目录
- 什么是DSL
- vue中的DSL
- 实现思路
什么是DSL
DSL是领域特定语言的缩写,与JavaScript这种通用语言编译器相对,它只针对某一个特殊应用场景工作
类似中英翻译,它将源代码翻译为目标代码,其转换的标准流程过程包括:词法分析、语法分析、语义分析、中间代码生成、优化、目标代码生成等,此外,前述流程并非是严格必须的
vue中的DSL
- 词法+语法+语义分析
- 生成token流
- 生成模板ast
- 将ast转化为js ast
- 将ast转化为render函数
| const code = `` | |
| const tokens = tokenize(code) // 词法+语法+语义分析,生成token流 | |
| const tAst = parse(tokens) // 生成ast | |
| const jsAst = transform(tAst) // 将ast转化为jsAst | |
| const renderCode = generate(jsAst) // 将jsAst转化为render函数 |
实现思路
- ast结构定义
首先我们要明确要生成的ast结构是什么样的,比如如下的模板,div和h1怎么表示,开标签中的属性怎么区分,标签的内容放在那里等等
| <div> | |
| <h1 v-if="show">我爱前端</h1> | |
| <div> |
我们约定:ast是一个树形结构,每一个节点对应一个html元素,该节点使用ts定义如下:
| interface AstNode{ | |
| // 元素类型,是html原生还是vue自定义 | |
| type:string; | |
| // 元素名称,是div还是h1 | |
| tag:string; | |
| // 子节点,h1是div的子节点 | |
| children:AstNode[]; | |
| // 开标签属性内容 | |
| props:{ | |
| type:string; | |
| name?:string; | |
| exp?:{ | |
| ... | |
| } | |
| ... | |
| }[]; | |
| } |
- 词法、语法、语义分析
在工程化中,webpack或vite会帮我们把用户侧的源代码拉取过来,我们使用node的readFileSync来代替这一行为
| const fs = require('node:fs') | |
| const code = fs.readFileSync('./vue.txt','utf-8') |
有了源代码,接下来要考虑的就是如何对源码进行切分,这需要使用到有限状态机,即伴随着源码的不断输入,解析器能够自动的在不同的状态间进行迁移的过程,而有限则意味着状态的种类是可枚举完的
1-模拟源码不断输入
使用while+substring每次删除一个字符可以模拟字符的输入
| function parse(code){ | |
| while(code.length){ | |
| code = code.substring(1) | |
| } | |
| } |
2-状态迁移
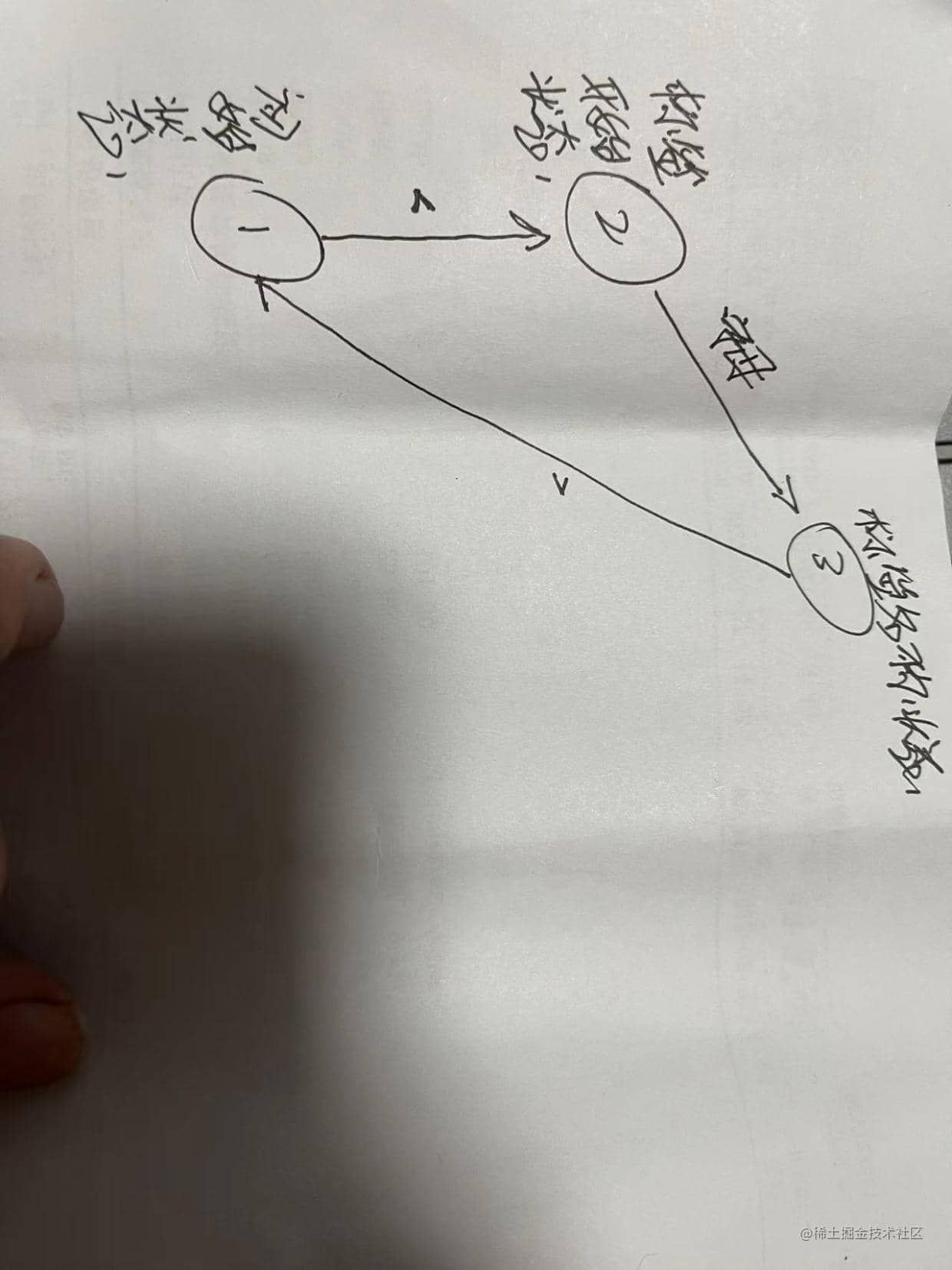
我们根据html标签的书写规则来定义状态迁移的条件,当遇到<时,将状态从开始状态标记为标签开始;伴随着while循环的执行,首次遇到非空字符时,从标签开始状态切换为标签名称状态;当遇到>时,再从标签名称状态切换为标签初始状态。至此形成一个闭环,我们在这一个闭环内记录下的状态集合则称之为一个token,如图所示
