位):目标检测是指给定任意点云数据,其可以检测和定位预先定义的类别实例(如汽车、行人、骑自行车的人,如图2(b)所示),并返回其几何3D位置、方向和语义实例标签。这些信息用一个紧密包围被检测目标的3D边界框来粗略表示。该3D边界框的表示通常为(x,y,z,h,w,l,θ,c),其中(x,y,z)表示目标(边界框)中心位置,(h,w,l)表示宽度、长度和高度,θ为目标方向。方向是指将检测到的目标与场景中的实例对齐的刚性变换,是x、y和z方向的平移以及围绕这三个轴的旋转。C表示该目标(边界框)的语义标签。
3D目标分类(识别):目标分类是指给定多组点云,其可以确定该组点所属的类别(例如,杯子、表格或汽车,如图2(c)所示)。3D目标分类的任务大致为:给定一组3D有序点X={x1,x2,xi,···,xn},xi ϵ R与和一个候选标签集Y={y1,y2,···,yk},用k标签中的一个分配整个点集X。
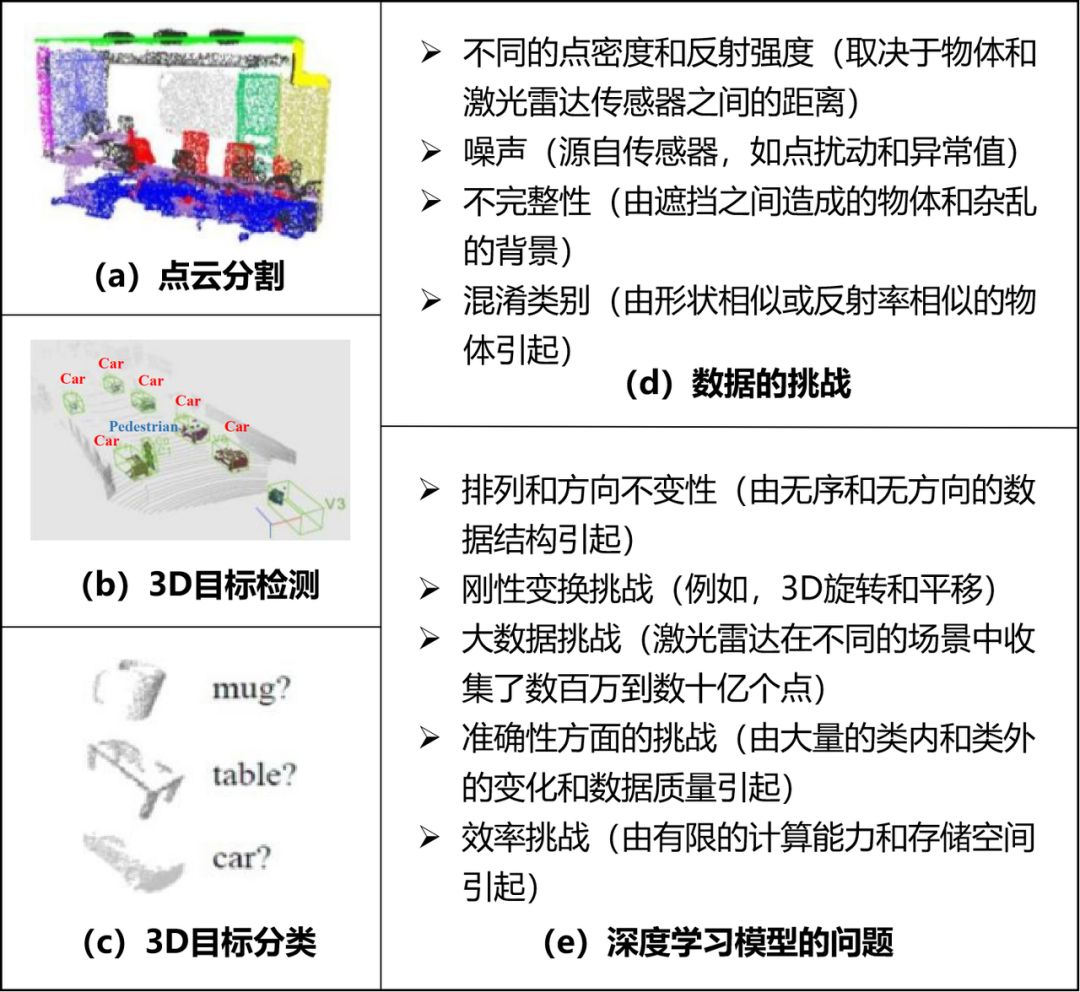
图2 3D点云上基于深度学习的应用程序相关的任务和挑战:(a)点云分割、(b)3D目标检测、(c)3D目标分类,(d)LiDAR点云数据上的挑战、(e)深度学习模型的问题
/ 2.2 挑战与问题 /
对于具有鲁棒性的和辨别性的自动驾驶汽车而言,使用深度学习对其进行分割、检测和分类的话,目前需要解决的几个挑战和问题如图2所示。传感条件和无约束环境导致了对数据的挑战,针对不规则的数据格式与识别准确性、高效率的要求,文章提出了深度学习模型需要解决的问题。
(1)LiDAR点云上的挑战:
感知方面的传感条件和无约束环境对目标外观有显著影响,在不同的场景或实例中捕获的目标存在一系列差异。即使在同一场景中,扫描时间、位置、天气条件、传感器类型、感知距离和背景都会导致这些类内差异。
以下条件都会对LiDAR点云数据中的类内和类外目标差异产生显著影响:
点密度和反射强度多样化(Diversified point density and reflective intensity):LiDAR的扫描模式决定了其密度和强度对于目标差异很大。这两个特性的分布高度取决于目标与LiDAR传感器之间的距离。此外,LiDAR传感器的能力、扫描的时间限制和所需的分辨率也影响了它们的分布和强度。
噪声(Noisy):所有传感器都有噪声。噪声的种类包括点扰动和异常值。这意味着一个点有可能是在被采样点周围的一个一定半径的球体内(扰动),或者它可能出现在空间中的一个随机位置。
不完整性(Incompleteness):由LiDAR获得的点云数据通常是不完整的。这主要是由于城市场景中,目标之间存在的遮挡,杂乱的背景和并不令人满意的材料表面反射率。这类问题在移动目标的实时捕获中非常严重,使这些目标存在较大的空隙和严重的采样不足。
混乱的类别(Confusion categories):在自然环境中,形状相似或反射率相似的目标会对目标的检测和分类产生干扰。例如,一些人造目标(如商业广告牌)与交通标志的形状和反射率比较相似。
(2)3D深度学习模型存在的问题:
不规则的数据格式以及任务对准确性和效率的要求给深度学习模型带来了一些新的挑战。在设计和构建3D深度学习模型框架时应解决以下问题:
排列和方向不变性(Permutation and orientation invariance):相比于2D网格像素,LiDAR点云是一组不规则、没有特定方向的点。在同一组N个点内,网络应该提供N!个排列来保持一致性。此外,点集的方向是缺失,这对目标模式识别提出了很大的挑战。
刚性转换挑战(Rigid transformation challenge):点集之间存在各种刚性变换,如3D旋转和3D平移等,这些转换不应影响网络的性能。
大数据挑战(Big data challenge):LiDAR在不同的城市或农村环境中收集数百万到数十亿点。例如,在Kitti数据集中,3D Velodyne激光扫描仪捕获的每一帧包含100k个点。最小的收集场景有114帧,有超过1000万的点。如此数量的数据给数据存储带来了困难。
准确性挑战(Accuracy challenge):准确感知道路目标对于自动驾驶汽车至关重要。然而类内和类外目标的变化以及数据质量会影响感知准确性。例如,同一类别中的目标具有一组不同的实例(不同的材料、形状和大小)。此外,一个好的3D深度学习模型应该对不均匀分布、稀疏和缺失的数据具有鲁棒性。
效率挑战(Efficiency challenge):与图像相比,处理大量的点云会产生较高的计算复杂度和时间成本。而自动驾驶汽车上的计算设备的计算能力和存储空间是有限的。因此,一个高效和可扩展的深度网络模型是至关重要的。
Section3 数据集和指标评价
/ 3.1 Datasets 数据集 /
数据集为基于深度学习网络进行3D数据应用的快速开发铺平了道路。可靠的数据集有两种作用:①为竞争算法提供比较;②用于推动该领域向更复杂和更具挑战性的任务发展。
随着LiDAR在自动驾驶、遥感、摄影测量等多个领域的应用日益广泛,具有数百万点甚至更多的大规模点云数据集正在兴起。这些数据集加速了在点云分割、3D目标检测和分类领域的关键突破和不可预测的性能。除了动态LiDAR数据外,还采用了静态LiDAR通过地面激光扫描 (TLS) 获取的一些判别性数据集,因为它们提供了高质量的点云数据。
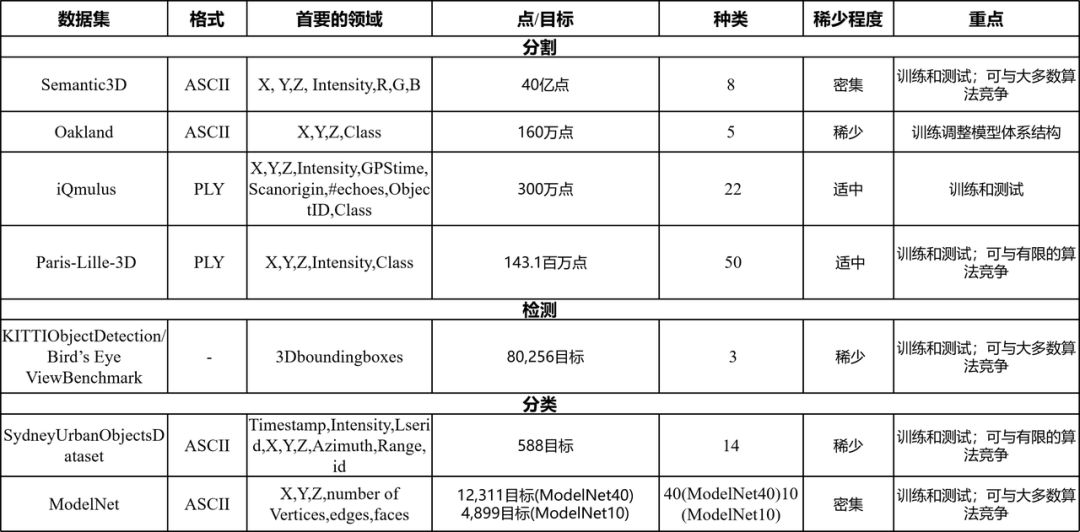
如表一所示,研究将现有的数据集根据本文的主题重新调整,将其分为三种类型:基于分割的数据集、基于检测的数据集、基于分类的数据集,此外用于自动驾驶长期自治(Long-Term Autonomy)数据集也在综述总结范围内。
表1 对现有的LiDAR数据集的调查
(1)基于分割的数据集
Semantic 3D:Semantic 3D是现有最大的用于户外场景分割任务的LiDAR数据集,拥有超过40亿个点,覆盖面积约为11万平方米。这个数据集被标注为8个类别,并被分成几乎相同大小的训练集和测试集。这些数据是由具有高测量分辨率和覆盖长测量距离的静态LiDAR获得的。该数据集的挑战主要来自于大规模点云、不均匀分布的点密度和严重的遮挡。为了拟合高计算量算法,引入了一个【reduce-8】数据集进行训练和测试,该数据集与Semantic3D相比共享相同的训练数据,但测试数据更少。
Oakland 3-D Point Cloud Dataset:与上述两个数据集相比,该数据集是在年初获得的。配备了LiDAR的移动平台被用于扫描城市环境,产生了大约130万个点,每10万个点被分成一个验证集。整个数据集被分为5类:电线、植被、地面、杆/树干和立面。该数据集很小,适用于轻量级的网络。此外,该数据集可以用于测试和调整网络架构,而无需在其他数据集上进行最终训练之前花费大量训练时间。
IQmulus & TerraMobilita Contest:该数据集由巴黎城市环境中的移动LiDAR系统获得。在这个数据集中,有超过3亿个点,覆盖了10公里的街道。这些数据被分成10个独立的区域,并被标注为20多个精细类。但该数据集也有严重的遮挡问题。
