使用复合索引
如果经常执行如上查询,那么建立三个单独索引不如建立一个复合索引,因为三个单独索引通常数据库每次执行只能使用其中一个,虽然这样比不使用索引而进行全表扫描提高了很多效率,但使用复合索引因为索引本身就对应到三个字段上的,效率会有更大提升。
那么为什么数据库只支持一条查询语句只使用一个索引?简单的讲是因为N个独立索引同时在一条语句使用的效果比只使用一个索引还要慢,开销太大。
在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
同时,复合索引的也是有生效原则的,其原则是从前往后依次使用则生效,如果中间某个索引没有使用,那么“断点”前面的索引生效,断点后面的索引不生效,造成“断点”的原因一般有:
- 前边的任意一个索引没有参与查询,后面的不生效。
- 前边的任意一个索引失效,当前索引及后面的不生效。
- 前边的任意一个索引字段参与的是范围查询,后面的不生效。
引发索引失效,导致全表扫描的原因有:
- 索引列进行计算、函数、类型转换等操作。
- 索引列使用不等于,如!= 或<>。
- 索引列使用 IS NULL ,IS NOT NULL。
- 模糊查询LIKE 以通配符开头如,%ab。
- 索引列使用使用 OR 来连接条件。
- 索引列使用IN 和 NOT IN 。
- 类型错误,如字段NUM类型为varchar,WHERE条件用number,NUM = 1。
- WHERE子句和ORDER BY使用相同的索引,并且ORDER BY的顺序和索引顺序相同,并且ORDER BY的字段都是升序或者降序,否则不会使用索引。
- 复合索引不符合最佳左前缀原则或存在断点。
- 如果MYSQL评估使用索引比全表扫描更慢,则不使用索引。
例如我们建立了一个这样复合索引key index (col1,col2,col3),那么其实相当于创建了(col1),(col1,col2),(col1,col2,col3)三个索引,即最佳左前缀特性。

索引失效的优化技巧
应尽量避免在 WHERE 子句中使用 != 或 <> 操作符,否则将导致引擎放弃使用索引而进行全表扫描。MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些方式的LIKE('a%'),如下。

WHERE 子句中使用 LIKE进行模糊查询时,在关键词前加通配符或者前后都加通配号都无法使用索引,从而引发全表扫描。解决LIKE '%abc%' 时索引不被使用的方法就是添加覆盖索引(只访问索引的查询,索引和查询列一致,只需扫描索引而无须回表),如下。

应尽量避免在 WHERE 子句中对字段进行 NULL 值判断,否则将导致引擎放弃使用索引而进行全表扫描,创建表时NULL是默认值,但大多数时候应该使用NOT NULL,或者使用一个默认值,如 0 作为默认值。
例如,性别,使用1表示男,2表示女,0表示未知或者是用户没有选择,默认值设置为 0,因为大部分编程语言的数字类型的默认值0,如下。

空值和NULL是有区别的,以一个杯子为例:
- 空值代表杯子是真空的。
- NULL代表杯子中装满了空气。
如果字段允许为空,可能会有以下问题:
- 查询条件就必须处理为空的情况,否则会出现一些很奇怪的问题,比如NOT IN、!= 等负向条件查询在有 NULL 值的情况下返回始终为空结果,查询易出错。
- 在部分数据库中会导致索引失效。
- 可空列需要更多的存储空间,导致空间变大,增加数据库系统查询分析复杂度。
- 在程序中可能需要每次都判断是否为空,增加程序复杂复杂度。
但凡事没有绝对的,使用默认值的思路可以解决很大一部分可为空的问题,但不是所有都需这样做,具体还是要根据具体业务进行分析。
应尽量避免在 WHERE 子句中使用 OR 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描。使用 OR 的字句可以分解成多个查询,并且通过UNION 连接多个查询。他们的速度只同是否使用索引有关,如果查询需要用到联合索引,用UNION ALL执行的效率更高,如下。

应尽量避免在 WHERE 子句中使用 IN 和 NOT IN ,否则将导致全表扫描,对于连续的数值,能用 BETWEEN AND 尽量避免使用 IN。一般,用 EXISTS 代替 IN 。若需要使用 IN,在 IN 后面值的列表中,按照值的分布数量降序排列,减少判断的次数。
使用BETWEEN AND 替换 IN ,如下。

使用EXISTS 替代IN,用NOT EXISTS 替代 NOT IN,无论在哪种情况下, NOT IN效率都是最低的,如下。

使用LEFT JOIN 替换 IN,如下。

如上,我们使用了如下方式优化了IN 和 NOT IN:
- 使用between 替换 in ( 如果 in 的条件是连续的)
- 使用exists替代in、用not exists替代 not in
- 使用left join 替换 in
应尽量避免在 WHERE 子句中对 “=” 左边的字段进行函数、算术运算及其他表达式运算,可以将表达式运算移至“=”右边,否则将导致引擎放弃使用索引而进行全表扫描,如下。


如果在 WHERE 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时。它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项,可以改为强制查询使用索引,如下。

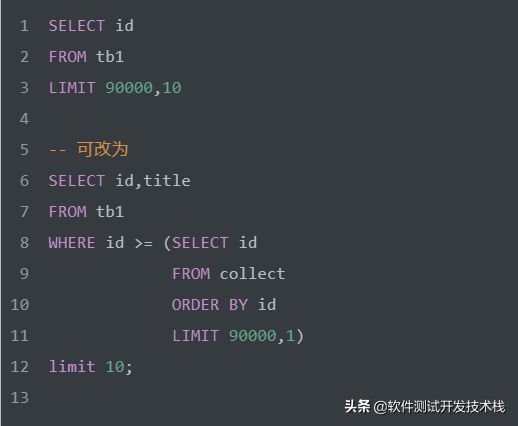
LIMIT 分页优化
在分页查询偏移量特别大时,LIMIT 效率会相当低,如下。
数据删除优化
存在如下表,n_id是主键,id_card是人员编码,数字类型,表中id_card有重复,已经建了id_card索引,如下。

用EXISTS替换DISTINCT
EXISTS语句用来判断括号内的表达式是否存在返回值,如果存在就返回真,如果不存在就返回假,同时它只要括号中的表达式有一个值存在,就立刻返回真,而不需要遍历表中所有的数据,正是因此 EXISTS 使查询效率更高,如下。