3-代码实现
3.1 定义状态机的状态
| const State = { | |
| // 初始 | |
| initial:1, | |
| // 标签开始 | |
| start:2, | |
| // 标签名称 | |
| startName:3, | |
| // 标签文本 | |
| text:4, | |
| // 标签结束 | |
| end:5, | |
| // 标签结束名称 | |
| endName:6 | |
| } |
3.2 编写辅助函数,判断是否是字符
| const isAlpha = function(char){ | |
| return /[a-zA-Z1-6]/.test(char) | |
| } |
3.3 实现tokenize函数
通过while循环依次取得每一个字符,当遇到规则字符(如<或/或>)时,根据当前所处的状态进行状态迁移,当迁移回初始状态时记录一个token
| function tokenize(code){ | |
| let currentState = State.initial | |
| const tokens = [] | |
| const chars = [] | |
| while(code.length){ | |
| const act = code[0] | |
| switch(currentState){ | |
| case State.initial: | |
| if(act === '<'){ | |
| currentState = State.start | |
| }else if(isAlpha(act)){ | |
| currentState = State.text | |
| chars.push(act) | |
| } | |
| break | |
| case State.start: | |
| if(isAlpha(act)){ | |
| currentState = State.startName | |
| chars.push(act) | |
| }else if(act === '/'){ | |
| currentState = State.end | |
| } | |
| break | |
| case State.startName: | |
| if(isAlpha(act)){ | |
| chars.push(act) | |
| }else if(act === '>'){ | |
| // 切到初始状态,形式闭环,记录token | |
| currentState = State.initial | |
| tokens.push({ | |
| type:'tag', | |
| name:chars.join('') | |
| }) | |
| chars.length = 0 | |
| } | |
| break | |
| case State.text: | |
| /** | |
| * 1.<div></div> act = i | |
| * 2.<div>我爱前端</div> act = 爱 | |
| */ | |
| if(isAlpha(act)){ | |
| chars.push(act) | |
| }else if(act === '<'){ | |
| currentState = State.start | |
| tokens.push({ | |
| type:'text', | |