Paris-Lille-3D:与Semantic3D相比,Paris-Lille-3D包含的点更少(1.4亿点),覆盖面积更小(5.5万平方米)。该数据集的主要区别在于其数据是由一个移动激光雷达系统在巴黎和里尔两个城市的采集的。因此,与Semantic3D相比,该数据集中的点是稀疏的,且测量分辨率相对较低。但该数据集更接近于自动驾驶汽车获得的LiDAR数据。整个数据集被完全注释到50个类中,不均匀地分布在三个场景中:Lille1,Lille2,和Paris。为了简单起见,这50个类被组合成10个粗类以进行挑战。
(2)基于检测的数据集
KITTI目标检测/鸟瞰视角 Benchmark(KITTI Object Detection/Birds Eye View Benchmark):与上述针对分割任务的LiDAR数据集不同,KITTI数据集来自于自动驾驶平台,其使用摄像头、LiDAR、GPS/IMU惯性导航系统记录6小时的驾驶。因此,除LiDAR数据外,该数据集还提供了相应的图像数据。目标检测和鸟瞰视角 的benchmark都包含7481张训练图像、7518张测试图像以及相应的点云。由于移动扫描模式,该benchmark中的LiDAR数据高度稀疏,只有三类目标有边界框的标记:汽车、行人和骑自行车的人。
(3)基于分类的数据集
悉尼城市目标数据集:该数据集包含了一组在澳大利亚悉尼的CBD用LiDAR扫描的一般城市道路目标。数据集中有588个标记目标,共14类,如车辆、行人、标志和树木。整个数据集被分成四个部分进行训练和测试。与其他LiDAR数据集类似,该数据集中收集的目标是稀疏的,形状不完整。该数据集很小,对于分类任务并不理想,但由于繁琐的标注过程的限制,它仍是最常用的Benchmark。
ModelNet :该数据集是现有的最大的3D目标识别的3D Benchmark。与悉尼城市目标数据集不同,该数据集包含由LiDAR传感器采集的道路目标,该数据集由点密度均匀分布的CAD模型中的一般目标和完整的形状组成。在660个类别(如汽车、椅子、时钟)中,大约有13万个带有标签的模型。最常用的Benchmark是含40个通用目标的ModelNet 40和含10个通用目标的ModelNet 10。由于可承受的计算负担和时间,里程碑式的3D深度学习架构通常在这两个数据集上进行训练和测试。
自动驾驶长期自治(Long-Term Autonomy):为了解决长期自治(long-term:同一个场景,建图的时间、光照、季节条件和定位的时间、光照条件都可能不同,例如夏天建的图,到了冬天,定位系统也要能识别,阴天建的图,光照好的天气下定位系统也能识别。因此需要实现自动驾驶在不同光照与环境变化中的“Long-Term Localization”任务)的挑战,Maddern等人提出了一个新的自动驾驶数据集。他们历时一年,在英国牛津中部穿越1000公里,收集图像、LiDAR和GPS数据。这使得他们能够在不同的光照、天气和季节条件下,用动态的目标和建筑来捕获不同的场景外观。这样的长期数据集可深入调查阻碍自动驾驶汽车实现的问题,如在一年种的不同时间实现定位。
/ 3.2 Evaluation Metrics 评价指标/
为了评估这些所提出的方法的性能,针对这些任务,我们提出了如表二所总结的几个指标:分割、检测和分类。这些度量标准的细节如下所示。
表2 用于3D点云分割、检测/定位和分类的评估指标
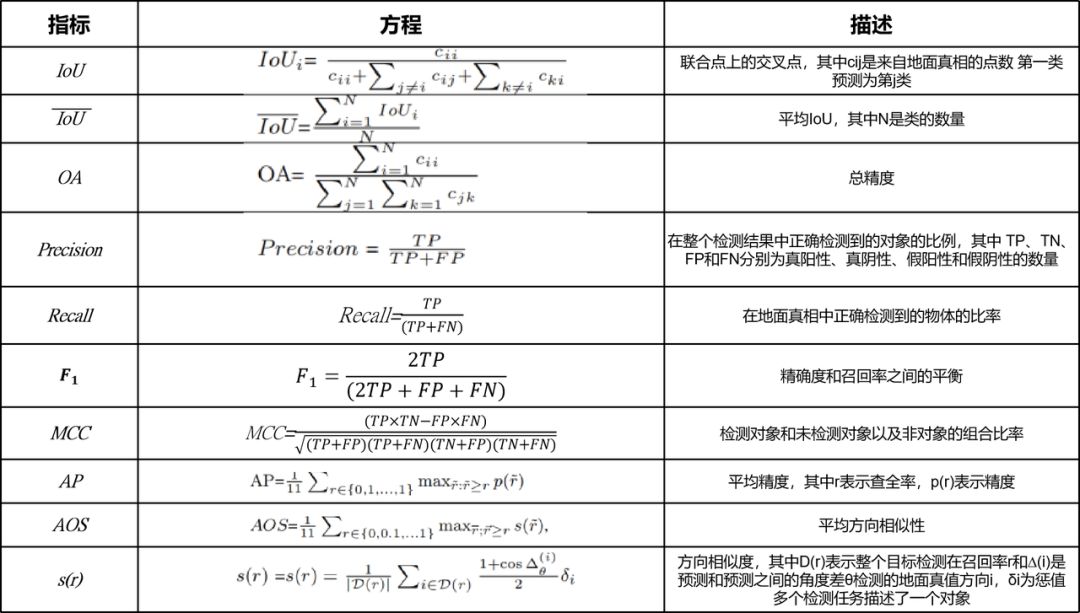
对于分割任务,最常用的评估度量是联合交叉点(IoU)度量、 和总体精度(OA)。IoU定义了目标掩模和预测输出之间的重叠百分比。
对于检测和分类任务,可以对结果进行区域综合分析。精度、召回率、F1分数和马修斯相关系数(MCC)常用来评价性能,精度表示正确检测目标在整个检测结果中的比例,召回率为正确检测目标在真实数据中的百分比,F1分数表示精度与召回率之间的平衡,MCC为检测的和未检测的目标和非目标的组合比率。
对于3D目标定位和检测任务,最常用的指标是:平均精度(AP3D)和平均方向相似度(AOS)。通过计算超过预定义值的平均有效边界框重叠部分,利用平均精度来评估定位和检测性能。对于方向估计,平均计算具有不同阈值的有效边界框重叠的方向相似度来表示性能。
Section 4 一般的3D深度学习模型
在本节中,我们将回顾与3D数据相关的一些里程碑式深度学习框架。这些框架是解决Section 2中定义的问题的先驱,同时其稳定高效的性能,也使其成为适合检测、分割和分类任务的骨干框架。虽然LiDAR获得的3D数据通常以点云的形式出现,但采用何种点云表达形式以及使用什么深度学习模型进行检测、分割和分类仍然是一个开放的问题。现有的3D深度学习模型主要以体素网格、点云、图和2D图像来处理点云。在本节中,我们将详细分析这些模型的框架、属性和问题。
/ 4.1 Voxel-based models 基于体素的模型 /
传统上,卷积神经网络(CNNs)是主要应用于具有规则结构的数据,如二维像素阵列。因此,为了将CNNs应用于无序的3D点云数据,这些数据被划分为具有一定大小的规则网格,以描述数据在3D空间中的分布。通常,网格的大小与数据的分辨率有关。
基于体素的模型优点是,它可以通过将被占用的体素分类(分为可见、遮挡和自遮挡等几种类型)进而而对3D形状和视点信息进行编码。此外,3D卷积(Conv)和池化操作(pooling operations)可以直接应用于体素网格中。
3DShapeNet(图3)是利用卷积深度置信网络开发3D体素数据的先驱。利用二进制变量的概率分布来表示3D体素网格的几何形状。然后将这些分布输入到主要由三个Conv层组成的网络中。该网络最初逐层进行预训练,然后用生成微调过程进行训练。输入层和卷积层基于对比散度进行建模,输出层基于快速持续的对比散度进行训练。训练结束后,输入测试数据与单个深度图一起输出,然后转换为体素网格。ShapeNet在低分辨率体素方面有显著结果。然而,随着输入数据大小或分辨率的增加,计算成本呈三次方增加,这限制了该模型在大规模或密集点云数据中的性能。此外,来自数据中的多尺度和多视图信息没有也得到充分利用,会阻碍输出性能。
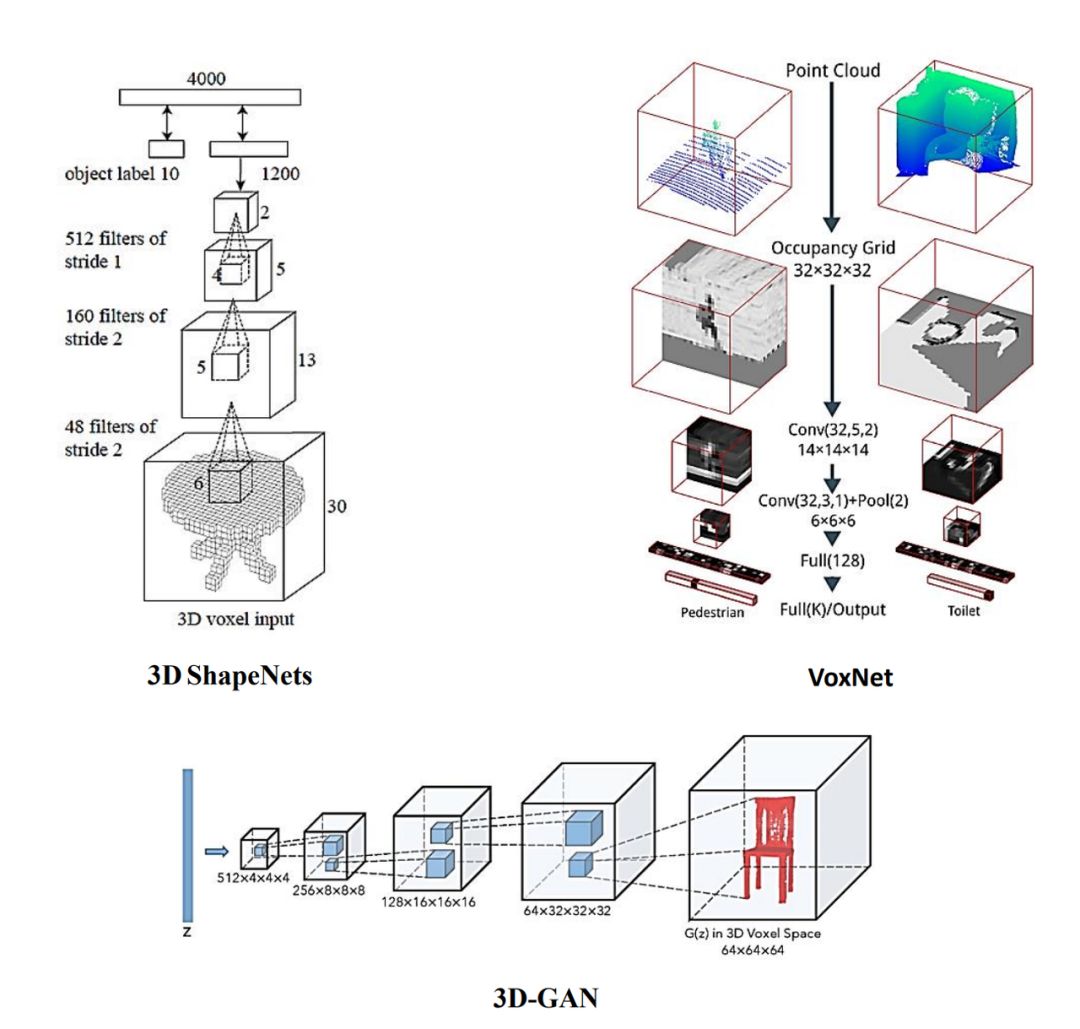
图3 3D ShapeNet、VoxNet、3D-GAN的架构
VoxNet(图3)使用基于体素数据表示的三维卷积进行3D目标检测。用随机变量的3D网格表示的占用网格来显示环境的状态。然后使用概率估计来先验的估计这些网格的占用率。对二进制占用网格、密度网格和命中网格三种不同的占用网格模型进行了实验,以选择最佳模型。该网络框架主要由卷积层、池化层和全连接(FC)层组成。ShapeNet和VoxNet都在训练中使用了旋转增强功能。与ShapeNet相比,VoxNet的架构更小,参数少于100万。然而,并不是所有的占用网格都包含有用的信息,有时候只会增加计算成本。
3D-GAN(图3)结合了生成对抗网络(GAN)和体素卷积网络的优点来学习3D目标的特征。该网络由一个生成器和一个鉴别器组成。由于生成-对抗准则,对抗鉴别器在捕获两个3D目标之间的结构变化上具有优势。采用生成-对抗损失有助于避免可能的标准依赖性过拟合(生成器试图混淆鉴别器)。生成器和鉴别器都由五个体素全卷积层组成,该网络在3D目标识别中提供了一个无监督训练的强大3D形状描述符,但数据的密度影响了最优特征捕获的对抗鉴别器的性能。因此,该自适应方法适用于均匀分布的点云数据。
总之,这种一般的基于体素的3D数据表示方法有一些局限性:
- 第一,并不是所有的体素表达形式都是有用的,因为它们包含了扫描环境中占用和非占用的部分。因此,在这个无效的数据表示中,对计算机存储的高需求实际上是不必要的。
- 第二,网格的大小难以设置,这影响了输入数据的规模,可能会破坏点之间的空间关系。
- 第三,计算量和内存需求随着分辨率的增加而不断增长。因此,现有的基于体素的模型保持在较低的3D分辨率,最常用的尺寸是30*30*30。
一种更高级的基于体素的数据表达形式是基于八叉树的网格,它使用自适应大小将3D点云划分为立方体。它是一个分层的数据结构,递归地将根体素分解为多个叶体素。
OctNet利用了输入数据的稀疏性。观察到目标边界在不同层的网络生成的所有特征图中产生最大响应的概率最高,研究者根据输入数据的密度将3D空间分层划分为一组不平衡的八叉树。具体来说,具有点云的八叉树节点在其域中被递归地分割,以树的最佳分辨率结束。因此,叶节点的大小是不同的。对于每个叶节点,那些激活它们组成体素的特征将被合并和存储。然后对这些树进行卷积处理。《Octree generating networks: Efficient convolutional architectures for high-resolution 3Doutputs》一文中通过学习八叉树的结构和每个网格的表示占用值来构建深度模型。与基于体素的模型相比,这种基于八分树的数据表示大大减少了深度学习架构的计算和内存资源,在高分辨率3D数据中获得了更好的性能。然而,八叉树数据的缺点与体素相似,两者都不能利用3D目标的几何特征。
/ 4.2 Point clouds based models 基于点云的模型 /
与基于体素3D数据表示不同,点云数据可以保存3D地理空间信息和内部局部结构。此外,以固定步幅扫描空间的体素模型也会受到局部感受野的约束。但对于点云,输入数据和度量决定了感受野的范围,具有较高的效率和准确性。
PointNet(图4,直接将 3D 点云用于深度学习模型的先驱)通过MLP层独立学习每个点的空间特征,然后通过最大池化聚集其特征。点云数据直接输入到Pointnet,PointNet预测每个点标签或每个目标标签。在PointNet中,设计了空间变换网络和一个对称函数来提高点云序列的置换不变性,通过网络学习每个输入点的空间特征然后将学习到的特征组合在整个点云区域内。PointNet在3D目标分类和分割任务中取得了出色的性能。但是,单个点的特征通过最大池化进行分组和聚合,并不能保留局部结构。因此,PointNet对细粒度的模式和复杂的场景并不鲁棒。
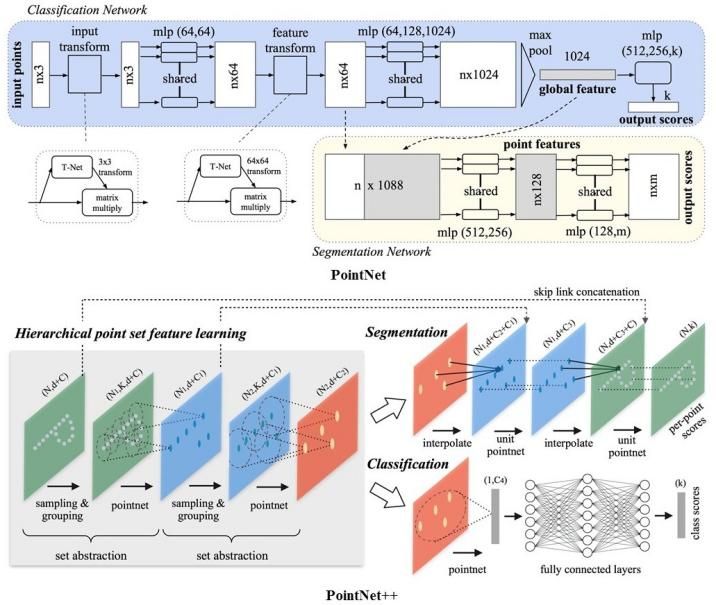
图4 PointNet和PointNet++架构
PointNet++(图4)弥补了PointNet中的局部特征提取问题。在原始的无序的输入的点云中,这些点最初使用欧几里德距离度量被划分为重叠的局部区域。这些分区被定义为这个度量空间中的邻域球,并用质心位置和尺度标记。为了在整个点集上对点进行均匀采样,采用了最远点采样(FPS)算法。利用k近邻算法(KNN)或球查询搜索方法(query-ball searching methods)从选定点周围的小邻域中提取局部特征。这些领域被聚集成更大的集群,并通过PointNet网络来提取高级特征。重复采样和分组模块,直到学习到整个点的局部特征和全局特征,如图4所示。该网络在分类和分割任务上优于PointNet网络,提取了不同尺度下的点的局部特征。然而,来自不同采样层中的局部邻域点的特征是以一种孤立的方式学习的。此外,基于PointNet的PointNet++的高级特征提取操作不能保留局部邻域点之间的空间信息。
Kd-networks(图5)使用kd-tree来创建输入点的顺序。这与PointNet和PointNet++不同,因为它们都使用对称函数来解决排列问题。Klokov等人利用沿坐标轴的最大点坐标范围,递归地将一定大小的点云N=2D分割成自上而下的子集,构建一个kd-tree。该kd-tree以一个固定的深度结束。在这个平衡树结构中,使用kd-network计算每个节点的向量表示,该向量表示沿某一轴的细分。然后利用这些表示来训练一个线性分类器。该网络在小目标分类方面的性能优于PointNet和PointNet++。然而,它对旋转和噪声并没有鲁棒性,因为这些变化会导致树状结构的变化。此外,它缺乏重叠的感受领域,从而降低了叶节点间的空间相关性。
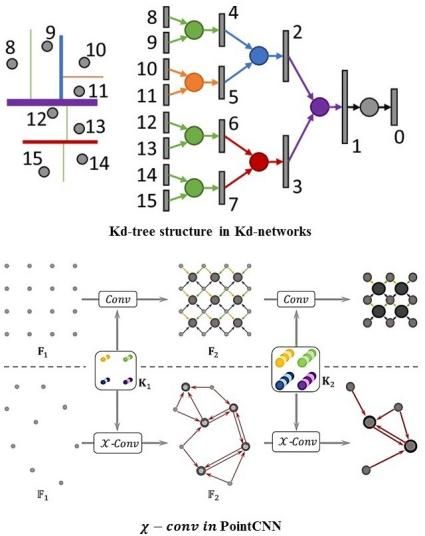
图5 PointCNN中Kd-networks和χ-Conv中的Kd-treed结构
PointCNN(图5)基于x-Conv运算解决输入点置换和变换问题,如图5所示。他们提出了x变换,它是通过加权输入点的特征并将输入点排列成一个潜在的和具有潜在规范的顺序,来从输入点学习到的。然后将传统的卷积算子应用于学习到的χ变换特征。这些空间-局部上的相关性对每个局部范围内的特征进行聚合,构建一个分层的CNN网络体系结构。然而,该模型仍然没有利用不同几何特征的相关性及其对结果的区分信息,从而限制了性能。
基于点云的深度学习模型主要关注于解决置换问题。尽管他们在局部尺度上独立地处理点以保持置换不变性。然而,这种独立性忽略了点及其相邻点之间的几何关系,导致了局部特征缺失的根本限制。
/ 4.3 Graphs-based models 基于图形的模型 /
图形是一种非欧几里得数据结构,可以用来表示点云数据。它们的节点对应于每个输入点,边表示每个点邻居之间的关系。图形神经网络以迭代的方式传播节点状态直到平衡。随着卷积神经网络的发展,出现了一种用于三维数据的增量图卷积网络。这些图卷积网络在频谱和非频谱(空间)域上直接在图上定义卷积,作用于空间近邻组。基于图的模型的优点是利用了点及其邻居之间的几何关系。因此,从每个节点上的分组边缘关系中提取出更多的空间局部相关特征。但是,构建基于图的深度模型还存在两个挑战:
首先,定义一个适合动态大小邻域的算子,并保持CNNs的权重共享方案。
其次,利用每个节点的相邻节点之间的空间关系和几何关系。
SyncSpecCNN,利用graph Laplacian的谱特征分解生成一个应用于点云的卷积滤波器。Yi等人基于这两个考虑因素构建了SyncSpecCNN:第一个是系数共享和多尺度图分析;第二个是在相关但不同的图之间的信息共享。他们通过构造谱域的卷积操作来解决这两个问题:欧几里得域的点集信号由图节点上的度量定义,欧几里得域的卷积操作与基于特征值的尺度信号有关。实际上,这种操作是线性的,只适用于由图拉普拉斯向量的特征向量生成的图权值。尽管SyncSpecCNN在3D形状零件分割方面取得了优异的性能,但它也有几个局限性:
- 依赖基础:学习到的频谱滤波器系数不适用于具有不同基的另一个域。
- 计算费用昂贵:频谱滤波是基于整个输入数据进行计算的,需要具有较高的计算能力。
- 缺少局部边缘特征:局部图包含有用的和独特的局部结构信息,没有被利用。