| content:chars.join('') | |
| }) | |
| chars.length = 0 | |
| } | |
| break | |
| case State.end: | |
| // 当遇到/才会切换到结束标签状态 | |
| if(isAlpha(act)){ | |
| currentState = State.endName | |
| chars.push(act) | |
| } | |
| break | |
| case State.endName: | |
| if(isAlpha(act)){ | |
| chars.push(act) | |
| }else if(act === '>'){ | |
| currentState = State.initial | |
| tokens.push({ | |
| type:'tagEnd', | |
| name:chars.join('') | |
| }) | |
| chars.length = 0 | |
| } | |
| break | |
| } | |
| code = code.substring(1) | |
| } | |
| return tokens | |
| } |
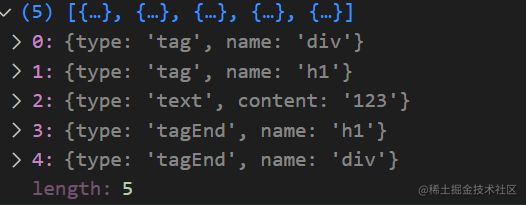
运行结果如下:
- 生成tAst
由于vue是在js下实现的编译器,并不会创造新的运算符号,所以并不需要进行递归下降才能实现ast,我们只需要对上一步生成的tokens进行遍历扫描即可
1-如何扫描
观察我们生成的tokens,最先开始的div标签,最后结束,同时,后进入的h1标签是div标签的子节点
因此,我们需要初始化一个栈,当遇到type为tag的标签时向栈顶压入一个ast节点,并将其作为前一个栈顶节点的子节点,当遇到type为tagEnd时则从栈顶弹出,标识一次标签的完整匹配
2-代码实现
2.1 初始化虚拟根节点
由于树形结构必存在根节点,而html则是多根的,因此我们在代码里初始化一个根
| const root = { | |
| type:'Root', | |
| children:[] | |
| } | |
| 复制代码 |
2.2 初始化栈
将虚拟根作为默认的栈顶,这样在扫描实际的tokens时,就能默认作为其子节点了
| const stack = [root] | |
| 复制代码 |
2.3 创建节点
| class Node{ | |
| constructor(type,tag){ | |
| this.type = type | |
| this.tag = tag | |
| this.children = [] | |
| } | |
| setContent(content){ | |
| this.content = content | |
| } | |
| } | |
| 复制代码 |
2.4 扫描
依次从tokens中取出,并判断其type类型,如果是tag则作为子节点向原栈顶追加,如果是tagEnd则从栈顶弹出
| while(tokens.length){ | |
| const p = stack[stack.length - 1] | |
| const act = tokens.shift() | |
| switch(act.type){ | |
| case 'tag':{ | |
| const e = new Node('Element',act.name) | |