边缘条件卷积(ECC),在构造基于空间域内的图信号的卷积滤波器时考虑了边缘信息。顶点邻域的边缘标签被调节生成Conv滤波器权值。此外,为了解决基相关问题,他们动态地将卷积算子推广到具有不同大小和连通性的任意图。整个网络遵循前馈网络的共同结构,包括交错的卷积和池化,然后是全局池化和FC层。因此,从这些堆叠的层中不断提取来自局部邻域的特征,这增加了感受野。虽然边缘标签对于特定的图是固定的,但学习到的解释网络可能在不同的层中有所不同。ECC学习局部邻域的动态模式,具有可扩展性和有效性。但是,计算成本仍然很高,并且不适用于具有连续边缘标签的大规模图。
DGCNN,也构造了一个局部邻域图来提取局部几何特征,并在连接每个点的邻域对的边上应用了类似卷积的运算,称为EdgeConv,如图6所示。与ECC不同,EdgeConv对每个层的输出使用类似Conv的操作动态更新给定的固定图。因此,DGCNN可以学习如何提取局部几何结构和分组点云。该模型以n个点作为输入,然后求出每个点的K个邻域,计算出每个EdgeConv层中该点及其的K个邻域之间的边缘特征。与PointNet架构类似,在最后一个EdgeConv层中卷积的特征被全局聚合以构建一个全局特征,而所有的EdgeConv输出都被视为局部特征。局部特征和全局特征被连接起来以生成结果分数。该模型从点邻域中提取出独特的边缘特征,可应用于不同的点云相关任务。然而,边缘特征的固定大小限制了模型在面对不同的尺度和分辨率的点云时的性能。
ECC和DGCNN提出了关于图节点及其边缘信息的一般卷积,即关于输入特征的各向同性。然而,并不是所有的输入特性对其节点的贡献都是相同的。因此,引入了注意机制来处理可变大小的输入,并关注节点邻域点中最相关的部分来做出决策。
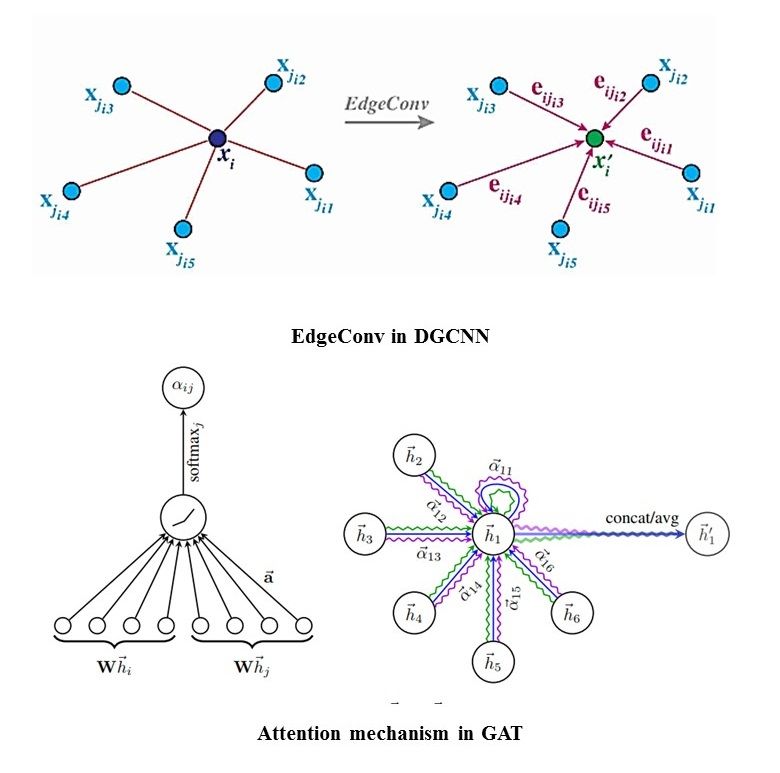
图6 DGCNN中的EdgeConv与GAT中的注意机制
图形注意网络(GAT),GAT背后的核心见解是通过利用自注意力机制,为图中每个邻域点分配不同的注意力权重,以计算每个点的隐藏表示。在一组作为输入的节点特征中,对每个节点应用一个由权重矩阵参数化的共享线性变换。然后在节点上应用一个自注意机制,即如图6所示的共享注意机制,来计算注意系数。这些系数分别表示对应节点的邻居特征的重要性,并进一步归一化,使它们在不同节点之间具有可比性。这些局部特征根据注意权重进行组合,形成每个节点的输出特征。为了提高自我注意机制的稳定性,采用多头注意力进行k个独立的注意力策略,然后将其连接在一起,形成每个节点的最终输出特征。这种注意架构是有效的,可以通过给相邻节点分配不同的权重来为每个图节点提取细粒度的表示。然而,该方法在计算平均权值时,没有考虑邻居之间的局部空间关系。为了进一步提高其性能,Wang等人提出了图注意卷积(GAC),通过考虑不同的相邻点和特征通道来生成注意权值。
/ 4.4 View-based models 基于视觉的模型 /
最后一种MLS数据表示类型是从不同方向的3D点云中获得的2D视图。通过投影的2D视图,可以利用传统的卷积神经网络(CNN)和图像数据集上的预训练网络,如AlexNet、VGG、GoogLeNet、ResNet。与基于体素的模型相比,这些方法可以通过对感兴趣的目标或场景进行多视图,然后融合或投票对输出进行最终预测,从而提高不同3D任务的性能。与上述三种不同的3D数据表示相比,基于视图的模型可以达到接近最优的结果,如表3所示。Su等人的实验表明,与点云和体素数据表示模型相比,即使不使用预训练过的模型,多视图方法也具有最优的泛化能力。与3D模型相比,基于视图的模型的优势可以总结如下:
效率:与点云或体素网格等3D数据表示相比,减少的一维信息可以大大降低计算成本,但提高了分辨率。
利用已建立的2D深度架构和数据集:开发良好的2D深度学习体系结构可以更好地从投影的2D视图中提取局部和全局信息。此外,现有的2D图像数据库 (如ImageNet)可以用于训练2D深度学习架构。
表3 基于四类点云数据表达形式的深度学习架构总结
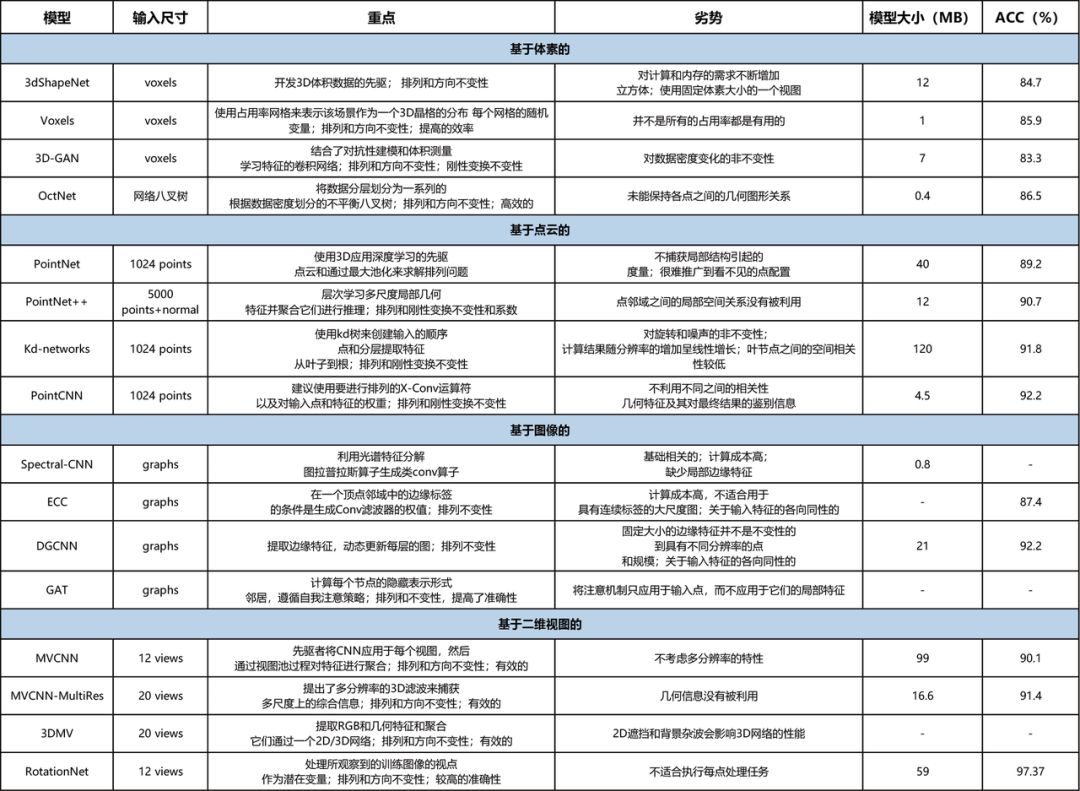
MVCNN,是利用2D深度学习模型来学习3D的先驱。使用视图池化层提取3D目标的多个视图,无需特定顺序。本文提出并测试了两种不同的CNN模型。第一个CNN模型通过在目标周围放置12个相同距离的虚拟摄像机作为输入,获取12个视图,而第二个CNN模型以相同的方式获取80个视图。这些视图首先单独学习,然后通过最大池化操作融合,提取整个3D形状的所有视图中最代表性的特征。与体素的数据表达形式相比,该网络有效且高效。但最大池化操作只考虑了最重要的视图,并从其他视图中丢弃信息,这并不能保存全面的视觉信息。
MVCNN-MultiRes,由Qi等人提出,以改进多视图CNNs。与传统的视图渲染方法不同,3D体素是通过基于各向异性探测核的卷积运算将3D形状投影到2D的。将多方向池化结合在一起,提高了3D结构的捕获能力。然后应用MVCNN对2D项目进行分类。与MVCNN相比,引入了多分辨率的3D滤波来捕获多尺度信息。球体渲染在不同的体素分辨率下进行,以实现视图不变,提高对潜在噪声和不规则性的鲁棒性。与MVCNN相比,该模型在3D目标分类任务中取得了更好的效果。
3DMV,结合了几何数据和图像数据作为输入以训练一个融合的3D深度架构。首先从图像数据中提取的特征图,然后映射到从可微反投影层得到的体素网格数据中提取的3D特征中。由于多个视图之间存在冗余信息,因此采用多视图池化的方法从这些视图中提取有用的信息。该网络在3D目标分类方面取得了显著的效果。然而,与单独使用LiDAR点或RGB图像的模型相比,该方法的计算成本更高。
RotationNet,是根据以下假设提出的,即当观察者从一组完整的多视点图像中观察目标时,应该识别观察方向,以正确推断目标类别。因此,一个目标的多视图图像被输入到RotationNet,RotationNet输出它的姿态和类别。RotationNet最具代表性的特点是,它将作为训练图像的观察视点视为潜在变量。然后基于未对齐的目标数据集对目标姿态进行无监督学习,可以消除姿态归一化过程,以减少噪声和形状的个体变化。整个网络为一个可微MLP网络,最后一层是softmax。输出是视点类别的概率,它对应于每个输入图像的预定义的离散视点。这些可能性由选定的目标姿态进行优化。
然而,基于2D视觉的模型也存在一些局限性:
- 首先,从3D空间到二维视图的投影可能会丢失一些与几何相关的空间信息。
- 第二个是多个视图之间的冗余信息。
/ 4.5 3D数据处理与增强 /
由于大量的数据和繁琐的标注过程,目前可靠的3D数据集有限。更好地利用深度网络的体系结构,提高模型的泛化能力,通常进行数据增强。增强可以同时应用于数据空间和特征空间,而最常见的增强是在原始数据上进行的。这种类型的增强不仅可以丰富数据的变化,而且还可以通过对现有的3D数据进行转换来生成新的样本。有几种类型的转换,如平移、旋转和缩放。数据增强的要求如下:
- 原始数据和增强数据之间必须存在相似的特征,如形状等;
- 原始数据和增强数据之间必须存在不同的特征,如方向等。
基于现有的方法,点云的经典数据增强可以总结为:
- 根据预先定义的概率镜像x轴和y轴;
- 按照一定时间和角度绕z轴旋转;
- 一定范围内随机(均匀)高度或位置抖动;
- 按照一定比例的随机尺度;