| p.children.push(e) | |
| stack.push(e) | |
| break | |
| } | |
| case 'text':{ | |
| const e = new Node('text') | |
| e.setContent(act.content) | |
| p.children.push(e) | |
| break | |
| } | |
| case 'tagEnd':{ | |
| stack.pop() | |
| } | |
| } | |
| } |
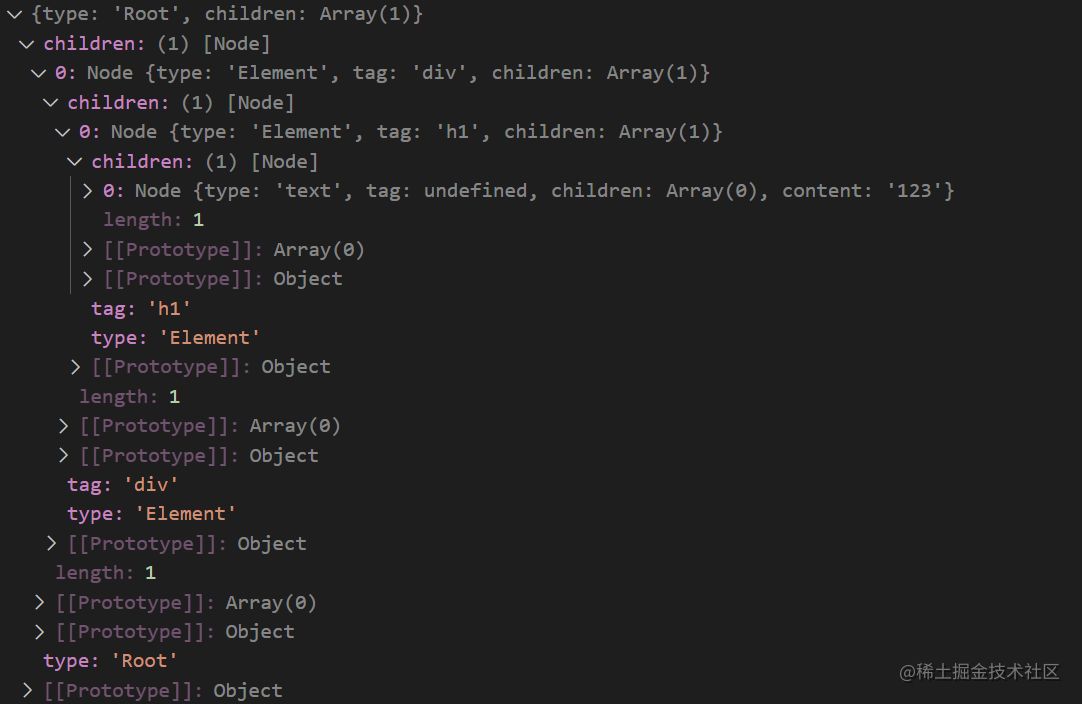
2.5 生成的ast如下
- transform
现在,我们已经完成了模板的ast化,接下来就是考虑如何将这个模板的ast转化为js ast,这一过程我们称之为transform,它定义了对ast节点操作的一系列方法
1-节点的访问
节点操作的前提一定是先拿到这个节点,因此我们需要能够遍历到树中的每一个节点
1.1 深度优先遍历
| function transform(tAst){ | |
| const children = tAst.children | |
| if(Array.isArray(children)){ | |
| for(let i=0;i<children.length;i++){ | |
| transform(children[i]) | |
| } | |
| } | |
| } |
1.2 定义访问操作
如果将访问操作的代码内置到transform当中,则该函数一定会又臭又长,且不易后续扩展,因此我们需要将该操作进行提取,ast的访问应该算是访问者模式的典型应用,不过为了保持和vue一致,咱们也采用函数回调的方式来实现
| function transform(tAst,ctx){ | |
| const act = tAst | |
| const transforms = ctx.nodeTransforms | |
| for(let i=0;i<transforms;i++){ | |
| if(typeof transforms[i] === 'function'){ | |
| transforms[i](act,ctx) | |
| } | |
| } | |
| ...... | |
| } |
2-扩展ctx
在进行节点操作之前,我们还需要动态的给ctx挂载一些状态信息,用以标记当前transform的运行状态,比如当前运行的是哪一颗节点树、当前的节点树的父节点是谁、当前节点的兄弟节点是谁以及当前节点树是父节点的第几个子节点
| function transform(tAst,ctx){ | |
| // 当前的节点树 | |
| ctx.act = tAst | |
| const transforms = ctx.nodeTransforms | |
| for(let i=0;i<transforms.length;i++){ | |
| if(typeof transforms[i] === 'function'){ | |
| transforms[i](ctx.act,ctx) | |
| } | |
| } | |
| const children = ctx.act.children | |
| if(Array.isArray(children)){ | |
| // 当前节点的父节点 | |
| ctx.parent = ctx.act | |
| for(let i=0;i<children.length;i++){ | |
| // 当前节点树是父节点的第几个子节点 | |
| ctx.index = i | |
| // 当前节点的兄弟节点 | |
| ctx.siblings = [arr[i-1],arr[i+1]].map(v=>v||null) | |
| transform(children[i],ctx) | |
| } | |
| } | |
| } |
3-节点替换
至此,我们的transform的主框架就搭好了,要实现节点替换就只需要在nodeTransforms中增加处理函数即可,比如我们将h1标签替换为p标签
| function _replaceNode(newNode){ | |
| this.act = newNode | |
| this.parent.children[this.index] = newNode | |
| } | |
| function transformElement(node,ctx){ | |
| if(node.type === 'Element'){ | |
| switch(node.tag){ | |
| case 'h1': | |
| _replaceNode.call(ctx,{ | |
| type:'Element', | |
| tag:'p', | |
| children:node.children | |
| }) | |
| break | |
| } | |
| } | |
| } |
4-等待子节点处理完毕
目前的实现中,在对当前节点进行处理时,其子节点一定还未被处理,但在实际需求中,往往需要等子节点处理完毕后再根据其执行结果决定如何处理当前节点,因此需要对transform进行改进
我们为nodeTransforms设计一个返回值,该值是一个函数,当正向访问结束后,使用该返回函数做反向遍历即可
| function transform(tAst,ctx){ | |
| // 退出回调列表 | |
| const cbs = [] | |
| ... | |
| const cb = transforms[i](ctx.act,ctx) | |
| if(typeof cb === 'function'){ | |
| cbs.push(cb) | |
| } | |
| ... | |
| // 退出 | |
| let i = cbs.length | |
| while(i--){ | |
| cbs[i]() | |
| } | |
| } |
5-生成js ast
由于我们最终的产物是一个render函数,因此需要将模板ast转换为js ast,以前文的模板为例
| <div> | |
| <h1>123</h1> | |
| </div> |
其对应的render函数如下
| function render(){ | |
| return h('div',h('h1','123')) | |
| } |
5.1 ast节点类型
在模板的ast节点定义时,我们把一个元素节点视为一个ast节点,而在JavaScript中,则为一条js语句等同于一个ast节点
观察render函数的js代码,不难发现,其由函数定义、函数参数和函数返回值三部分构成,同样的,我们使用type来标记其类型
另外,我们的目标代码是明确的,并非所有的js语句,因此,我们可以定义任何的type名称来做专属标识,比如我就想使用Function来表示render函数,使用ReturenCb来表示h函数......