- 随机遮挡或在预定义的比率范围内的随机下采样点;
- 在预定义的比例范围内的随机伪影或随机下采样点;
- 随机添加噪声,遵循一定的分布,随机添加到点的坐标和局部特征。
Section 5 应用
LiDAR点云在自动驾驶汽车上的应用可以分为三类:3D点云分割、3D目标检测(定位)和3D目标分类(识别)。这些任务的目标各不相同,例如,分割侧重于每一个点的标签预测,而检测和分类集中于集成点集的标记。但在特征嵌入和网络构建之前,它们都需要利用输入点的特征表示。
文章首先对所有这三个任务在深度学习架构中应用的输入点云特征(例如局部密度和曲率)进行调查。这些特征是3D空间中特定3D点或位置的表示,基于该点周围提取的信息描述几何结构和特征。这些特征可以分为两种类型:一种是直接来自于传感器(如坐标和强度等),称其为直接点特征表示;第二种是从每个点的邻域提供的信息中提取的,称其为几何局部点特征表示。
直接输入点特征表示:直接输入点特征表示主要由激光扫描仪提供,包括x、y、z坐标和其他特征(如强度、角度和返回数)。深度学习中两个最常用的特性如下:
x、y、z坐标:最直接的点特征抑制点是由传感器提供的XY Z坐标,这是指一个点在真实世界坐标中的位置。
强度:强度代表了材料表面的反射率特征,这是激光扫描仪的一个常见特征。不同的目标有不同的反射率,因此在点云中产生不同的密度。如,交通标志的强度要高于植被标志。
几何局部点特征表示:局部输入点特征嵌入点及其邻域的空间关系,在点云分割、目标检测和分类中起着重要作用。此外,搜索的局部区域可以被CNNs等操作利用。两种最具代表性和广泛使用的邻域搜索方法分别是k-最近邻(KNN)和球形邻域(Spherical neighborhood)。
通常使用上述两种邻域搜索算法从搜索区域生成几何局部特征表示。它们是由特征值(例如:η0,η1和η2(η0>η1>η2))或特征向量(例如: , , 和 )组成,这些特征值和特征向量由分解在搜索区域中定义的协方差矩阵所得。我们列出了深度学习中最常用的5个最常用的3D局部特征描述符:
局部密度:局部密度通常由选定区域中的点的数量决定。通常,随着目标到LiDAR传感器的距离增加时,点密度减小。在基于体素的模型中,点的局部密度与体素大小的设置有关。
局部法线:它在表面上的某一点上推断出法线的方向。关于法线提取的方程可以看文章《Large-scale urban point cloud labeling and reconstruction》。在《Point cloud library》中,将Ci中η2的特征向量 作为每个点的法向量。然而,在《Pointnet: Deep learning on point sets for 3d classification and segmentation》中,η0,η1和η2的特征向量都被选为pi点的法向量。
局部曲率:局部曲率定义为单位切向量改变方向的速率。表面曲率变化可以由特征分解得到的特征值来估计:曲率=η0/(η0+η1+η2)。
局部线性:局部线性是一个局部的几何特征,每个点表示其局部几何的线性:线性=(η1−η2)/η1。
局部平面性:局部平面性描述了给定点邻域的平坦度。例如,组点比树点具有更高的平面性:平面性=(η2−η3)/η1。
/ 5.1 LiDAR 点云语义分割 /
语义分割的目标是将每个点标注为其所属的一个特定语义类。对于自动驾驶分割任务,这些类可以是街道、建筑物、汽车、行人、树木或交通灯。当应用深度学习进行点云分割时,需要对小特征进行分类。然而,LiDAR 3D点云通常是大尺度的,它们的形状不规则,空间内容变化多样。在回顾近五年的相关论文时,我们根据数据表示的类型将这些论文分为三种:基于点云的模型、基于体素的模型和基于多视图的模型。基于图的模型的研究有限,因此我们将基于图的模型和基于点云的模型结合在一起来说明其范式。图7所示为每类模型的深度学习架构。
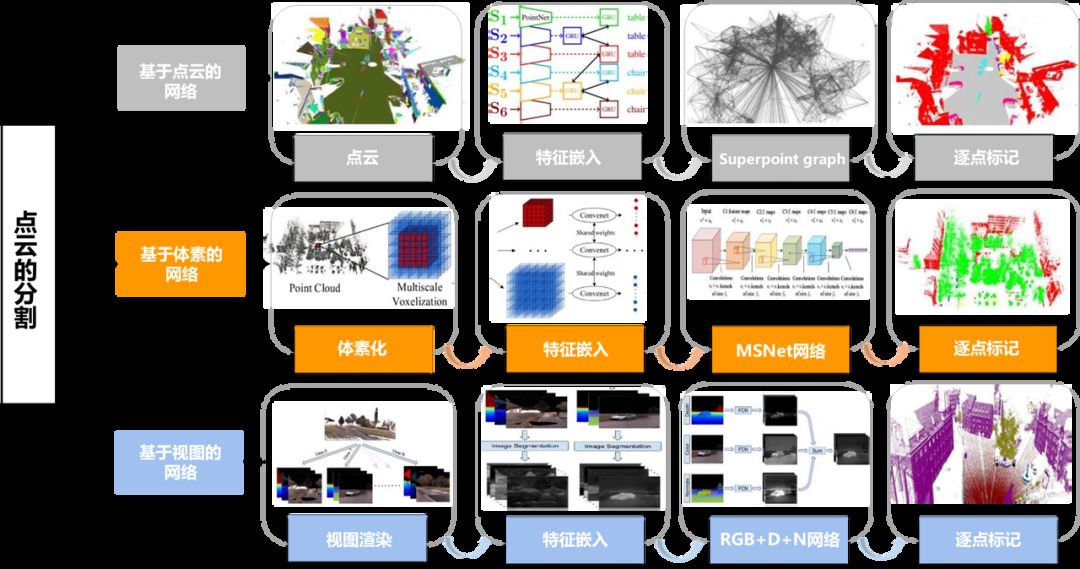
图7 基于三种不同数据表示的LiDAR点云分割的深度学习架构:基于点云的网络(以SPG为代表),基于体素的网络(以MSNet为代表),基于视图的网络(以DeePr3SS为代表)
(1)基于点云的网络:基于点云的网络主要由特征嵌入和网络构造两部分组成。在具有辨别性特征表示上,局部特征和全局特征都被证明是CNNs成功的关键。然而,为了应用传统的CNNs,无序点和无定向点的排列和定向问题需要一个具有辨别性的特征嵌入网络。此外,轻量级、有效、高效的深度网络构建是影响分割性能的另一个关键模块。
局部特征通常从邻近点中提取。最常用的局部特征是局部法线和曲率。PointNet为提高感受野设计了一个有效架构,其从无序点集中提取语义特征。在《Large-scale point cloud semantic segmentation with superpoint graphs》等文中会利用一个简化的Pointnet将局部特征从采样点集抽象为高级表示。同时,此文提出了超点图( superpoint graph,SPG),将大型3D点云表示为一组相互关联的简单形状,即创造的超点,然后在这些超点上运用Pointnet来嵌入特征。
为解决置换问题并提取局部特征,Huang等人提出了一种新的切片池化层,从输入点特征中提取局部上下文层,并输出一个有序的聚合特征序列。具体做法为:先将输入点分组为切片,再通过连接切片内的点特征来生成每个切片的全局表示。与基于点的局部特征相比,这种切片池化层的优点是计算成本低。然而,切片的大小对数据的密度很敏感。在《Splatnet: Sparse lattice networks for point cloud processing》一文中,应用双边卷积层(bilateral Conv layers,BCL)对晶体网格的占据部分进行卷积,以进行分层和空间感知特征学习。BCL先将输入点映射到稀疏晶体网格上,并对其进行卷积运算,之后为了恢复原始输入点对滤波后的信号进行平滑的插值。
为了降低计算成本,《Fully-convolutional point networks for large-scale point clouds》一文中采用编码器-解码器(encoding-decoding)框架。将从相同抽象尺度中提取的特征合并,然后通过3D反卷积进行上采样,生成所需的输出采样密度,最后通过潜在最近邻插值进行插值,以输出每点标签。但是,下采样和上采样操作很难保留边缘信息,不能提取出细粒度的特征。在《Recurrent slice networks for 3Dsegmentation of point clouds》一文中,RNNs被应用于由切片池化层生成的有序全局表示的模型依赖。与序列数据类似,每个切片都被视为一个时间戳,与其他切片的交互信息也遵循RNN中的时间戳。此操作使模型能够生成切片之间的依赖关系。