本文,使用FunctionDecl+id.name标识render函数;params标识render函数的参数;body标识render函数的函数体,由于函数体内又可能存在多个js语句,因此它被设计为一个数组,最后使用ReturnStatement标识return语句,其返回的是一个h函数,而参数使用arguments标记
| { | |
| type:'FunctionDecl', | |
| id:{ | |
| type:"Identifier", | |
| name:"render" | |
| }, | |
| params:[], | |
| body:[ | |
| { | |
| type:"ReturnStatement", | |
| return:{ | |
| type:"CallExpression", | |
| callee:{ | |
| type:"Identifier", | |
| name:"h" | |
| }, | |
| arguments:[ | |
| { | |
| type:"StringLiteral", | |
| value:"div" | |
| }, | |
| { | |
| type:"ArrayExpression", | |
| elements:[ | |
| //CallExpression类型, | |
| //CallExpression类型, | |
| ] | |
| } | |
| ] | |
| } | |
| } | |
| ] | |
| } |
5.2 定义类型生成器
编写一个newType函数用于统一处理各种节点类型的生成
| function _newType(type,value,arguments){ | |
| const o = { | |
| type, | |
| } | |
| switch(type){ | |
| case 'StringLiteral': | |
| o.value = value | |
| break | |
| case 'Identifier': | |
| o.name = value | |
| break | |
| case 'ArrayExpression': | |
| o.elements = value | |
| break | |
| case 'CallExpression': | |
| o.callee = _newType('Identifier',value) | |
| o.arguments = arguments | |
| break | |
| } | |
| return o | |
| } |
5.3 为tAst添加jsCode属性收集当前节点的转换结果
5.4 重新实现transformElement函数
对当前语句的处理必须等到子节点转换完毕,因为只有此时jscode才是可用的
| function transformElement(node,ctx){ | |
| return ()=>{ | |
| if(node.type === 'Element'){ | |
| } | |
| } | |
| } |
从5.1的节点类型定义可以知道,每一个节点本质上都是一个h函数
| const callee = _newType('CallExpression','h',[ | |
| _newType('StringLiteral',node.tag) | |
| // 参数二取决于子节点的数量,需要动态生成 | |
| ]) |
生成参数二
| node.children.length === 1 | |
| ? callee.arguments.push(node.children[0].jsCode) | |
| : callee.arguments.push(node.children.map(v=>v.jsCode)) |
最后将当前节点的转换结果挂载到jsCode
node.jsCode = callee
5.5 新增transformRoot函数
至此,我们已经完成了对实际模板节点的转化,即
将
| <div> | |
| <h1>123</h1> | |
| </div> |
转为了
| h('div',[ | |
| h('h1','123') | |
| ]) |
因此我们还需要处理生成render函数,而这正好与我们在一开始生成的虚拟根节点相对应
| function transformRoot(node){ | |
| return ()=>{ | |
| if(node.type === 'Root'){ | |
| node.jsCode = { | |
| type:"FunctionDecl", | |
| id:_newType("Identifier","render"), | |
| params:[], | |
| body:[ | |
| { | |
| type:"ReturnStatement", | |
| return:node.children[0].jsCode | |
| } | |
| ] | |
| } | |
| } | |
| } | |
| } |
6-转换结果如下
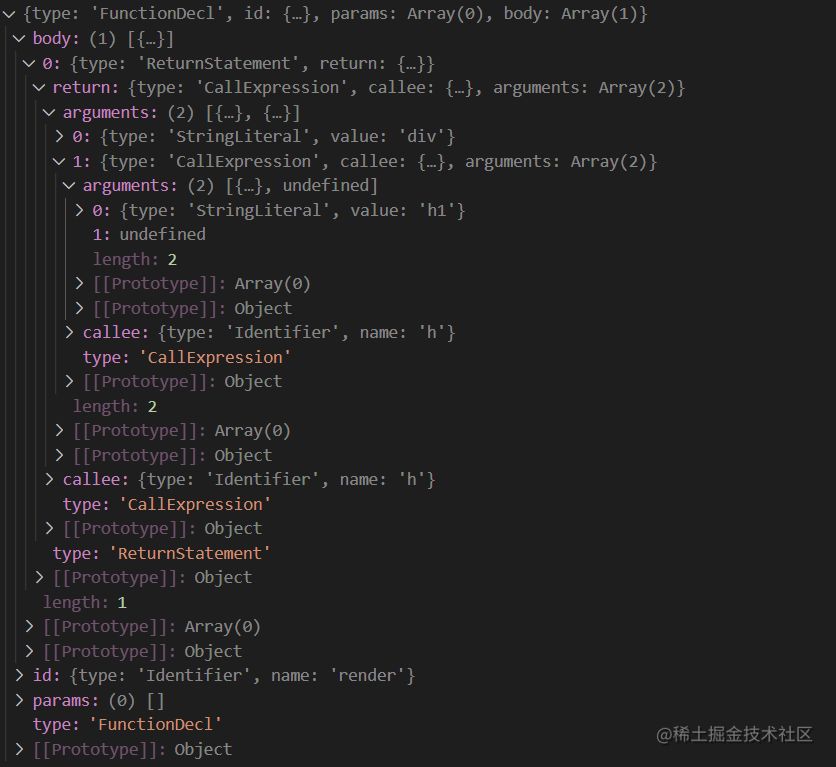
- 生成目标代码
我们在前一部分已经为根节点添加了jsCode属性,该属性就是tAst所对应的jsAst,因此我们只需要找到每一个节点并将他们转化成字符串进行拼接就可以了
1-定义上下文
我们说了,代码生成本质上是在做字符串的拼接工作,为此我们将拼接时出现频率较大的函数定义在上下文中以方便复用,其中的code就是我们最终生成的代码的容器,而newLine则更多是为了生成代码的可读性
| const ctx = { | |
| code: "", | |
| append(code) { | |
| this.code += code; | |
| }, | |
| newLine(indent = 1) { | |
| this.code += "\n" + " ".repeat(indent * 2); | |
| }, | |
| }; |
2-定义类型生成函数
2.1 首先我们将每一种js节点类型所对应的生成函数放到一个统一的genMap中
| const genMap = new Map([ | |
| ['FunctionDecl',genFunctionDecl], | |
| ['ReturnStatement',genReturnStatement], | |
| ['StringLiteral',genStringLiteral], | |
| ['CallExpression',genCallExpression], | |
| ['ArrayExpression',genArrayExpression] | |
| ]) |
2.2 对参数的遍历生成单独做一个genParams
| function genParams(nodes,ctx) { | |
| nodes.forEach((v,i)=>{ | |
| genMap.get(v.type)(v,ctx) | |
| if(i<nodes.length-1){ | |
| ctx.append(',') | |
| } | |
| }) | |
| } |
2.3 分别实现
分别对函数名称、函数参数、函数体做生成,他们都在节点中有着一一对应的节点属性
2.3.1 genFunctionDecl
代码实现
| function genFunctionDecl(node, ctx) { | |
| ctx.append(`function ${node.id.name}(`); | |
| genParams(node.params, ctx); | |
| ctx.append("){"); | |
| ctx.newLine(); | |
| node.body.forEach((v) => genMap.get(v.type)(v, ctx)); | |
| ctx.newLine(0) | |
| ctx.append('}') | |
| } |
生成结果
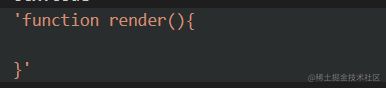
2.3.2 genReturnStatement
该函数就是为code拼接return字符,至于真正的函数体,是由genCallExpression完成的
代码实现
| function genReturnStatement(node,ctx) { | |
| ctx.append('return ') | |
| genMap.get(node.return.type)(node.return,ctx) | |
| } |
生成结果
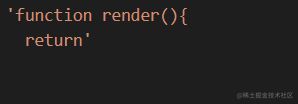
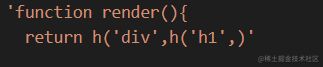
2.3.3 genCallExpression
代码实现
| function genCallExpression(node,ctx) { | |
| ctx.append(`${node.callee.name}(`) | |
| genParams(node.arguments,ctx) | |
| ctx.append(')') | |
| } |
生成结果
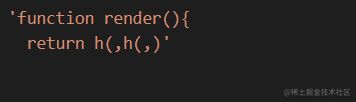
2.3.4 genStringLiteral
代码实现
| function genStringLiteral(node,ctx) { | |
| ctx.append(`'${node.value}'`) | |
| } |
生成结果
2.3.5 genArrayExpression
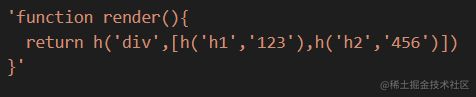
目前在我们的示例中是不存在该类型的,因此我们将模板源码做下调整
| <div> | |
| <h1>123</h1> | |
| <h2>456</h2> | |
| </div> |
代码实现
| function genArrayExpression(node,ctx) { | |
| ctx.append('[') | |
| genParams(node.elements,ctx) | |
| ctx.append(']') | |
| } |
生成结果

3-最终的完整生成结果