Zhang等人提出了ReLu-NN(一个四层的MLP原始结构)来学习嵌入的点特征,但对于没有辨别性特征的目标,如灌木或乔木,它们的局部空间关系并没有得到充分的利用。为了更好地利用丰富的空间信息,Wang等人构建了一个轻量级、有效的深度神经网络,利用空间池化(DNNSP)来学习点的特征。他们将输入数据聚类分组,然后应用基于距离最小生成树的池化来提取聚类点集中的点之间的空间信息。最后,使用MLP对这些特征进行分类。为了实现架构简单的实例分割和目标检测等多个任务,Wang等人提出了一个相似性组建议网络SGPN。在提取的PointNet的局部和全局点特征中,特征提取网络生成一个矩阵,然后将其划分为三个子集,每个子集通过一个Pointnet层,得到三个相似性矩阵。这三个矩阵用于生成相似度矩阵、置信图和语义分割映射。
(2)基于体素的网络:在基于体素的网络中,点云首先被体素化为网格,然后从这些网格中学习特征。最后构建深度网络,将这些特征映射到分割掩膜。
Wang等人采用多尺度体素化方法提取不同尺度下的目标空间信息,形成全面的描述。在每个尺度上,为一个给定的点,构造一个具有预设长度的相邻立方体。然后,立方体被划分为不同大小的网格体素。尺寸越小,比例越小。选择点密度和占用率来代表每个体素。这种体素化的优点是,它可以容纳不同大小的目标,而不会丢失它们的空间信息。在《Segcloud: Semantic segmentation of 3D point clouds》中,使用3D-FCNN预测每个体素的类概率,然后根据三线性插值将其传递回原始的3D点。在《Segcloud: Semantic segmentation of 3D point clouds》中,对点云进行多尺度体素化后,通过一组具有共享权值的CNNs学习不同尺度和空间分辨率的特征,最终将其融合在一起进行预测。
在基于体素的点云分割任务中,有两种方法对每个点进行标注:(1)使用由预测概率的最大参数得到的体素标签;(2)基于空间一致性进一步对点云的类标签进行全局优化。第一种方法很简单,但结果是在体素级别上提供的,不可避免地会受到噪声的影响。第二种更准确,但更复杂,需要额外的计算。因为CNN网络对空间变换固有的不变性影响了分割精度。为了提取体素数据表示的细粒度细节,在后处理阶段通常采用条件随机场(CRF)。CRFs的优点是结合低级信息,如点之间的交互,以输出多类逐点标记任务的多类推理,这补偿了CNNs无法捕获的精细局部细节。
(3)基于多视图的网络:对于基于多视图的模型,视图渲染和深度架构的构建是分割任务的两个关键模块。第一个是用于生成结构化和规则的二维网格,可以利用现有的基于CNNs的深度架构。第二个是为不同的数据构建最适合和可生成的模型。
为了同时提取局部特征和全局特征,采用了一些手工设计的特征描述符进行代表性信息提取。在《A deep neural network with spatial pooling (dnnsp) for 3-d point cloud classification》等文中,使用自旋图像描述符来表示基于点的局部特征,包含来自局部视图中目标的全局描述。在《Deep projective 3Dsemantic segmentation》一文中,通过将具有扩散函数的点投影到图像平面中,应用点扩散来生成视图图像。该点首先被投影到一个虚拟照相机的图像坐标中。对于每个投影点,存储其相应的深度值和法线值等特征向量。
一旦这些点被投影到多视点2D图像中,就可以利用一些2D深度网络,如VGG16、AlexNet、GoogLeNet和ResNet。在《A review on deep learning techniques applied to semantic segmentation》一文中,这些深度网络已经在2D语义分割中进行了详细的分析。在这些方法中,VGG16共16层。它的主要优点是使用了具有小感受野的堆叠卷积层,这产生了一个具有有限参数和增加非线性的轻量级网络。
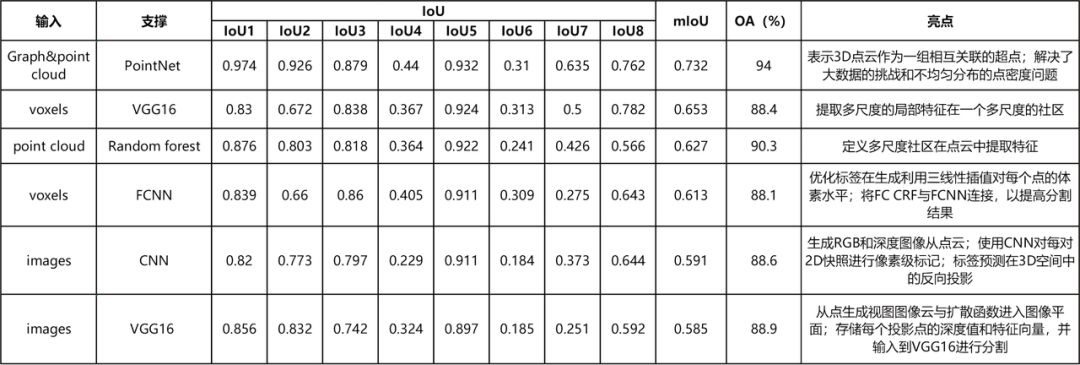
(4)点云分割的评价:由于点云体积大,这对计算能力提出了很大的挑战。研究在Reduced-8 Semantic3D数据集上测试的模型来比较它们的性能,如表4所示。Reduced-8与Semantic-8共享相同的训练数据,但只使用一小部分测试数据,这也可以适合高计算成本算法竞争。用于比较这些模型的指标是IoUi、 和OA。由于计算能力、所选择的训练数据集、模型体系结构之间的差异,这些算法的计算效率没有办法被直接报告和比较。
表4 Semantic 3D Reduced-8数据集的分割结果
/ 5.2 3D目标检测(定位) /
对LiDAR点云中3D目标的检测(定位)可以概括为候选框预测和目标预测。本文中只调查了仅限LiDAR的范式,其利用了精确的地理参考信息。总的来说,在这个范例中有两种数据表示方法:一种直接从点云来检测和定位3D目标;另一种是将3D点转换为规则网格,如体素网格或鸟视图图像以及前视图,然后利用2D探测器的结构从图像中提取目标,最后将2D检测结果反投影到3D空间,进行最终的3D目标位置估计。图8显示了上述数据表示的代表性网络框架。
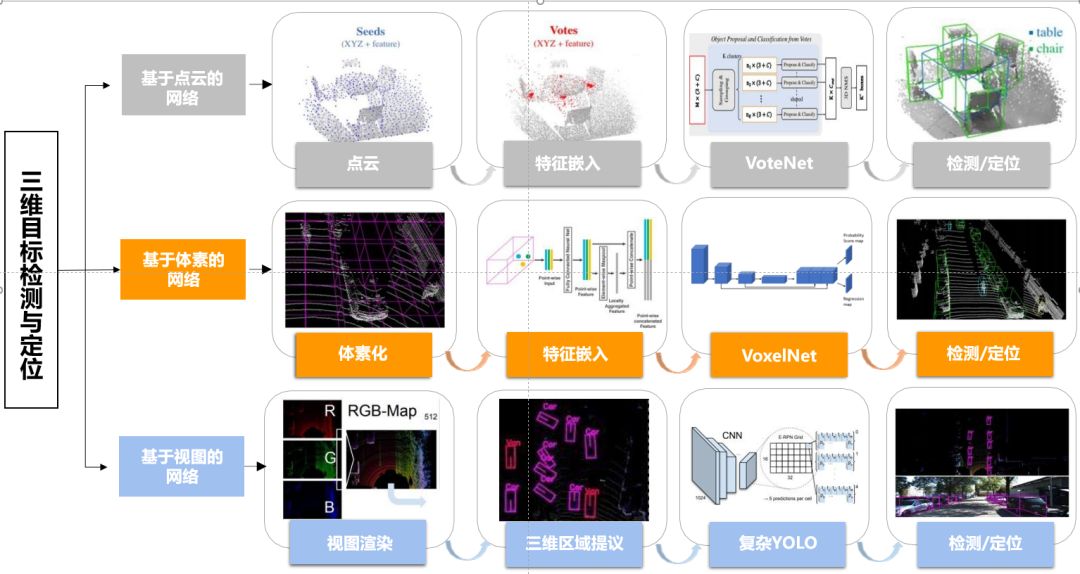
图8 基于三种不同数据表示的3D目标检测/定位的深度学习架构:基于点云的网络(以VoteNet为代表);基于体素的网络(以VoxelNet为代表);基于视图的网络(以复杂YOLO为代表)
(1)直接从点云进行3D目标检测(定位)
从稀疏和大规模点云中检测3D目标面临的挑战有:
- 检测到的目标只占据整个输入数据中非常有限一小部分。
- 3D目标的质心可以远离任何表面点,很难在一步中精确回归。
- 缺少3D目标的中心点。由于LiDAR传感器只捕捉目标的表面,3D目标的中心很可能是在空白的空间中,远离任何点。
基于此,研究者们提出了一种(从稀疏和大规模点云检测3D目标的)常用方法,其过程包括:①对整个场景进行粗略分割,然后近似提出兴趣目标的粗定位;②提取每个提出区域的特征;③通过边界框预测网络预测定位和目标类别。
在《Ipod: Intensive point- based object detector for point cloud》一文中,应用PointNet++在整个输入点云中生成每个点的特征。与《Deep learning-based classification and reconstruction of residential scenes from large-scale point clouds》一文不同的是,每个点都被认为是一个有效的候选框,它保留了定位信息。然后根据提取的基于点的建议特征以及通过增加感受野和输入点特征捕获的局部邻域上下文信息,进行局部定位和检测预测。该网络保留了更准确的定位信息,但直接在点集上操作需要更高的计算成本。
在上文提到的《Deep learning-based classification and reconstruction of residential scenes from large-scale point clouds》一文中,应用了具有三个卷积层和多个FC层的3DCNN来学习目标的辨别性和鲁棒性的特征。然后将智能的眼窗(eye window,EW)算法应用于场景。使用预训练的3DCNN来预测属于EW的点的标签。然后将评价结果输入到deep Q-network(DQN),以调整EW的大小和位置。然后通过3DCNN和DQN来评估新的EW,直到EW只包含一个目标。与传统的感兴趣区域(RoI)的边界框不同,EW可以自动重塑其大小,自动改变窗口中心,适用于不同尺度的目标。一旦确定了目标的位置,就会用学习到的特征来预测输入窗口中的目标。并基于3DCNN提取目标特征模型,然后输入残差的RNN进行类别标注。
Qi等人提出了VoteNet,一个基于Hough投票的3D目标检测深度网络。原始的点云被输入到PointNet++来学习点特征。基于这些特征,对一组种子点进行采样,并从它们的邻域特征中生成投票。然后收集这些种子来对目标中心进行聚类,并生成针对最终决策的边界框建议。与上述两种架构相比,VoteNet对稀疏和大规模的点云具有良好的鲁棒性,并且可以高精度地定位目标中心。
(2)从常规体素网格进行3D目标检测(定位)
为了更好地利用CNNs,一些方法将3D空间体素化为体素网格,用标量值表示,如从体素中提取的占用或向量数据。在《Voting for voting in online point cloud object detection》等文中,首先将3D空间离散成一个固定大小的网格,然后将每个被占用的单元转换为一个固定维的特征向量。没有任何点的非占用单元用零特征向量表示。利用二元占用率和反射率的均值和方差,以及三个形状因子来描述特征向量。为简单起见,体素化网格用长度、宽度、高度和通道4D阵列表示,用一个通道的二进制值表示相应网格中点的观测状态。Zhou等人使用预定以的距离沿XYZ坐标对3D点云进行体素化,并将每个网格中的点分组。然后提出了一个体素特征编码(VFE)层,通过结合每点特征和局部邻域特征来实现体素内的点间交互。多尺度VFE层的结合使该架构能够从局部形状信息中学习辨别性特征。
在《Voting for voting in online point cloud object detection》等文中采用投票方案对体素化网格进行稀疏卷积。这些网格,由卷积核以及它们感受野中的邻域单元获得权重,通过沿着每个维度翻转CNN核来累积来自其领域的投票,并最终输出潜在兴趣目标的投票分数。基于该投票方案,Engelcke等人使用ReLU来生成这些网格的一种新的稀疏3D表示。这个过程在传统的CNN操作中进行迭代和堆叠,最终输出每个提案的预测分数。然而,该投票方案在投票过程中的计算量较高。因此,在目标检测中采用了改进的区域建议网络(RPN)来减少计算量。该RPN由三个Conv层块组成,用于对输入特征图进行下采样、过滤和上采样,生成概率得分图,以及用于目标检测和定位的回归图。
(3)从二维视图进行3D目标检测(定位)
一些方法还会将LiDAR点云投影到二维视图中。这类方法主要由两个步骤组成:①3D点云的投影;②对投影图像的目标检测。将3D点投影到二维图像中的视图生成方案由以下几种:BEV图像、前视图图像、球形投影和圆柱形投影。
与《3D point cloud object detection with multi-view convolutional neural network》不同的是,在《Birdnet: a 3D object detection framework from lidar information》等文中,点云数据被分割成固定大小的网格,然后转换到一个鸟瞰视图(BEV),并带有相应的三个通道,分别编码高度、强度和密度信息。考虑到效率和性能,只将网格中的最大高度、最大强度和归一化密度转换为单个鸟瞰图rgb图。在《Vehicle detection and localization on bird’s eye view elevation images using convolutional neural network》中,只能选择最大值、中值和最小高度值来表示BEV图像的通道,以便在不进行修改的情况下利用传统的2D RGB深度模型。Dewan等人选择了范围、强度和高度值来代表三个通道。在《Pixor: Real-time 3Dobject detection from point clouds》一文中提到每个BEV像素的特征表示由占用率值和反射率值组成。
然而,由于点云的稀疏性,点云向2D图像平面的投影会产生一个稀疏的二维点图。因此,Chen等人添加了前视图表示,以弥补BEV图像中缺失的信息。点云投影到圆柱面,产生密集的前视图图像。为了在投影过程中保持3D空间信息,Pang等人选择在球面上选择视点进行点的多视点投影。他们首先将3D点离散到固定大小的单元中。然后对场景进行采样,生成多视点图像,构建正、负训练样本。这种数据集生成的好处是,可以更好地利用场景的空间关系和特征。然而,该模型对新的场景不具有鲁棒性,也不能从构建的数据集中学习新的特征。
至于2D目标探测器,存在着大量引人注目的深度模型,如VGG-16,更快的R-CNN。在《Deep learning for generic object detection: A survey》一文中,全面总结了对2D探测器在目标探测的调查。
(4)3D目标定位和检测评价
为了比较3D目标定位和检测深度模型,选择了KITTI鸟瞰和目标检测benchmark。所有未被截断或不小于40 px的非遮挡和弱遮挡(<20%)目标都被进行了评估。被截断或被遮挡的目标不被视为假正例。仅行人和自行车至少50%的边界框重叠和汽车70%的边界框重叠被考虑用于检测、定位和方向估计测量。此外,该benchmark测试将任务的难度分为易、中、难三类。
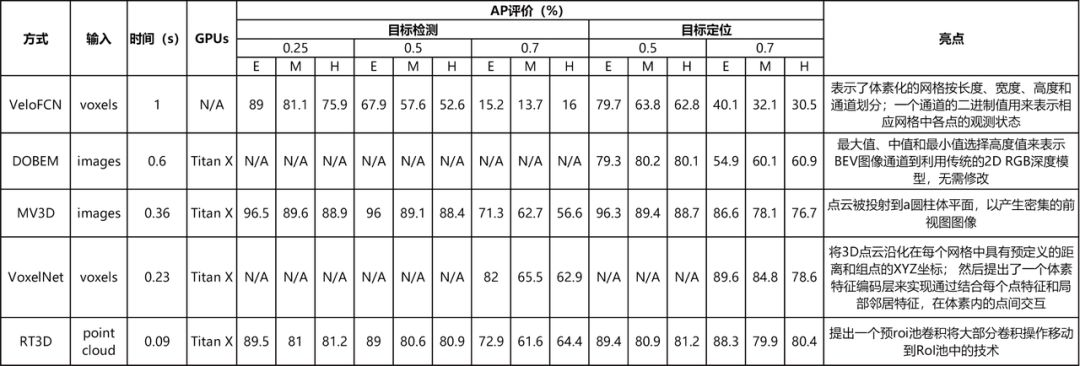
由于实时检测和定位对自动驾驶汽车至关重要,因此比较了这些算法的精度和执行时间。对于定位任务,选择KITTI鸟瞰图基准作为评估基准,比较结果如表5所示。在KITTI3D目标检测基准上对3D检测进行评估。表5显示了验证集上的运行时和平均精度(AP3D)。对于每个边界框重叠,只有超过0.25的3D IoU被认为是一个有效的定位/检测框。
表5 3D汽车定位性能在KITTI benchmark的表现,指标:平均精度(APloc[%])
/ 5.3 3D目标分类 /
在非结构化和不受控制的现实环境中,目标分类(识别)对安全可靠驾驶来说至关重要。现有的3D目标检测主要集中在CAD数据(如ModelNet40)或RGBD数据(如NYUv2)上。与LiDAR点云相比,这些数据具有均匀的点分布、完整的形状、有限的噪声、遮挡和背景杂波,这对3D分类提出了一些挑战。那些应用于CAD数据的深度学习架构已经在Section 3中以四种类型的数据表示的形式进行了分析。在这部分中,我们主要关注基于LiDAR数据的分类任务深度学习模型。
(1)体素体系结构:点云的体素化取决于数据的空间分辨率、方向和原点。体素化能够提供足够的可识别信息,但不会增加计算成本,这对深度学习模型至关重要。因此,对于LiDAR数据,《Voxnet: A 3Dconvolutional neural network for real-time object recognition》中采用空间分辨率为0.1m*0.1m*0.1m的体素对输入点进行体素化。然后通过计算每个体素的二进制占用率网格、密度网格、命中网格来估计其占用率。将输入层、卷积层、池化层和FC层组合起来构建CNNs。该体系结构可以利用数据之间的空间结构,通过池化的方法提取全局特征。但FC层产生了较高的计算成本,且会丢失体素之间的空间信息。在《Orientation-boosted voxel nets for 3d object recognition》一文中,它基于VoxNet,以一个3D体素网格作为输入,并包含两个卷积层和两个FC层。与其他类别级分类任务不同,他们将该任务视为一个多任务问题,其中方向估计和类标签预测是并行处理的。
为了简单和高效,Zhi等人采用了二进制网格降低计算成本。然而,他们只考虑了表面内的体素,而忽略了未知空间和自由空间之间的区别。在《Normalnet: A voxel-based cnn for 3Dobject classification and retrieval》中,包含几何局部位置和方向信息的法向量比二进制网格更强。分类分为两个任务:体素目标类标签预测和方向预测。为了提取局部特征和全局特征,在第一个任务中有两个子任务:第一个子任务是预测引用整个输入形状的目标标签,而第二个子任务是使用部分形状的预测目标标签。该网络提出了方向预测来利用方向增强方案。整个网络由三个3DConv层和两个3D最大池化层组成,是较为轻量级的,且能表现出对遮挡和杂乱的鲁棒性。
(2)多视图架构:基于视图的方法的优点在于它们能够利用点之间的局部和全局空间关系。Luo等人设计了三个特征描述符,从点云中提取局部特征和全局特征:①捕获水平几何结构,②提取垂直信息,③提供完整的空间信息。为了更好地利用多视图数据表示,You等人集成了点云和多视图数据的优点,在3D分类方面取得了比MVCNN更好的效果。此外,他们将基于MVCNN的视图表示中提取的高级特征嵌入注意融合方案,以补偿从点云数据表示中提取的局部特征。这种注意感知特征在3D数据的鉴别信息表示中被证明是有效的。
但不同目标的视图生成过程是不同的,因为目标的特殊属性有助于节省计算和提高精度。例如,在道路标注提取任务中,主要由Z坐标得到的高度对算法的贡献很小。但路面实际上是一个二维结构。因此,Wen等人直接将3D点云投影到水平平面上,并环绕成2D图像。Luo等人将获取的三视图描述符分别输入到JointNet,以捕获低级特征。然后,该网络根据输入的特征,通过卷积运算来学习高级特征,最后融合预测分数。整个框架由五个卷积层,一个空间金字塔池化(SPP)层、两个FC层和一个reshape层组成。输出结果通过Conv层和多视图池化层进行融合。设计良好的视图描述符可以帮助网络在目标分类任务中实现引人注目的结果。
二维深度模型中的另一个代表性架构是编码器-解码器(encoder-decoder)架构,下采样和上采样可以帮助压缩像素之间的信息,提取出最具代表性的特征。在《A deep learning framework for road marking extraction, classification and completion from mobile laser scanning point clouds》的研究中,Wen等人提出了一种改进的U-net模型来对道路标记进行分类。点云数据先被映射到强度图像中。然后利用分层U-net模块,通过CNN进行多尺度聚类,对路标进行分类。由于这种降采样和上采样难以保持细粒度模式,根据背景常识,采用GAN网络重塑小尺寸路标、断车道线和缺失标注。该体系结构利用U-net的效率和GAN的完整性,对道路标记进行了高效、准确的分类。
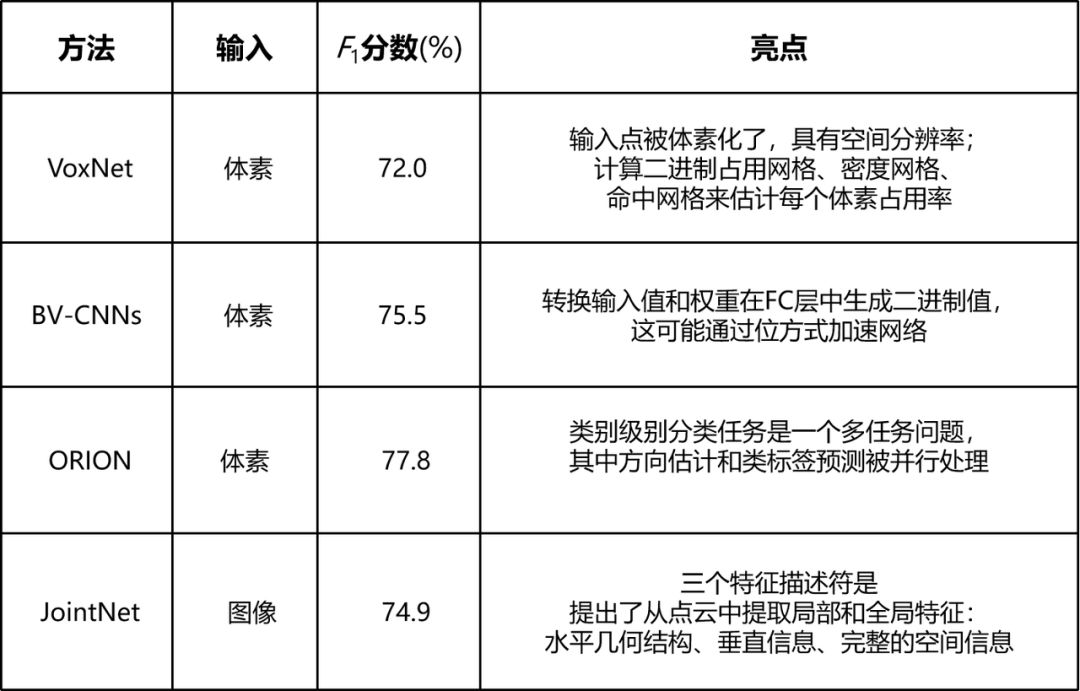
(3)3D目标分类评价:比较有限地发布了特定于3D目标分类任务的LiDAR点云benchmark测试。因此,选择悉尼城市目标数据集是因为几种最先进的方法是可用的。F1评分用于评估这些已发表的算法,如表6所示。
表6在悉尼城市目标数据集上的3D分类性能
Section 6 未来研究方面的挑战与机遇
近五年来,利用LiDAR点云开发的深度学习架构在自动驾驶领域的3D分割、检测和分类任务中取得了重大成功。然而,在最前沿的研究结果和人类水平表现之间仍然存在着巨大的差距。虽然还有很多工作要做,但我们主要总结了深度学习中数据、深层架构和任务的剩余挑战,如下所示:
(1)多源数据融合:为了弥补3D 点云中2D语义、文本和不完整信息的缺失,可以融合图像、LiDAR 点云和雷达数据,为自动驾驶汽车导航和决策提供准确、地理参考和信息丰富的线索此外,低端LiDAR(如Velodane HDL-16E)和高端(Le-HDL-64E)传感器采集的数据也存在融合。然而,融合这些数据存在几个挑战:一是点云的稀疏性会导致融合多源数据时数据不一致和缺失。二是现有的使用深度学习的数据融合方案是在单独的支线中处理,这不是端到端方案。
(2)鲁棒的数据表示:非结构化和无序的数据格式对鲁棒的3D深度学习架构提出了巨大的挑战。虽然有一些有效的数据表示(如体素、点云、视图、2D视图或其他新的数据表示),但目前业内尚未就鲁棒和内存高效的3D数据表示达成一致。例如,虽然体素解决了排序问题,但计算成本随着体素分辨率的增加而呈立方增加。至于点云和图,排列不变性和计算能力限制了点的可处理量,这不可避免地限制了深度模型的性能。
(3)有效和更高效的深度框架:由于嵌入在自动驾驶汽车中的平台形式的内存和计算设施的限制,有效和高效的深度学习架构对于自动化自动驾驶系统的广泛应用至关重要。尽管在3D深度学习模型上有了显著的改进,如PointNet、PointNet++、PointCNN、DGCNN、RotationNet等工作。一些有限的模型可以实现实时分割、检测和分类任务。研究应集中在轻量级和紧凑的架构设计上。
(4)上下文知识提取:由于点云的稀疏性和扫描目标的不完整性,目标的详细上下文信息没有得到充分利用。例如,交通标志中的语义上下文是自动导航的关键线索,但现有的深度学习模型不能完全从点云中提取此类信息,尽管多尺度特征融合方法在上下文信息提取方面取得了显著的改进。此外,GAN也可以提高3D点云的完整性。但这些框架并不能以端到端训练的方式解决上下文信息提取的稀疏性和不完整性问题。
(5)多任务学习:LiDAR点云相关方法包括多个任务,如场景分割、目标检测(如汽车、行人、交通灯等)以及分类(如道路标记、交通标志)。所有这些结果通常被融合在一起,并报告给最终控制的决策系统。然而,很少有深度学习体系结构将多个LiDAR点云任务结合在一起的。因此,它们之间的固有信息没有被充分利用,也没有用较少的计算来概括更好的模型。
(6)弱监督/无监督学习:现有的最先进的深度学习模型通常是在监督模式下使用带有3D目标边界框或每点分割掩膜的标注数据来构建的。然而,对于完全监督的模型也有一些局限性。首先是高质量、大规模和庞大的通用目标数据集和benchmark的可用性有限。其次是完全监督模型的泛化能力,它对看不见或未训练的目标没有鲁棒性。在此基础上,弱监督或无监督学习应被开发,用于以提高模型的泛化性,解决数据缺失问题。
★ 结论 ★
本文系统地回顾了使用LiDAR点云在自动驾驶领域的最先进的深度学习架构,如分割、检测和分类。对里程碑式3D深度学习模型和3D深度学习应用进行了总结和评价,并比较了优缺点。列出了研究挑战和机遇,以推进深度学习在自动驾驶领域的潜在发展。
i车Gear联
一群致力于推动汽车智能网联化发展进程的工程师,一群投身于汽车产业数字化变革的小年轻,一个以数据处理和AI技术为汽车研发行业服务的团队,将日常所见、所想、所感分享于此,一起笑看风云起。